Streaming Expressions in SolrJ
Here at Lucidworks we recently had an “exciting” adventure. A client wanted to access Streaming Expression functionality through SolrJ. This turned out to be more challenging than we expected so we thought it would be useful to create a blog post with our findings/recommendations.
Recommendation
Save yourself time and effort, and use the pattern described below. Do not try to assemble the low-level components yourself, unless you want to spend several days duplicating work done by the authors of the Streaming Expression code.
Yes, I know. Real Programmers assemble low-level code themselves because they’re, well, Real Programmers. The traditional rationale for using low-level constructs is it’s more efficient. Writing to a higher level means the only “inefficiency” here is that Solr will have to parse the expression. I maintain the time spent parsing the string version of a Streaming Expression is so minuscule compared to the work done by the query, that the “efficiency” of using low-level construct is completely lost in the noise. Really, spending several days (or weeks considering upgrading may require you to revisit your code) to gain 0.000000001% of the execution time will not make your boss happy.
Trust me on this.
Additionally, there is quite a bit of thought behind the process balancing incoming requests across your cluster. Higher-level constructs take care of this critical requirement for you, and do so with with considerable efficiency.
The analogy I often use is that you use Solr rather than Lucene to take advantage of all the work the Solr folks have done. Sure, it’s possible to bypass Solr completely, but a number of very intelligent people have worked very hard to allow you to solve your problem from a higher level, faster, and with less work. If you really, really, really need to work at a lower level it’s available. If I were your manager in this case, I would ask you to show why it’s worth the engineering time commitment before approving the effort.
Feel free if you insist, but consider this fair warning that trying to do so is:
- A good way to go mad.
- A good way to have to maintain code that you do not need to maintain.
- A good way to miss the next sprint milestone.
Let’s take these one at a time
A good way to go mad
The Solr Streaming Expression implementation is complex. It enables powerful, albeit complex, functionality. There are maybe a dozen people on the planet who understand it all in detail.
