Why Lucidworks Fusion and ChatGPT?
We take a dive into the ways the Fusion platform grounds technology like generative AI and large language models in truth.

Six months ago, one of our major customers challenged us to integrate OpenAI and our search platform Fusion for an employee experience use case. They viewed both of us as their strategic vendors and wanted to see how much value they can extract by leveraging large language models, but still maintain the controls and user experience Fusion provides for their employees.
Since then, we’ve seen very strong interest for an integrated ChatGPT and Fusion experience across multiple use cases (Commerce, Knowledge Management, Customer Service, etc). There is a lot of hype around ChatGPT as of late. While some customers ask why they need a search platform in addition to ChatGPT, it’s important to underscore that a robust search platform is still required to get the full value out of large language models such as ChatGPT.
To learn more, watch our demo video below or continue reading.

Some benefits of an integrated ChatGPT and Fusion solution:
- Guardrails and control – limit ChatGPT responses to your catalog and document
- Data enrichment – extract metadata and send back to Fusion for future use
- Security – filter out products and documents by userid or segment
- Seamless, integrated experience between ChatGPT and Fusion, including facets
- Non-product content – ask ChatGPT about complementary content
- Predictive Merchandiser – merchandiser control of product display
- Personalization and Recs – leverage Recs in Fusion to display in ChatGPT
- Connectors – connect any data and use as training data for ChatGPT
- Signal collection and training processes – system continually improves with your data and user behavior
- Performance – users tend to bounce quickly with slow response times, which is typical of a chat experience
Another limitation of ChatGPT is its lack of knowledge around domain-specific content. While it can generate coherent and contextually relevant responses based on the information it has been trained on, it is unable to access domain-specific data or provide personalized answers that depend on a user’s unique knowledge base. Users should, therefore, exercise caution when seeking advice or answers on such topics solely from ChatGPT.
The HOW
