Hyperloglog Tutorial: Cardinality Stats in Solr 5.2
Following in the footsteps of the percentile support added to Solr’s StatsComponent in 5.1, Solr 5.2 will add efficient set cardinality using the HyperLogLog algorithm.
Basic Usage
Like most of the existing stat component options, cardinality of a field (or function values) can be requested using a simple local param option with a true value. For example…
$ curl 'http://localhost:8983/solr/techproducts/query?rows=0&q=*:*&stats=true&stats.field=%7B!count=true+cardinality=true%7Dmanu_id_s'
{
"responseHeader":{
"status":0,
"QTime":3,
"params":{
"stats.field":"{!count=true cardinality=true}manu_id_s",
"stats":"true",
"q":"*:*",
"rows":"0"}},
"response":{"numFound":32,"start":0,"docs":[]
},
"stats":{
"stats_fields":{
"manu_id_s":{
"count":18,
"cardinality":14}}}}
Here we see that in the techproduct sample data, the 32 (numFound) documents contain 18 (count) total values in the manu_id_s field — and of those 14 (cardinality) are unique.
And of course, like all stats, this can be combined with pivot facets to find things like the number of unique manufacturers per category…
$ curl 'http://localhost:8983/solr/techproducts/query?rows=0&q=*:*&facet=true&stats=true&facet.pivot=%7B!stats=s%7Dcat&stats.field=%7B!tag=s+cardinality=true%7Dmanu_id_s'
{
"responseHeader":{
"status":0,
"QTime":4,
"params":{
"facet":"true",
"stats.field":"{!tag=s cardinality=true}manu_id_s",
"stats":"true",
"q":"*:*",
"facet.pivot":"{!stats=s}cat",
"rows":"0"}},
"response":{"numFound":32,"start":0,"docs":[]
},
"facet_counts":{
"facet_queries":{},
"facet_fields":{},
"facet_dates":{},
"facet_ranges":{},
"facet_intervals":{},
"facet_heatmaps":{},
"facet_pivot":{
"cat":[{
"field":"cat",
"value":"electronics",
"count":12,
"stats":{
"stats_fields":{
"manu_id_s":{
"cardinality":8}}}},
{
"field":"cat",
"value":"currency",
"count":4,
"stats":{
"stats_fields":{
"manu_id_s":{
"cardinality":4}}}},
{
"field":"cat",
"value":"memory",
"count":3,
"stats":{
"stats_fields":{
"manu_id_s":{
"cardinality":1}}}},
{
"field":"cat",
"value":"connector",
"count":2,
"stats":{
"stats_fields":{
"manu_id_s":{
"cardinality":1}}}},
...
cardinality=true vs countDistinct=true
Astute readers may ask: “Hasn’t Solr always supported cardinality using the stats.calcdistinct=true option?” The answer to that question is: sort of.
The calcdistinct option has never been recommended for anything other then trivial use cases because it used a very naive implementation of computing set cardinality — namely: it built in memory (and returned to the client) a full set of all the distinctValues. This performs fine for small sets, but as the cardinality increases, it becomes trivial to crash a server with an OutOfMemoryError with only a handful of concurrent users. In a distributed search, the behavior is even worse (and much slower) since all of those full sets on each shard must be sent over the wire to the coordinating node to be merged.
Solr 5.2 improves things slightly by splitting the calcdistinct=true option in two and letting clients request countDistinct=true independently from the set of all distinctValues=true. Under the covers Solr is still doing the same amount of work (and in distributed requests, the nodes are still exchanging the same amount of data) but asking only for countDistinct=true spares the clients from having to receive the full set of all values.
How the new cardinality option differs, is that it uses probabilistic “HyperLogLog” (HLL) algorithm to estimate the cardinality of the sets in a fixed amount of memory. Wikipedia explains the details far better then I could, but the key points Solr users should be aware of are:
- RAM Usage is always limited to an upper bound
- Values are hashed
- For “small” sets, the implementation and results should be exactly the same as using
countDistinct=true(assuming no hash collisions) - For “larger” sets, the trade off between “accuracy” and the upper bound on RAM is tunable per request
The examples we’ve seen so far used cardinality=true as a local param — this is actually just syntactic sugar for cardinality=0.33. Any number between 0.0 and 1.0 (inclusively) can be specified to indicate how the user would like to trade off RAM vs accuracy:
cardinality=0.0— “Use the minimum amount of ram supported to give me a very rough approximate value”cardinality=1.0— “Use the maximum amount of ram supported to give me the most accurate approximate value possible”
Internally these floating point values, along with some basic heuristics about the Solr field type (ie: 32bit field types like int and float have a much smaller max-possible cardinality then fields like long, double, strings, etc…) are used to tune the “log2m” and “regwidth” options of the underlying java-hll implementation. Advanced Solr users can provide explicit values for these options using the hllLog2m and hllRegwidth localparams, see the
StatsComponent documentation for more details.
