Using Solr Tagger for Improving Relevancy

Full-text documents and user queries usually contain references to things we already recognize, such as names of people, places, colors, brands, and other domain-specific concepts. Many systems overlook this important, explicit, and specific information which ends up treating the corpus as just a bag of words. Detecting, and extracting, these important entities in a semantically richer way improves document classification, faceting, and relevancy.
Solr includes a powerful feature, the Solr Tagger. When the system is fed a list of known entities, the tagger provides details about these things in text. This article steps through using the Solr Tagger to tag cities, colors, and brand, illustrating how it could be adapted to your own search projects.
What Is the Solr Tagger?
Entity recognition isn’t new, but prior to Solr 7.4, there was a lot of Python and hand-wavy stuff.This got the job done but it wasn’t easy. Then Solr Tagger was introduced with the release of Solr 7.4 an incredible piece of work by Solr committer extraordinaire, David Smiley.
The Solr Tagger takes in a collection, field name, and a string and returns occurrences of tags that occur in a piece of text. For instance if I ask the tagger to process “I left my heart in San Francisco but I have a New York state of mind” and I’ve defined “San Francisco” and “New York” as both cities, Solr will say so:
"response":{"numFound":2,"start":0,"docs":[
{
"id":"5128542",
"name":["San Francisco"],
"type": "city",
"countrycode":"US"}]
},
{
"id":"5128512",
"name":["New York"],
"type":"city",
"countrycode":"US"}]
}
excerpt of sample output
Solr’s tagger is a naive tagger and doesn’t actually do any Natural Language Processing (NLP), it can still be used as part of a complete NER or ERD (Entity Recognition and Disambiguation) system or even for building a question answering or virtual assistant implementation.
How the Solr Tagger Works
