Use Fusion + Topic Queries for Collection Monitoring and Alerting

Overview
Lucidworks Fusion provides a set of APIs which can be used to query, update, and otherwise interact with Apache Solr. However, many new features of Solr have yet to have direct support within Fusion pipeline stages. For example, the new Streaming Expressions API in Solr 6.2+ has sources for JDBC/SQL queries, distributed graph traversal, machine learning and parallel iterative model training, topic queries and more. To see some of the things which can be done with Solr’s Streaming Expressions check out Joel Bernstein’s blogs at solrj.io.
Solr’s Streaming expressions
Beginning with release 6.0, Apache Solr has been growing support for Streaming Expressions. One of the capabilities of Streaming Expressions is known as a topic query. Simply put, a topic query is a mechanism which will track each time a given topic is queried and only return results which are newer than those previously queried for that topic. This provides an easy way to repeatedly perform a query but only get results which have not been seen before.
Possible use-cases
What is a site admin to do when s/he needs to gather operational information but has no convenient API which provides the needed information? Clues may be noted in the logs from time to time but continually checking the logs can be tedious. A scheduled topic query can help! Consider these examples:
You have a Solr query which you want to run after a successful execution of a Fusion datasource to gather and report important statistics relevant to that datasource. When a data ingestion crawl completes a simple message of “FINISHED” is logged together with the collection and data source names as follows.
2017-03-07T10:00:03,554 - INFO [com.lucidworks.connectors.ConnectorJob, id=important-datasource:JobStatus@294] - {collectionId=enterprise-search, datasourceId=important -datasource} - end job id: important-datasource took 00:00:03.429 counters: deleted=0, failed=0, input=1, new=0, output=1, skipped=0 state: FINISHED
A sister company which regularly provides data to be ingested into Fusion has a history of sending bad data. The result is that some records do not get ingested. The problem stems from a data collation bug on their end which results in a very long data field. The offending organization reports that they have fixed the problem but ask that you to notify them if and when it happens again. The following shows an example of that this error looks like in the log.
ERROR (qtp606548741-61861) o.a.s.h.RequestHandlerBase org.apache.solr.common.SolrException: Exception writing document id Research-112885-334 to the index; possible analysis error: Document contains at least one immense term in field="entity_desc_s" (whose UTF8 encoding is longer than the max length 32766), all of which were skipped.
The Operations department wants to be notified whenever you crawl a web site which does not use a robots.txt file to control the crawl rate. You crawl thousands of sites a month and they are often changing their setup. However, when you crawl a site without a robots.txt setup you do get the following message in the log file.
WARN [test-fetcher-fetcher-4:RobotsTxt@81] - {} - http://www.SampleServer.com:80 has no robots.txt, status=404, defaulting to ALLOW-ALL
The types of things which can be done using the techniques shown in this tutorial are myriad. However, to limit scope to a reasonable degree, this tutorial will focus on the missing robots.txt example mentioned above. Of course, similar steps can be used to solve any of the above problems as well as many others.
The steps are as follows:
- Develop a topic query which can identify the condition or state being monitored. E.g. the crawling of a site which does not have a robots.txt file.
- Configure the SMTP Messaging service to send emails from a pipeline stage. This only needs to be performed once on a given Fusion instance
- Trigger the topic query from within a pipeline stage. Either an index or query pipeline can be used depending on which one best fits your use-case.
- Format the results of the topic query (if any) into a message and store the message in the pipeline context
- Email the message (if any) from the pipeline context via a Messaging Stage.
Step 1. Develop a topic query
The screenshot below shows how a topic query for a log message could be set up in Solr. Getting the query and topic parameters just right can be tricky so modeling this in the Solr Streaming Expression tool can be helpful. Once the query is known to work as expected, it can be embedded in either a Fusion Index or Query pipeline stage. What’s more, the Fusion scheduler can be used to run the pipeline as often as needed in order to continually monitor for a given alert condition.