Accuracy versus Performance: Comparison Testing
To help showcase the trade offs between using the old countDistinct logic, and the new HLL based cardinality option, I setup a simple benchmark to help compare them.
The initial setup is fairly straight forward:
- Use
bin/solr -e cloud -nopromptto setup a 2 node cluster containing 1 collection with 2 shards and 2 replicas - Generated 10,000,000 random documents, each containing 2 fields:
long_data_ls: A multivalued numeric field containing 3 random “long” valuesstring_data_ss: A multivalued string field containing the same 3 values (as strings)
- Generate 500 random range queries against the “id” field, such that the first query matches 1000 documents, and each successive query matches an additional 1000 documents
Note that because we generated 3 random values in each field for each documents, we expect the cardinality results of each query to be ~3x the number of documents matched by that query. (Some minor variations may exist if multiple documents just so happened to contain the same randomly generated field values).
With this pre-built index, and this set of pre-generated random queries, we can then execute the query set
over and over again with different options to compute the cardinality. Specifically, for both of our test fields, the following stats.field variants were tested:
{!key=k countDistinct=true}{!key=k cardinality=true}(the same as 0.33){!key=k cardinality=0.5}{!key=k cardinality=0.7}
For each field, and each stats.field, 3 runs of the full query set were executed sequentially using a single client thread, and both the resulting cardinality as well as the mean+stddev of the response time (as observed by the client) were recorded.
Test Results
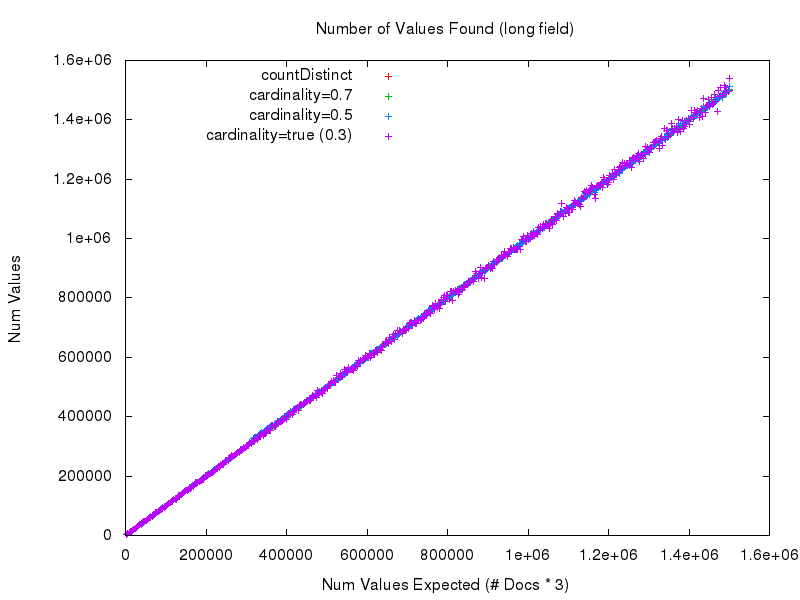
Looking at graphs of the raw numbers returned by each approach isn’t very helpful, it basically just looks like a perfectly straight line with a slope of 1 — which is good. A Straight line means we got the answers we expect.
