Accuracy vs Speed – What Data Scientists Can Learn From Search
Learn how to manage the competing priorities of accuracy vs. speed when building a search application.

As data scientists, we have a top priority: delivering accurate insights. If you’re like me, a data scientist who’s also working on search (or any real-time application for that matter), you’ve got to manage two competing priorities that sometimes butt heads: accuracy and speed.
I’ll walk you through some of the things I’ve learned through trial and error as a data scientist in search, including tips on how to smooth out some of the friction that can pop up when you’re building a tool that demands cross-collaboration with other domain disciplines.
Learn How To Think About Search
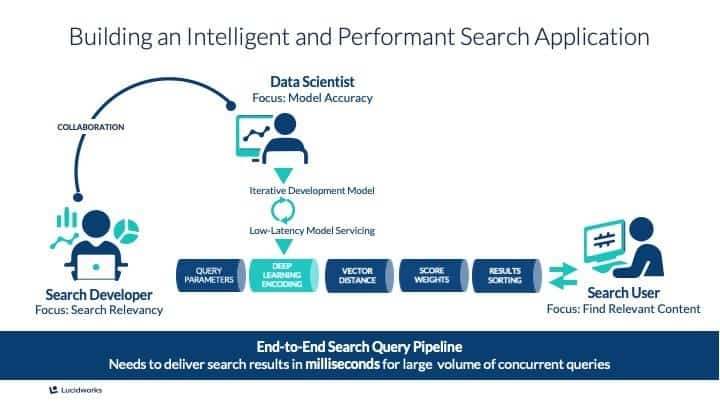
As data scientists, there are a lot of terms and concepts specific to search. For example, discovering the power of the inverted index — a concept I’d never worked with previously — is critical to building a search platform. (FYI: an inverted index is “a simple way to search documents, images, media, and data regardless of the structure of the document the data is coming from.)
Another area I had to learn was how to organize natural language processing (misspelling, entity extraction or synonym detection for query rewriting) and other machine learning techniques (classifiers, clustering, recommenders) in a pipeline.
After spending time understanding the mechanics of a search platform, I was about halfway there. But then I had to figure out how to measure results. The metrics and KPIs that search developers and businesses use to determine the efficacy of their search platform were new to me.
For example, data scientists focus primarily on model accuracy measurements that target error rates, error types, misclassification, etc. However, the metrics used for measuring model accuracy can sometimes be difficult to be mapped with confidence to the aggregated business metrics for search relevance. The search metrics tend to be more business oriented and include clickthrough rates, add-to-cart, and purchase (for e-commerce), and commenting, sharing, and rating of documents and results (for the digital workplace).
If this feels daunting at first (like the first time stepping into a new field), ask a search developer in your org to walk you through the terminology, metrics, and deployment considerations at the beginning of each project. This knowledge transfer should be a two way street in case the search developers need an overview of data science processes and methods. Unfortunately, it is rare in most organizations to facilitate this type of cross-functional knowledge transfer regularly, and it creates a major pain point when you dedicate time to a project and then find out halfway through you were building on the wrong assumptions.
Adjust Your Approach to Building Models
If you go through the exercise above, now you understand that the other major stakeholder in search, the search developer, is focused on how the entire search pipeline functions. You have to now switch from just thinking about how the models perform from an accuracy standpoint to how they fit in as one component in a larger system.
Take a ‘zoomed-out approach.’ Ask yourself: “Is the end goal clear to me? How fast must my models perform? Can they scale?” The answers to those questions can serve as guidelines to build more effective, lightweight, responsive models throughout the pipeline to help drive business outcomes.

For digital commerce companies, better business outcomes mean driving revenue, and in the digital workplace, it means boosting productivity. As I said before, we’re focused on delivering accurate insights, but without knowing how the model fits into the system as a whole, it’s difficult to know if your results are the most relevant or delivered in the most optimal way.
Maintain the Project’s Momentum
Delivering a delightful search experience requires cross-functional disciplines, like search development, data science, operations, and business domain, to collaborate and innovate together. But most organizations encounter multiple barriers to cross-team collaboration, including obstacles in processes, hierarchies, personalities, and culture in general. Juggling priorities of speed, accuracy and integration can create friction in the iteration between data scientists and search developers.
The best process, in theory, enables the type of iteration and back and forth where data scientists deliver the artifacts (models) that search developers can integrate, quickly test in the query experience, and if needed loop them back to the drawing board for refinement. Most search projects fail because of a lack of integration and collaboration. It’s less because teams don’t have the requisite knowledge, it’s more because there’s a lack of alignment on goals, expectations and processes.
Communication is key here. Having someone sit you down and walk you through the process of how they do things end to end is massively helpful. Before producing anything, understanding ‘a day in the life of’ other search stakeholders is huge—including what data sources and data formatting is used, transformations being applied, metrics being tracked, and architectural considerations.
These friction points are things we keep in mind as we build our search platform at Lucidworks. We go through the bumps between data scientists and search developers, we work on smoothing the handoffs and connecting to the business outcomes measurement. We obsess with enabling our customers to deploy the most relevant and performant search experience. Search isn’t easy, but when designed correctly, it can have a major impact on the customer experience!
The Future of Data Scientists in Search
In the search arena, we’re discovering every day new ways in which deep learning can transform the search experience. As data scientists, we’re working toward a very near and attainable future where people will interact with applications in a conversational manner. This is already happening in our experience as a consumer, but it is starting to apply across the board to all digital applications we interact with.
Examples of workplace applications can be ERP systems, CRMs, business intelligence apps, or centralized information retrieval from other systems. We’re already seeing massive success in tackling the challenges of taking spoken or free form text, interpreting it in a way that machines can understand, to produce a query, and push out relevant results and recommendations in a format that the user can consume and act on.
The new frontier in search is understanding the explicit and implicit intent of the user, and it needs to go beyond just understanding text. It involves learning context using search and the user’s browsing history, the attributes of the user and the search results he/she consumes, as well as the usage of other users that can inform the results in the current search experience.
For example, when a sales professional types: “Give me my pipeline for my northwest territory” understanding the intent could mean that results also include contact information if outreach is needed, a summary of past communications if he/she is preparing a report or a side by side comparison of your southwest territories for benchmarking.
Tips for Succeeding as a Data Scientist (In Any Field)

I teach a career readiness seminar for data scientists and I always explain that we are providers of insight, not decision-makers. We should develop models that allow people to quickly understand insights and then apply them to make smart decisions. The best data scientists can develop models that deliver the ‘right’ insights to the right people at the right time. In order to increase your relevance as a data scientist, it is encouraged to expand your perspective. Most “unicorns” find themselves at the intersection of these three domains: algorithmic knowledge, systems/architecture knowledge, and business/communications skills.
Search is a textbook representation of how these things have to come together in order to make a system sing. If you’re an algorithmic savant but don’t understand how it scales, or don’t understand how to connect your algorithm to the goal of driving conversions through a relevant search experience, you won’t be able to deliver as much value to the company.
It is definitely an exciting time to be a data scientist in the search field. While the coverage of the progression of search technology has been ubiquitous, I believe we are barely scratching the surface. I look forward to seeing how the AI-powered search use case continues to create new, exciting, and impactful opportunities for data scientists.
The original version of this article can be found on KDnuggets.
LEARN MORE
Contact us today to learn how Lucidworks can help your team create powerful search and discovery applications for your customers and employees.