Chances are, if you’re reading this blog for hints, you aren’t one of them.
A good way to have to maintain code…
The streaming functionality from the basic ‘/export’ handler through Streaming Expressions and ParallelSQL is evolving extremely quickly. Trying to work with the low-level code means that if the low-level code changes at all, you’ll have to revisit your code. This is not a valuable use of your time.
A good way to miss the next sprint deadline
Actually I’d say that it’s a good way to miss several sprint deadlines, you’ll see why in a bit.
Here’s the easy way
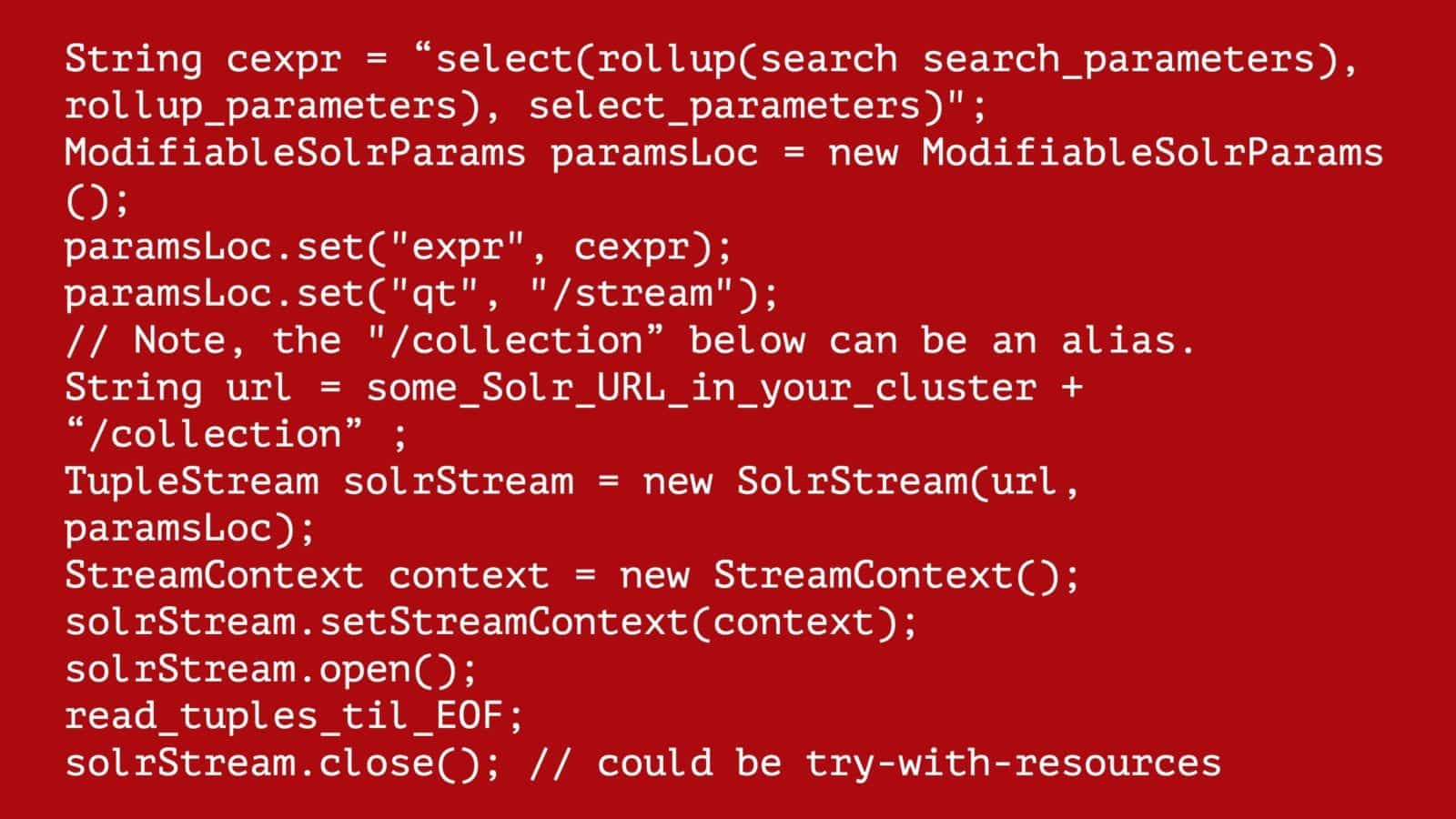
Let’s start with our recommended approach. Here’s a Streaming Expression (simplified, lots of details left out for clarity):
select(rollup(search search_parameters), rollup_parameters), select_parameters)
Say you’ve used the UI to build up to the expression and you’re satisfied with it. To construct the simple version, it looks like this:
String cexpr = "select(rollup(search search_parameters), rollup_parameters), select_parameters)";
ModifiableSolrParams paramsLoc = new ModifiableSolrParams();
paramsLoc.set("expr", cexpr);
paramsLoc.set("qt", "/stream");
// Note, the "/collection" below can be an alias.
String url = some_Solr_URL_in_your_cluster + "/collection" ;
TupleStream solrStream = new SolrStream(url, paramsLoc);
StreamContext context = new StreamContext();
solrStream.setStreamContext(context);
solrStream.open();
read_tuples_til_EOF;
solrStream.close(); // could be try-with-resources
The ‘cexpr’ above can be constructed any way you please, it’s just a string after all. Whatever works with curl or the expressions bit of the admin UI.
Here’s the hard way
Contrast the above with the code you’d have to write (and maintain!) if you tried to build up all this yourself (and I’m leaving out a great deal of code). By the way, after running into several problems we decided to make it easy on ourselves [1]. I’m using the same shorthand as above…
StreamExpression expression;
StreamContext streamContext = new StreamContext();
SolrClientCache solrClientCache = new SolrClientCache();
// What's this? Why do I need it? If I don't set it I'll get an NPE
streamContext.setSolrClientCache(solrClientCache);
// what if I can't get to the ZK host since I can't tunnel to it if I need to?
StreamFactory factory = new StreamFactory().
withCollectionZkHost(collection_name, ZK_ensemble_string);
// Wait, is /export right? Maybe it's /stream? Well, yes it should be /stream.
// But what if it changes in the future?