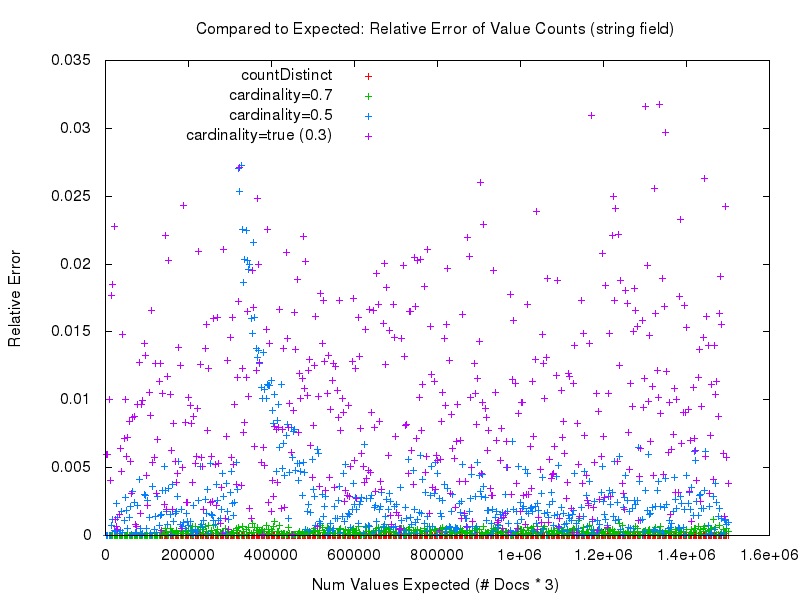
But the devil is in the details. What we really need to look at in order to meaningfully compare the measured accuracy of the different approaches is the “relative error“. As we can see in this graph below, the most accurate results clearly come from using countDistinct=true. After that cardinality=0.7 is a very close second, and the measured accuracy gets worse as the tuning value for the cardinality option gets lower.
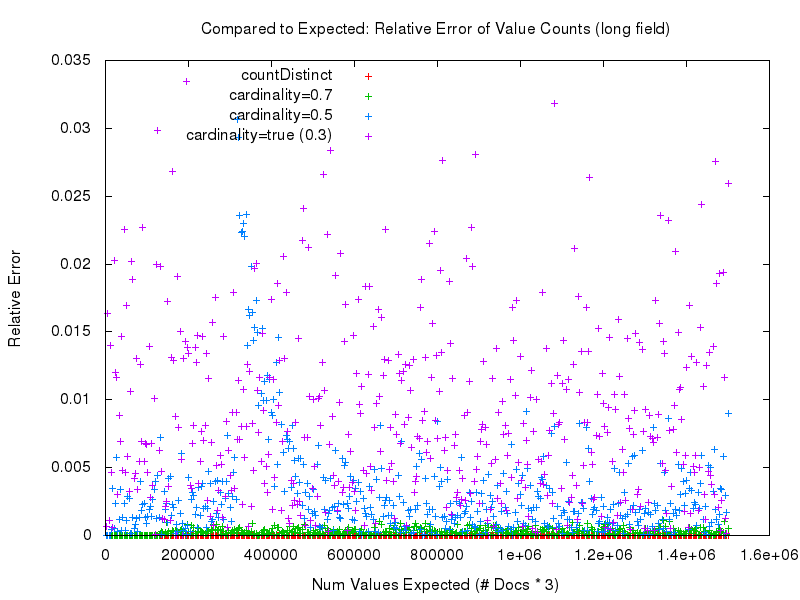
Looking at these results, you may wonder: Why bother using the new cardinality option at all?