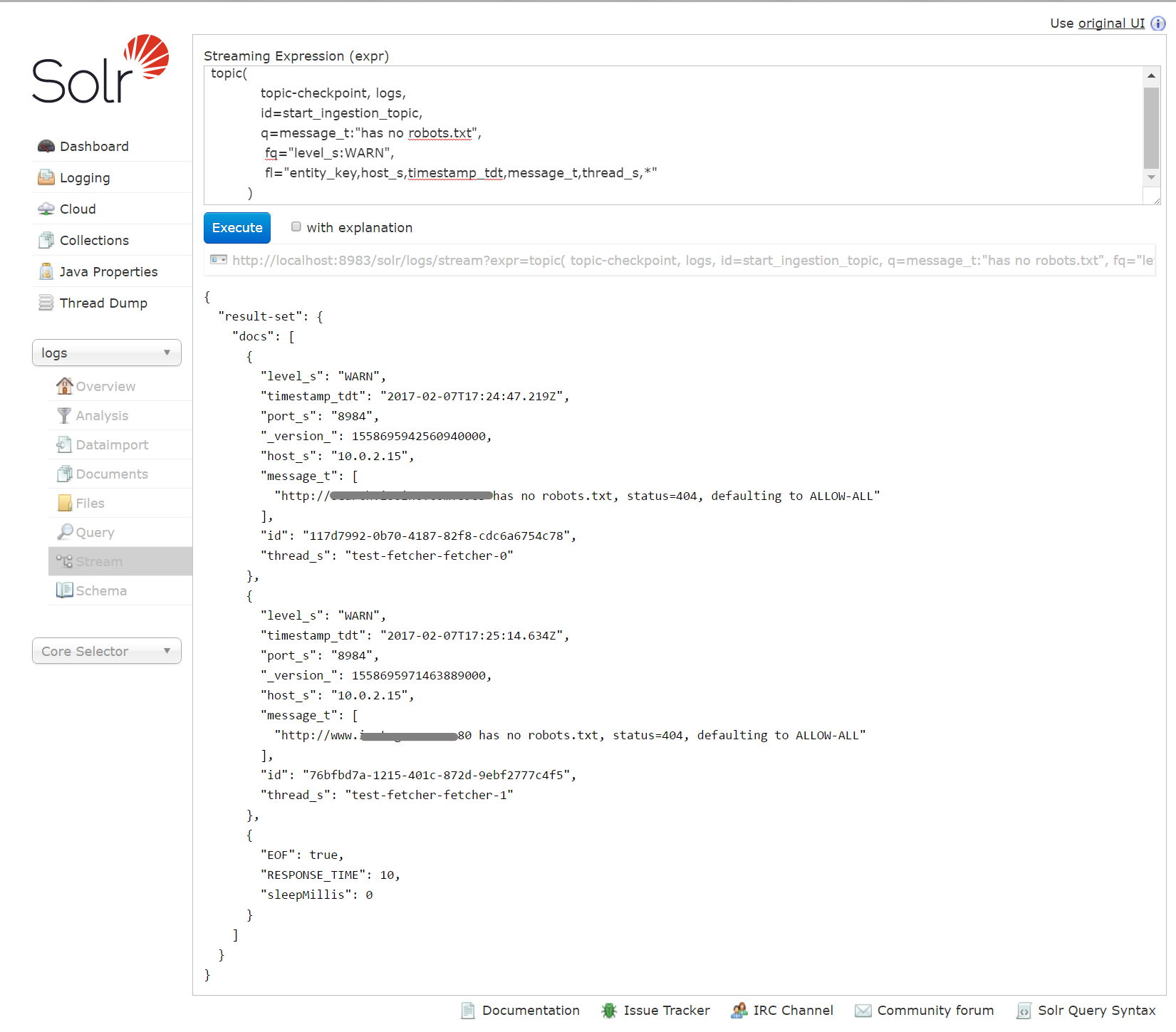
A few of things to note:
- The meaning of the first three parameters to the topic query may not be obvious. They are:
- The collection in which the topic query state is logged i.e. topic-checkpoint. This collection can easily be created using Fusion but it must exist when the topic query is submitted. It will be used by the Solr Streaming Expression mechanism to keep track of when a given topic is queried.