How do we do it? One key differentiator between Fusion and other search engines is that customers can bring in any machine learning model into Fusion, including large language models such as ChatGPT, Bard (Vertex PaLM API, Bloom, etc). Fusion’s flexible index and query pipelines allow Fusion to transform a large language model response (including entity enrichment and others).
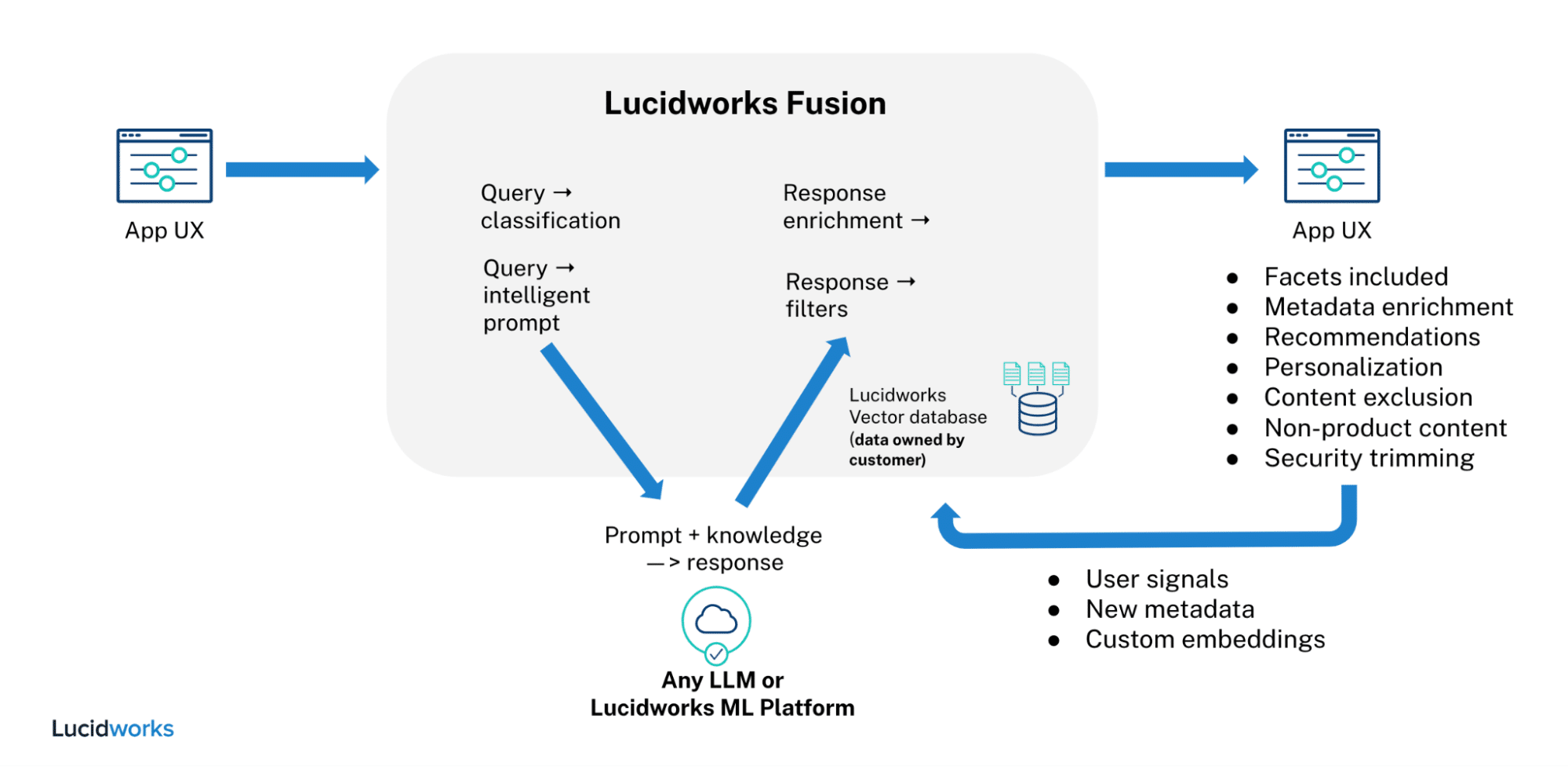
In the flow diagram below you will see how all queries are routed through Fusion query pipeline first, including the ChatGPT response. This allows Fusion to interpret the ChatGPT response and do a number of things before returning the message to the user. For example, extract entities, facets, recs, and filter out unwanted data.
The same can be done at index time, which is a big cost of ownership driver for enterprises. For example, instead of calling ChatGPT API at query time, you do this at index time to enrich the metadata for your catalog or document index. There are a lot of advantages in enriching your data using large language models at index time.
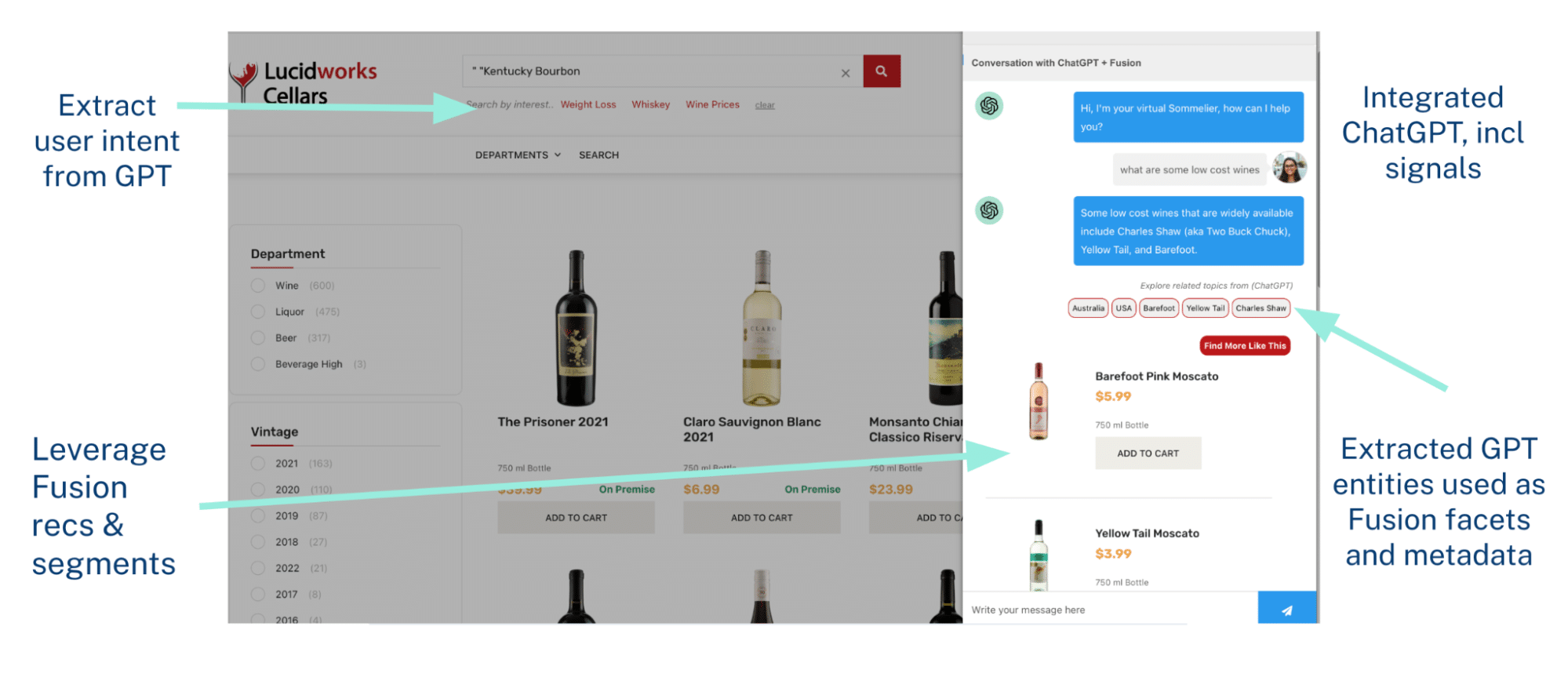
By controlling the ChatGPT response, you can see in this demo below a fully integrated, seamless experience with Fusion and ChatGPT. Fusion extracts the entities from the ChatGPT response