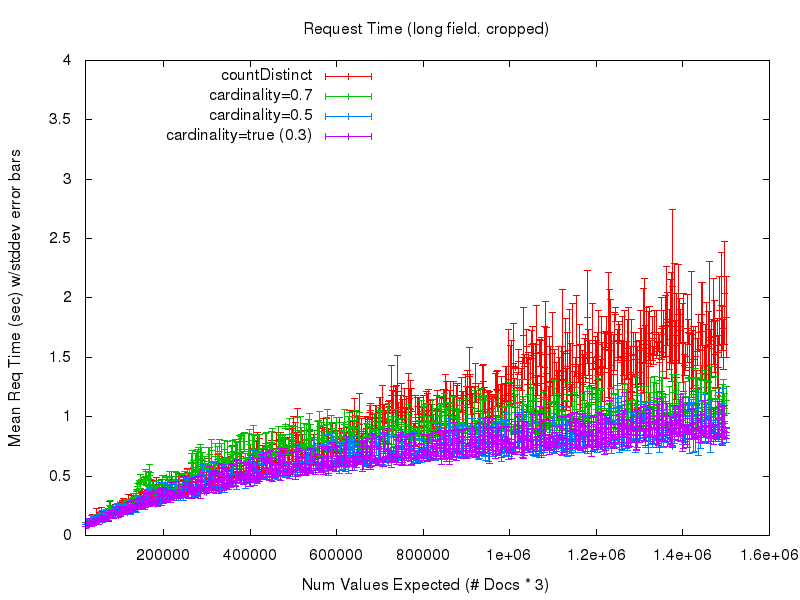
To answer that question, let’s look at the next 2 graphs. The first shows the mean request time (as measured from the query client) as the number of values expected in the set grows. There is a lot of noise in this graph at the low values due to poor warming queries on my part in the testing process — so the second graph shows a cropped view of the same data
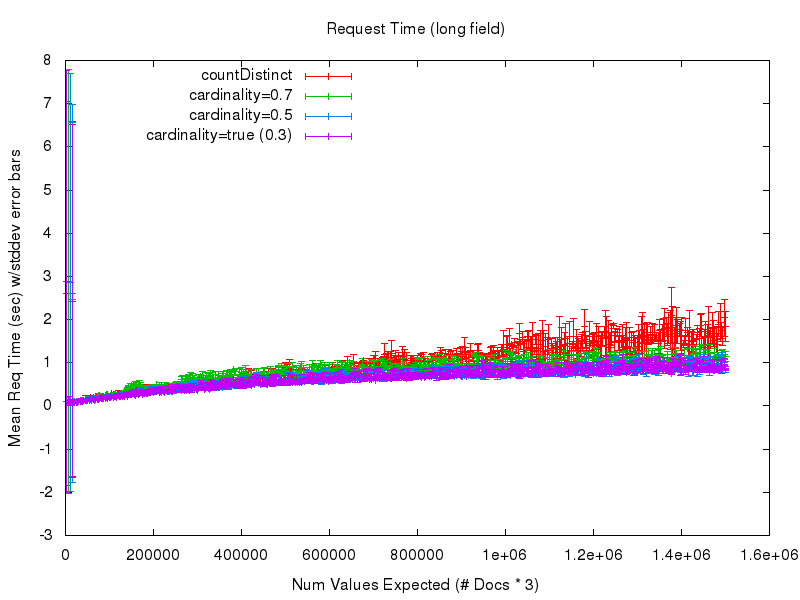
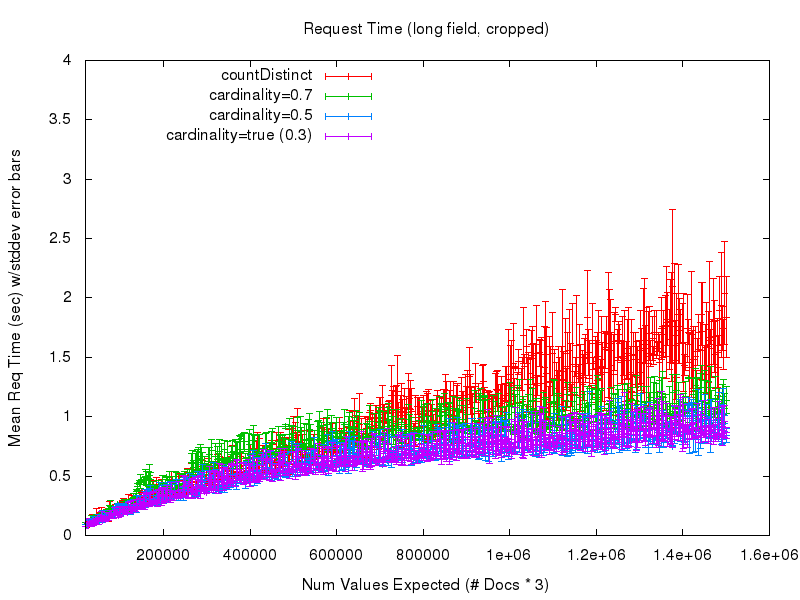
Here we start to see some obvious advantage in using the cardinality option. While the countDistinct response times continue to grow and get more and more unpredictable — largely because of extensive garbage collection — the cost (in processing time) of using the cardinality option practically levels off. So it becomes fairly clear that if you can accept a small bit of approximation in your set cardinality statistics, you can gain a lot of confidence and predictability in the behavior of your queries. And by tuning the cardinality parameter, you can trade off accuracy for the amount of RAM used at query time, with relatively minor impacts on response time performance.