- The collection which will be queried i.e. logs
- A unique topic name. Use any name you wish, but use it consistently.
- The fields in the Logs collection differs between fusion 2.4.x and 3.0 and so the field list (fl parameter ) in the query may need to be adjusted accordingly.
- The topic query result-set does not follow the familiar response.docs format used by Solr’s select handler. One implication of this is that while, within Fusion, the results of the topic query can be manipulated and sent to the Messaging API, adding these results to the standard response object in a Query Pipeline is not automatic. In this tutorial, the Query Pipeline does not directly publish to the response object so it will not produce results which can be seen in the Fusion Search page. If a user wanted to both publish to an email as well as to the Fusion Search page the results of the topic query would need to be transferred to the pipeline’s response object..
- The last record of the result-set marks the end of the response. A similar “EOF” record will always be returned even when the topic query found no new records.
- Remember, a topic query keeps track of what has already been published for a given topic and only return a given result one time. If you need to fine-tune your query or otherwise test a topic query, you will need to delete records from the checkpoint collection in order to reset the state of the topic.
Step 2, Configure the SMTP Messaging service
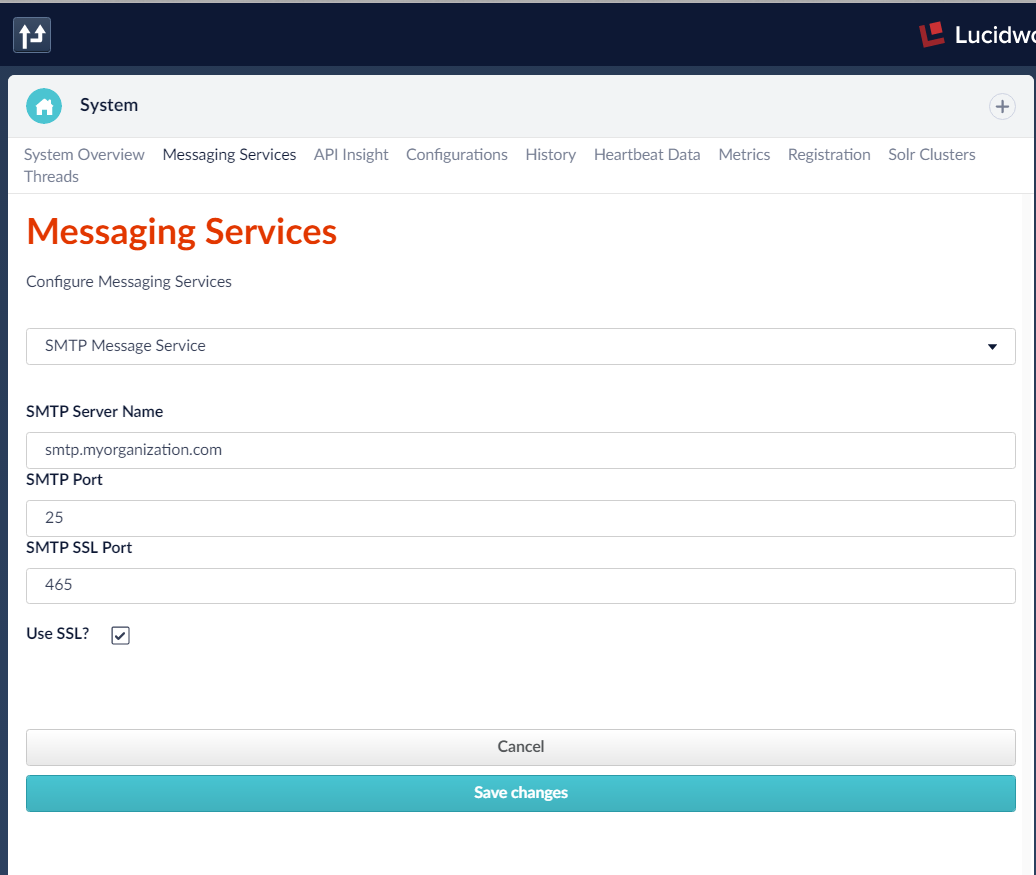
The fusion Messaging service is configured from the System page located under the Application menu in Fusion 2.4.x or the DevOps Home menu in 3.0. Notice that Messaging services for Slack (text messages) and Paging services can also be configured. The Logging Message service can be used without configuration. For more information and examples of ways to use Messaging stages for Alerts see this technical article.