and uses them for entity extraction, facets, and boosting. The product listing in the chatbot comes from another Fusion Query Pipeline, which can be powered by recommendations, personalization, or even boost/bury rules driven by Predictive Merchandiser (merchandiser tooling). Under the search bar, we extract “user intents” from various ChatGPT questions for further personalization.
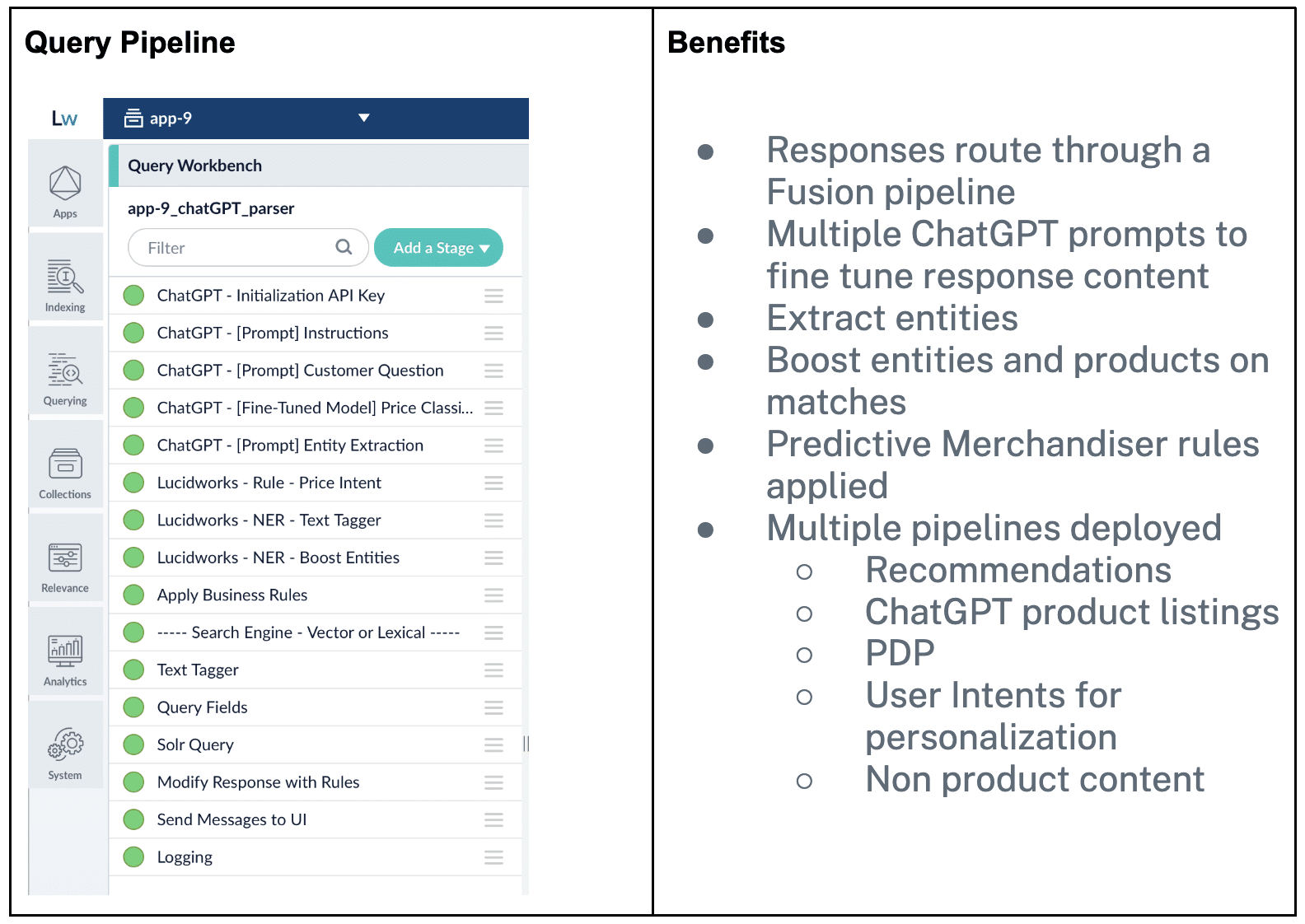
Below is an example of a Fusion Query Pipeline. Pipelines execute from the top down. You’ll notice we use multiple ChatGPT Prompts to initialize and fine tune the responses that come back to Fusion. For example, you can use a Prompt to extract entities from the response (ie, Brand, Vintage, Region). Once we have that metadata from ChatGPT, we can map to things in Fusion like Facets or use for relevancy boosting. We can also use a prompt to get more information from the response, such as “In two words or less, tell me what this user is asking”. This is great for personalization use later down the product discovery journey.
Later Query Pipeline stages do things like understanding price intent, and apply business rules that may be defined in Predictive Merchandiser (merchandiser UI).