If we look at the results for the string field we can see that while the accuracy results are virtually identical to, and the request time performance of the cardinality option is consistent with, that of the numeric fields (due to hashing) the request time performance of countDistinct completely falls apart — even though these are relatively small string values….
{kind=link}
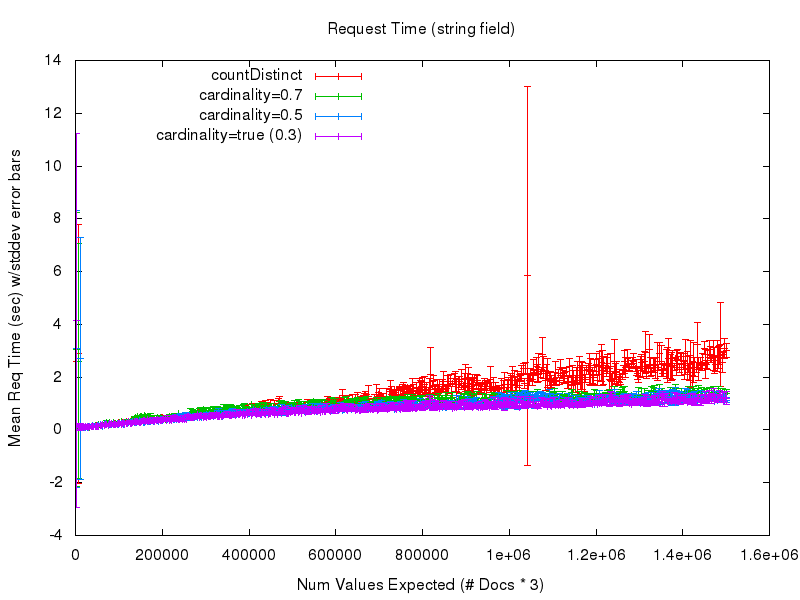
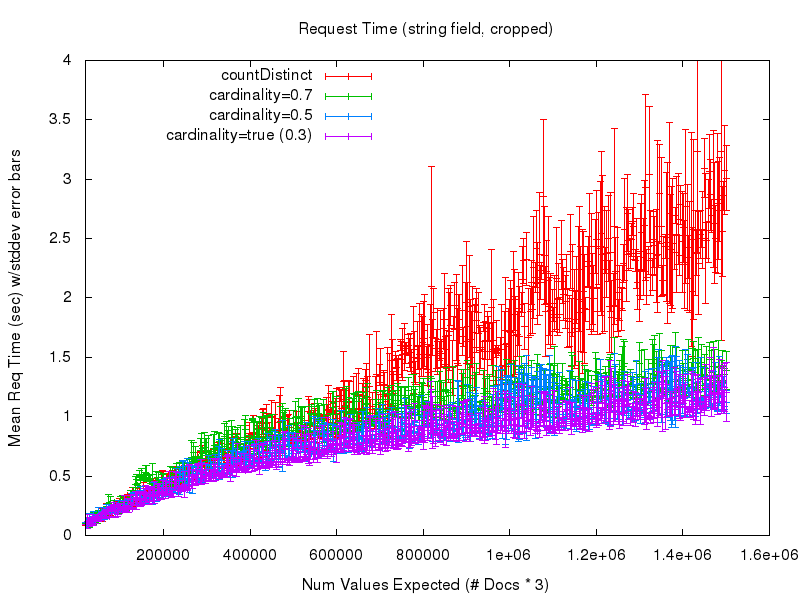
I would certainly never recommend anyone use countDistinct with non trivial string fields.
Next Steps
There are still several things about the HLL implementation that could be be made “user tunable” with a few more request time knobs/dials once users get a chance to try out and experiment with this new feature and give feedback — but I think the biggest bang for the buck will be to add index time hashing support — which should help a lot in speeding up the response times of cardinality computations using the classic trade off: do more work at index time, and make your on disk index a bit larger, to save CPU cycles at query time and reduce query response time.
LEARN MORE
Contact us today to learn how Lucidworks can help your team create powerful search and discovery applications for your customers and employees.