From the System page, click on the Messaging Services tab and fill in the needed configuration. Depending on the SMTP server used, the port and SSL options may need to be adjusted. Check with your email service provider for details. If you are unable to set up the SMTP Message Service, you can still complete this tutorial by using the Logging Service. The difference is that your alert message will be written to the log file rather than published in an email.
Steps 3 and 4, Triggering a topic query via a Fusion pipeline stage and format the results into a message
As of release 3.0, Fusion does not directly support queries to the Solr stream handler. Because of this, streaming expressions such as topic queries need to be performed using a JavaScript stage. In the following example, information is retrieved from a topic query via an HTTP GET call and then a SMTP Message pipeline stage is used to publish this information.
The JavaScript pipeline stage
The bulk of the work, both in launching the topic query and in formatting an appropriate message from the query results is done in a JavaScript pipeline stage. The full script is provided at the end of this tutorial but simplified versions of the key functions are shown below.
function buildTopicQueryUrl(serverName, topicQuery){
var uriTemplate = '/{collection}/{requestHandler}';
var uri = 'http://' + serverName + ':8983/solr' + UriBuilder.fromPath(uriTemplate).build(collection,'stream').toString();
uri += ('?wt=json' + '&expr=' + encodeURI(topicQuery));
return uri;
}
The buildTopicQueryUrl function simply takes a topicQuery String and formats it into a URL suitable for querying Solr.
function queryHttp2Json(url){
var client = HttpClientBuilder.create().build();
var request = new HttpGet(url);
var rsp = client.execute(request);
var responseString = IOUtils.toString(rsp.getEntity().getContent(), 'UTF-8');
return JSON.parse(responseString);
}
The queryHttp2Json function performs a simple HTTP GET request for a given URL. The results are parsed into a JSON object. For simplicity, a response holding a JSON formatted UTF-8 String is assumed.
function main(request, response ){
'use strict';
var alertMessage = '';
var topicQuery_3_0 = 'topic(' +
'topic-checkpoint,logs,id=start_ingestion_topic,' +
'q=message_t:"has no robots.txt",' +
'fq=level_s:WARN’, +
'fl="level_s,host_s,timestamp_tdt,message_t,thread_s")';
try {
var url = this.buildTopicQueryUrl('localhost',topicQuery_3_0); //Line 12
var json = this.queryHttp2Json(url); //Line 13
}catch(err){
logger.error("Error querying solr " + err);
}
//only process result-set elements containing a message_t field
if(json && json['result-set'] && json['result-set'].docs && //Line 19
Array.isArray(json['result-set'].docs) &&
json['result-set'].docs[0].message_t
){
var docs = json['result-set'].docs;
alertMessage += 'Top ' + (docs.length -1)+ ' are:n';
//process all records except the last last one (EOF)
for(var i = 0; i < docs.length; i++){ //Line 28
// loop thru records and format the alertMessage
…
}
//set this in the pipeline for publication by an alert stage
ctx.put('scriptMessage',alertMessage); //Line 103
}
};
The main function calls buildTopicQueryUrl() and queryHttp2Json()on lines 12 and 13. A check to ensure that the results contain the anticipated structure is done on lines 19-22 and the process of looping thru the JSON results starts on line 28. For brevity the individual message looping to format the alertMessage is omitted. Finally, on line 103, the alertMessage is placed in the pipeline context object so that can be picked up by a stage which will publish the message.