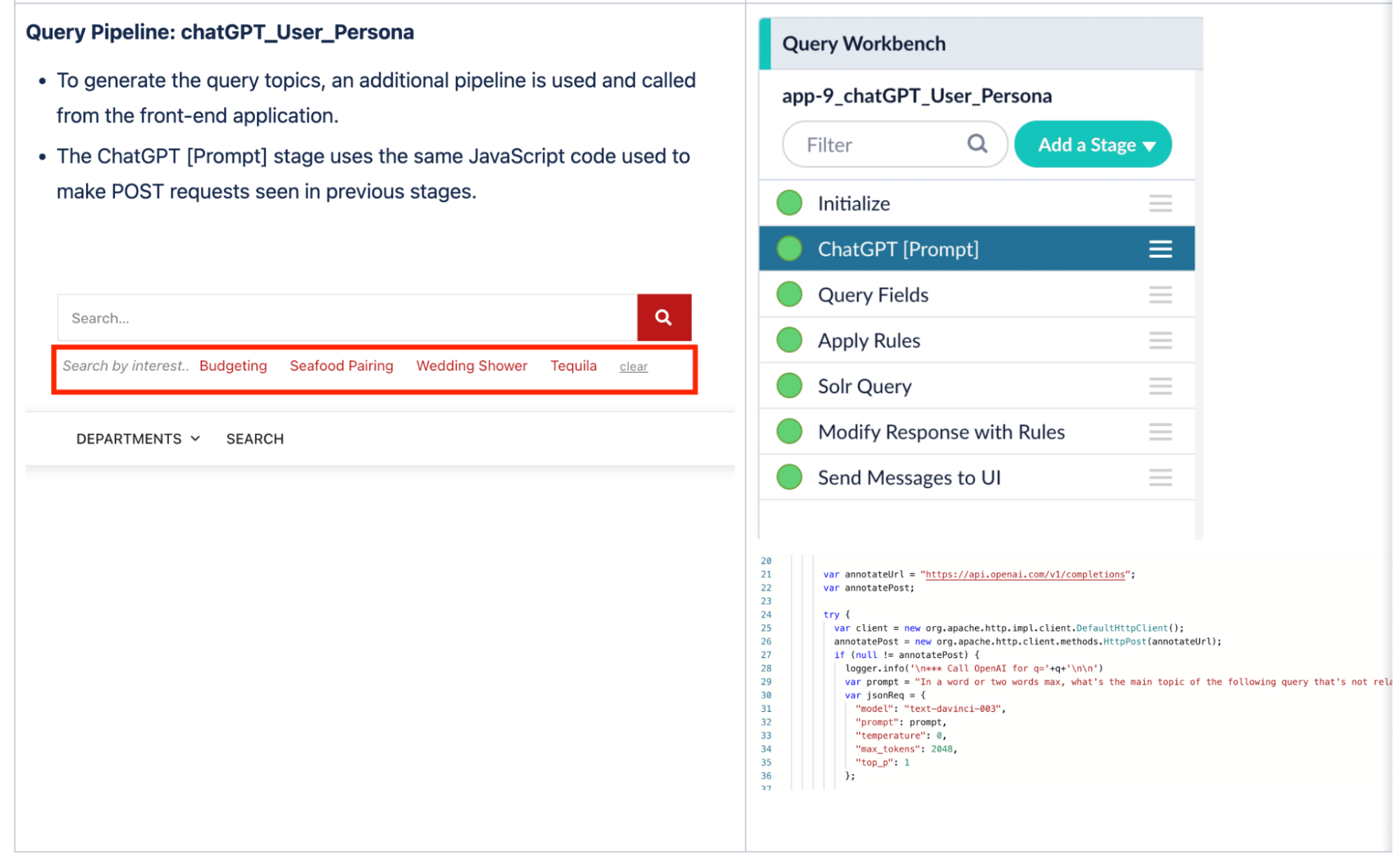
The additional power in this example is leveraging a Query Pipeline stage to get more context from a GPT LLM. Here is an example of a Prompt ChatGTP stage. The Prompt to ChatGPT is simply “In a word or two, what’s the main topic of the following query”. The responses are then used to power the “Search by Interest” links under the search bar, which can be used for future personalization. These can be used in session and/or stored in a Fusion collection for future use. You can have multiple Prompts, including finely tuned classifier stages.
You can use ChatGPT Prompts for other things like non-product content as well. For example, on the PDP, write a Prompt “What food goes well with this wine?” This can also be controlled from Predictive Merchandiser.