// well, the below works, but is it correct? Hmmm, this is the search part,
// really the third level of select(rollup(search...)...)
expression = StreamExpressionParser.parse(search_expression);
CloudSolrStream searchStream = null;
RollupStream rollupStream = null;
SelectStream selectStream = null;
TupleStream stream = null;
// OK, let's set the innermost stream up.
try {
searchStream = new CloudSolrStream(expression, factory);
searchStream.setStreamContext(streamContext);
// What is this about? I have to change the metrics
// time I change the expressions I want to collect?
// this is an example of how to instantiate
// "rollup_parameters".
Bucket[] buckets = {new Bucket("something")};
Metric[] metrics = {
new SumMetric("some_field1"),
new MinMetric("some_field2"),
new CountMetric()};
// I need to revisit this if the expression changes?
rollupStream = new RollupStream(searchStream, buckets, metrics);
rollupStream.setStreamContext(streamContext);
// Set the rest of the parameters I need to set for rollupStream.
// What are they? How do I do that?
// Do I need to revisit this if the select changes?
// Now wrap the above in the outermost SelectStream
selectStream = new SelectStream(rollupStream, more_parameters_what_are_they);
// Is it OK to set the streamContext to the same underyling object for all
// three streams?
selectStream.setStreamContext(streamContext);
// set any additional necessaries.
stream = selectStream;
} catch (Exception e) {
// handle all of the bits I need to here. Closing the streams?
// Are they open? The usual issues with catch blocks.
}
// Oops, I caught the exception above, I guess I have to test here for
// whether the stream is null.
try {
stream.open();
read_tuples_til_EOF;
} catch (Exception e) {
//report an error
} finally {
// try/catch in a finally block just in case
// something goes wrong.
if (stream != null) {
try {
stream.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
// Hmmm, what is this solrClientCache anyway?
// Oh, I set this cache for all the streams I created,
// do I have to close it three times (no)?
// All I know experimentally is that my SolrJ program will hang
// for 50 seconds if I don't do this when I try to exit.
// I guess I could look through all the code and understand this
// in more detail, but the boss wants results.
solrClientCache.close();
Ok, the above is a little over the top but you get the point. There are many considerations involved in getting the entire Streaming Expressions code to perform the miracles that it does. And rather than have all this done for you, you’ll have to adapt your code for every change in the Streaming Expression; say you want to add the “max(some_field3”), or write some generic builder. And do this once you have already worked out the expression you want in the first place. That’s already all done for you by the simple pattern above.
Were I to put on my curmudgeon hat, I’d claim that it would be nice if these low-level constructs were concealed from SolrJ clients. SolrJ is what’s used for the communication between the Solr node, so this level must be exposed.
We never did make the above code work completely. Eventually we ran into another layer of difficulty. Whether it was because the code used the “qt=/export” rather than “qt=/stream”, or some such — we had some other mistake or the moon wasn’t full I don’t know. What I do know is that when I was provided with the recommended solution and started thinking about maintaining “roll your own” I realized that the benefit of using the recommended pattern far, far outweighed rolling our own. Not only from a “let’s get something out the door” perspective, but also from a maintainability perspective.
Rolling your own is unnecessary. The recommended pattern bypasses all of the complexity and leverages the work of the people who really understand the underpinnings of Streaming Expressions. I strongly recommend that you use the recommended pattern and only venture to lower-level code patterns if you have a compelling need. And, quite frankly, I’m having difficulty dreaming up a compelling need.
Other gotchas
And then there are the “extra” problems:
- The above code gets the ZK ensemble. Seems simple enough. But what if I’m using some deployment that doesn’t let me access the ZooKeeper ensemble? I can use http requests via tunneling much more easily
- Admittedly the Streaming Expression strings are “interesting” to construct. Using the recommened pattern allows you to use arbitrary Streaming Expressions rather than having to revisit your code every time the expression changes.
Conclusion
Some very smart people have spent quite a bit of time making this all work, handling the gritty details and are maintaining this going forward. Take advantage of their hard work and use the recommended pattern!
[1] I want to particularly call out Joel Bernstein, one of the main authors of the Streaming concept who has been extremely generous when it comes to answering my questions as well as questions on the user’s list. Let’s just say he makes me look a lot smarter! I haven’t totaled up how much the bar tab I owe him amounts to, but it’s sizeable.
LEARN MORE
Contact us today to learn how Lucidworks can help your team create powerful search and discovery applications for your customers and employees.