Step 5, Publish the message
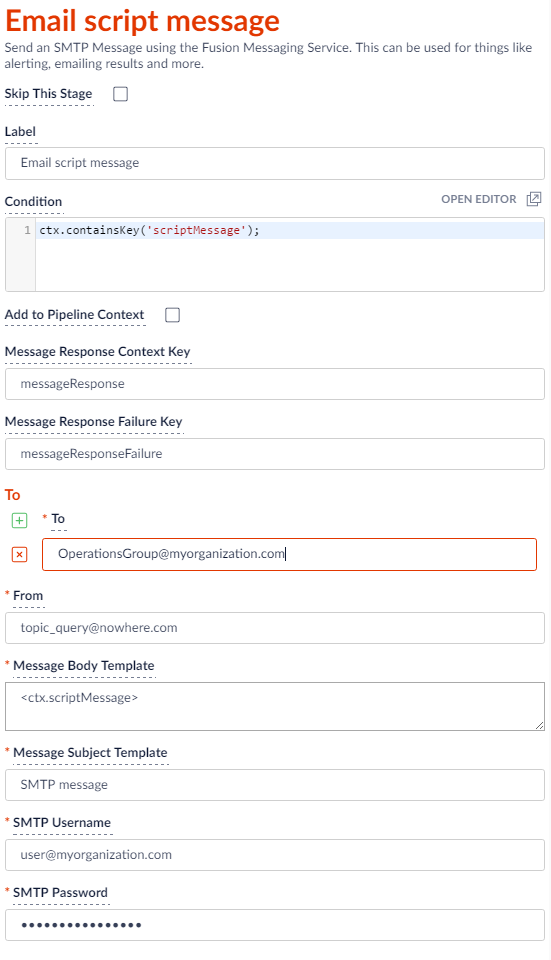
If the JavaScript stage finds new log entries matching the topic query, a scriptMessage will get placed into the pipeline context. Testing for this message in the Condition block of the Messaging stage ensures that only newly discovered messages are published. The following screenshot shows this check in the Condition script block as well as sample values which are used to fill in the body of a Send email pipeline stage.
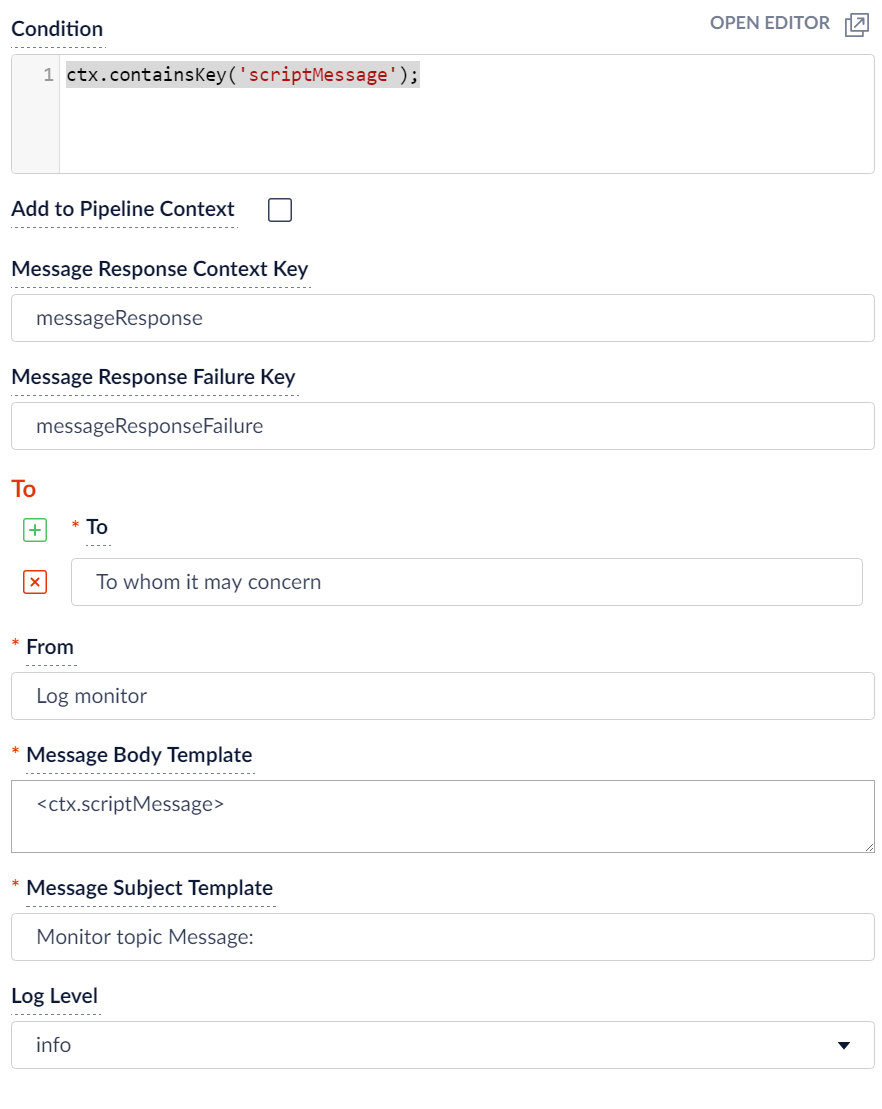
If, instead of using a Send email pipeline stage you use the Log a Message stage your stage will look like this.