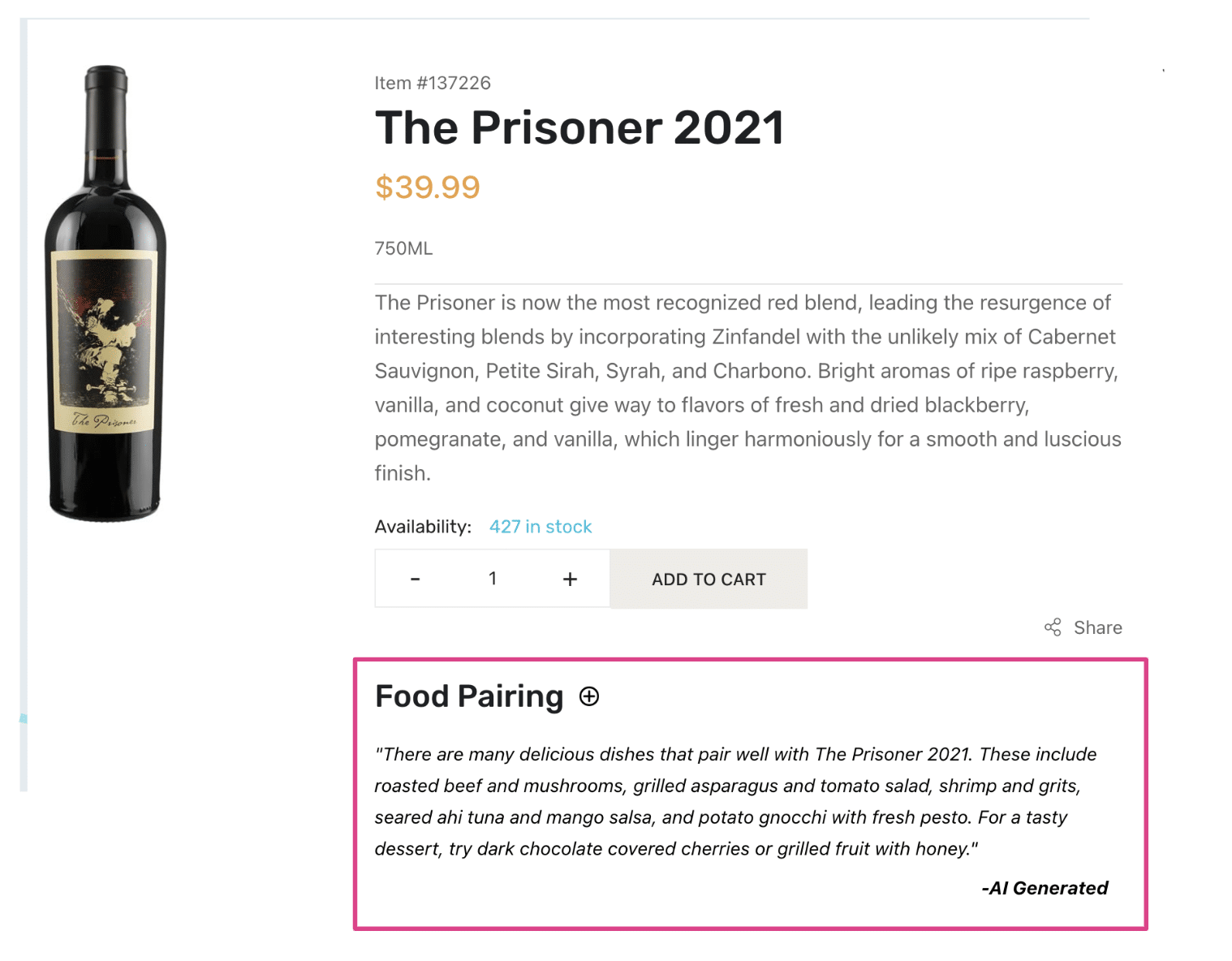
In summary, Fusion grounds large language models in the truth. We have demos ready now for ChatGPT (OpenAI GPT4), Bard (Google Vertex PaLMAPI), and other large language models. Contact us for more information or a demo of your own data.
LEARN MORE
Contact us today to learn how Lucidworks can help your team create powerful search and discovery applications for your customers and employees.