Conclusion
In the Overview section, several possible uses for topic queries were presented and one in particular—the need to notify the Operations department when sites are crawled which have not robots.txt file—was singled out for this tutorial. This was accomplished by a combination of a JavaScript stage and an Alerting stage. The JavaScript stage used a topic query to find new log entries indicating a missing robots.txt file and formatted those log entries into a message for publication by the Alerting stage. More generally, this example demonstrates how to automatically publish any formatted notification whenever an important log message is written by Fusion. Because a topic query does not report previously queried results, topic queries can be run over and over and will only return unreported results after new data is written to the target collection. This makes topic queries ideal candidates for being run by the Fusion scheduler to continually monitor the state of a Fusion installation.
/*jshint strict: true */
/**
* JavaScript query pipeline stage called by com.lucidworks.apollo.pipeline.query.stages.JavascriptQueryStage
*
*
*/
// list known globals so that jshint will not complain.
/* globals Java, id, logger, context, ctx, params, request,response,collection,solrServer,solrClientFactory, arguments */
var _this = {};// jshint ignore:line
var invocationArgs = Array.prototype.slice.call(arguments);
//log level set in /apps/jetty/connectors/resources/log4j2.xml e.g.
logger.debug('*************************** JSCrawler QUERYPIPELINE *************');
var LinkedHashSet = Java.type('java.util.LinkedHashSet');
var LinkedHashMap = Java.type('java.util.LinkedHashMap');
var JavaString = Java.type('java.lang.String');
var ArrayList = Java.type('java.util.ArrayList');
var UriBuilder = Java.type('javax.ws.rs.core.UriBuilder');
var HttpClientBuilder = Java.type('org.apache.http.impl.client.HttpClientBuilder');
var HttpGet = Java.type('org.apache.http.client.methods.HttpGet');
var IOUtils = Java.type('org.apache.commons.io.IOUtils');
/**
* add functions as needed then return results of crawl()
*/
_this.getTypeOf = function getTypeOf(obj){
'use strict';
var typ = 'unknown';
//test for java objects
if(obj && typeof obj.getClass === 'function' && typeof obj.notify === 'function' && typeof obj.hashCode === 'function'){
typ = obj.getClass().getName();
}else{
typ = obj ? typeof obj :typ;
}
return typ;
};
_this.buildTopicQueryUrl = function(serverName, topicQuery){
var uriTemplate = '/{collection}/{requestHandler}';
//logger.info('Querying Solr for topicQuery : ' + topicQuery);
var url = 'http://' + serverName + ':8983/solr' + UriBuilder.fromPath(uriTemplate).build(collection,'stream').toString();
url += ('?wt=json' + '&expr=' + encodeURI(topicQuery));
return url;
}
/**
* Perform an HTTP GET request for a URL and parse the results to JSON.
* Note: for example simplicity we assume the response holds a JSON formatted UTF-8 string.
*/
_this.queryHttp2Json = function(url){
//logger.info('BUILDING HTTP REQUEST : ' );
var client = HttpClientBuilder.create().build();
var request = new HttpGet(url);
//logger.info('SUBMITTING HTTP REQUEST : ' + url);
var rsp = client.execute(request);
//logger.info('MESSAGE gpt resp: ' + rsp );
var responseString = IOUtils.toString(rsp.getEntity().getContent(), 'UTF-8');
//logger.info('PARSING JSON from ' + responseString);
var json = JSON.parse(responseString);
return json;
}
/**
*
*/
_this.process = function process(request, response ){
'use strict';
var alertMessage = '';
var topicQuery_2_4 = 'topic(' +
'topic-checkpoint,logs,id=start_ingestion_topic,' +
'q=message_t:"has no robots.txt",' +
'fq="ctx_collectionId_s:' + collection +
' AND ctx_datasourceId_s:*",' +
'fl="host_s,timestamp_tdt,message_t,ctx_collectionId_s" )';
var topicQuery_3_0 = 'topic(' +
'topic-checkpoint,logs,id=start_ingestion_topic,' +
'q=message_t:"has No robots.txt",' +
'fq=level_s:WARN,'+
'fl="level_s,host_s,timestamp_tdt,message_t,thread_s",' +
'initialCheckpoint=0 )';
try {
var url = this.buildTopicQueryUrl('localhost',topicQuery_3_0);
var json = this.queryHttp2Json(url);
}catch(err){
logger.error("Error querying solr " + err);
}
if(json && json['result-set'] && json['result-set'].docs &&
Array.isArray(json['result-set'].docs) && //this much should always be there
json['result-set'].docs[0].message_t // if "empty" we shouldn't have a dataSource
){
/*
An "empty" response looks like this EOF record and experimentation shows it to be in every response
{"result-set":{"docs":[
{"EOF":true,"RESPONSE_TIME":29,"sleepMillis":1000}]}}
*/
var docs = json['result-set'].docs;
alertMessage += 'Top ' + (docs.length -1)+ ' are:n';
/* Unlike Fusion 2.4.x the 3.0 result does not have datasource or collection fields.
{
"level_s": "WARN",
"timestamp_tdt": "2017-02-07T17:24:47.219Z",
"port_s": "8984",
"_version_": 1558695942560940000,
"host_s": "10.0.2.15",
"message_t": [
"http://foobar.com:8983 has no robots.txt, status=404, defaulting to ALLOW-ALL"
],
"id": "117d7992-0b70-4187-82f8-cdc6a6754c78",
"thread_s": "test-fetcher-fetcher-0"
}
*/
//process all records except the last one which should be the EOF record
for(var i = 0; i < docs.length; i++){
var doc = docs[i];
//filter out the EOF record by only acccepting docs containing a message_t
if(doc && doc.message_t ) {
alertMessage += 'ttimestamp_tdt: ' + doc.timestamp_tdt + 'n';
if(doc.ctx_datasourceId_s) {
alertMessage += 'tctx_datasourceId_s: ' + doc.ctx_datasourceId_s + 'n';
}
if(doc.thread_s) {
alertMessage += 'tthread_s: ' + doc.thread_s + 'n';
}
var messages = doc.message_t; //message_t is an Array type
if (messages && messages.length) {
alertMessage += 'tmessage lines: n';
for (var n = 0; n < messages.length; n++) {
var msg = messages[n];
alertMessage += 'tMsg:' + (n + 1) + 't :' + msg + 'n';
}
}
}
}
//set this in the pipeline so that the alert stage can publish it
ctx.put('scriptMessage',alertMessage);
logger.info('publishing scriptMessage as ' + alertMessage);
}
};
//invoke the 'main' function when wrapper is called
var returnValue = _this.process.apply(_this,invocationArgs);
//the crawler.fetch.impl.script.JavascriptFetcher expect the last line to be a return value.
returnValue;// jshint ignore:line
Andrew Shumway is a Senior Software Engineer at Polaris Alpha and a consultant for Lucidworks where he builds enterprise search applications.
LEARN MORE
Contact us today to learn how Lucidworks can help your team create powerful search and discovery applications for your customers and employees.