The Solr Tagger is a Solr endpoint that uses a specialized collection containing “tags” that are defined text strings. In this case, “tags” are pointers to text ranges (substrings; start and end offsets) within the provided text. These text ranges match _documents_, by way of the specified tagging field. Documents, in the general Solr sense, are simply a collection of fields. In addition to tags, users can define Metadata associated with the tag. For example, metadata for tagged “cities” might include the country code, population, and latitude/longitude.
The Solr Reference Guide section for the Solr Tagger has an excellent tutorial that is easy to run on a fresh Solr instance. We encourage you to go through that thorough tutorial first since we’ll be building upon that same tutorial data and configuration below.
For a deep dive into the inner workings of the Solr Tagger inner workings, tune into David Smiley’s presentation from a few years ago:
Tagging Entities
Expanding upon the Solr Tagger tutorial with cities, now we’re going to add additional kinds of entities.
Adding a single type field to the documents in the tagger collection gives us the ability to tag other types of things, like colors, brands, people names, and so on. Having this and other type-specific information on tagger documents also allows filtering the set of documents available for tagging. For example, the type, and type-specific fields can facilitate tagging of only cities within a short distance of a specified location.
Using Fusion, we first get the basic geonames Solr Tagger tutorial data placed into Fusion’s blob store and create a datasource to index it (there’s a few other sample entities in another datasource that we’ll explore next):
Before starting this datasource we modify the schema and configuration using Fusion’s Solr Config editor, according to the Solr Tagger documentation. While the Geonames cities data contains latitude and longitude, the tutorial’s simple indexing strategy leaves them as separate fields. Solr’s geospatial capabilities work with a special combined “lat/lon” field, which must be provided as a single combined comma-separated string. Solr’s out of the box schema provides a dynamic *_p (for “point”) field. In Fusion, the handy field mapping stage provides a way to set a field with a template (StringTemplate) trick, as shown for location_p here:

Also, the type field is set to literally “city” for every document in this data source, containing only cities. We’ll bring in other “types” of entities shortly, but let’s first see what the type and location_p fields give us now:
http://localhost:8983/solr/entities/tag?overlaps=NO_SUB&tagsLimit=100&fl=id,name,*_s&wt=json&indent=on&matchText=true&json.nl=map
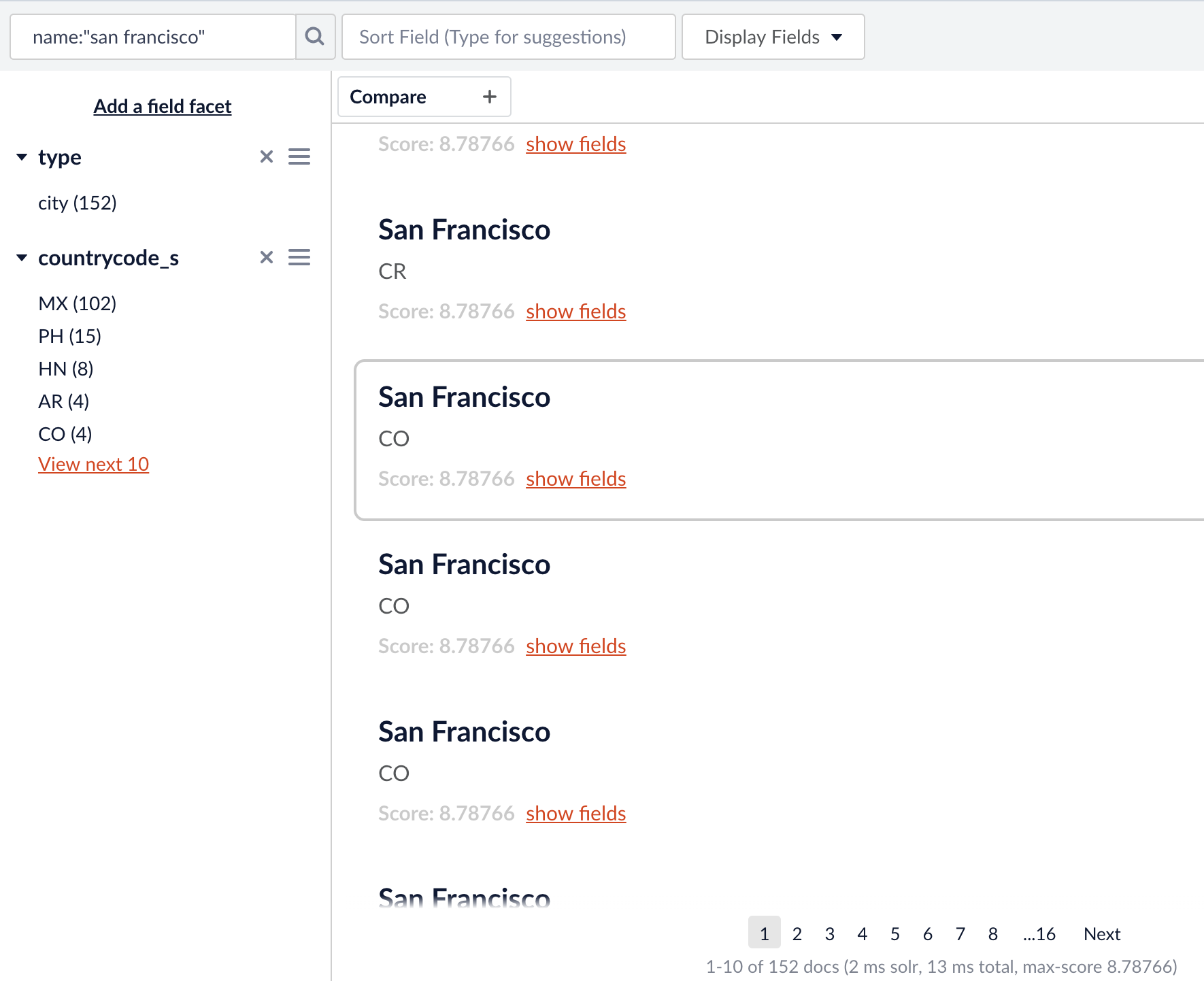
“san francisco” is the only known string to the `entities` collection in that text. There are 42 cities known exactly as “San Francisco” in this collection. (there are many more that have “San Francisco” as part of its name, as shown in the Fusion Query Workbench below)
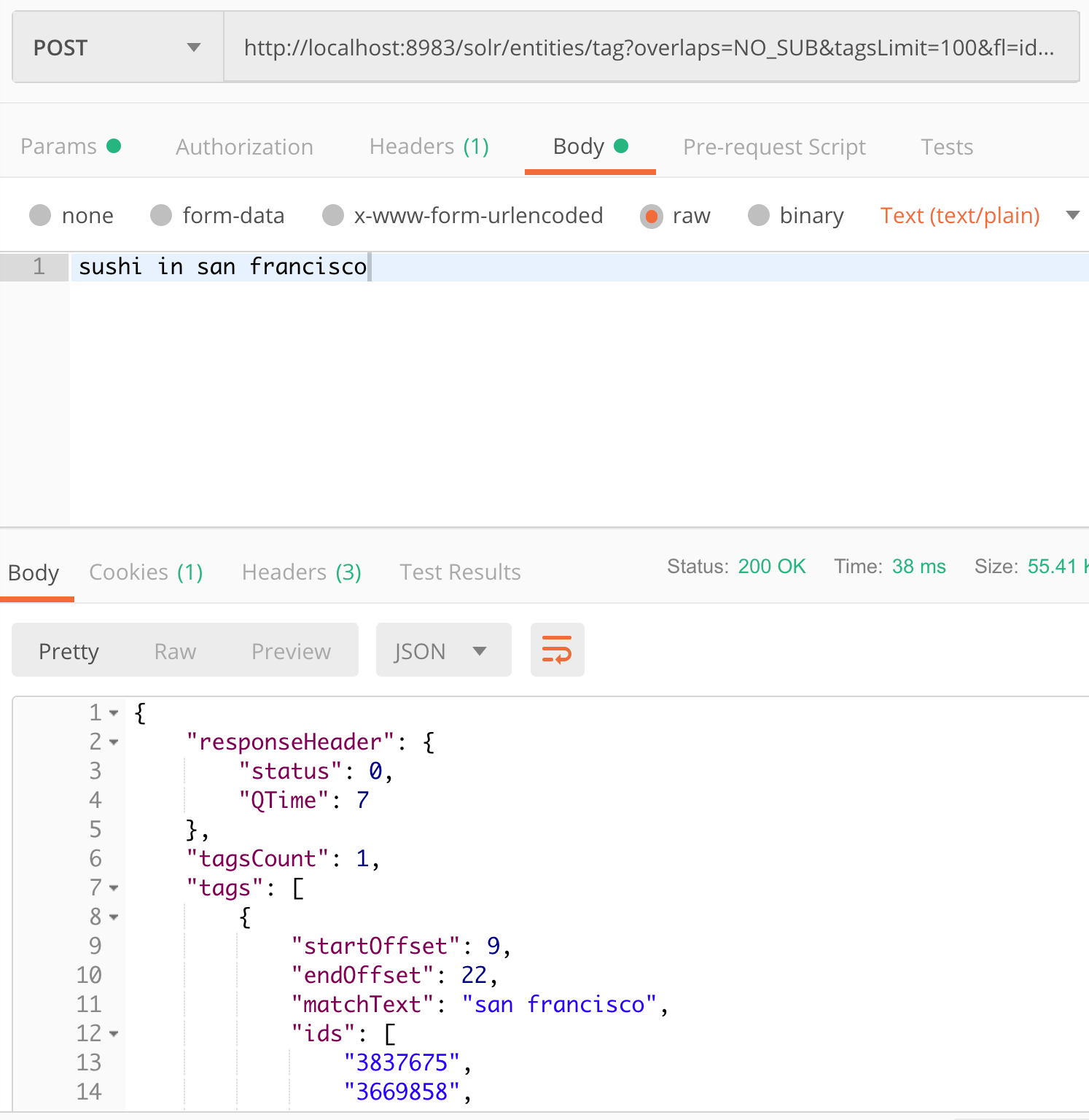
Lots of “San Francisco”s, but only 42 with exact match, and thus taggable with the current configuration.
Visualize Tags While Typing
The final touches here are to allow tagging of text while typing it. A simple (VelocityResponseWriter) proof of concept interface was created to quickly wire together a text box, a call to the Solr Tagger endpoint, and display the results. Typing that same phrase, the Solr Tagger response is shown diagnostically, along with a color-coded view of the tagged string. Tagged cities are color-coded yellow:

Assuming we are in San Francisco, California, at the Lucidworks headquarters, and we want to locate nearby sushi restaurants, we provide a useful bit of context: our location. Narrowing the tagging of locations to a geographic distance from a particular point, we can narrow down the available cities used to tag the string. When the location-aware context is provided, by checking the “In SF?” box, the tagger is sent a filter (fq) of:
(type:city AND {!geofilt sfield=location_p}) OR (type:* -type:city)
This geo-filters on cities within 10km (d=10) of the location provided (the pt parameter, specifying a lat/lon point).
Tagging More Than Locations
So far we’ve still only tagged cities. But we’ve configured the Tagger collection to support any “type” of thing. To show how additional types work, a few additional types are brought in similarly (a CSV in the Fusion blobstore, and a basic data source to index it):
id,type,name color-1,color,White color-2,color,Blue brand-1,brand,White Linen
Suppose we now tag the phrase “Blue White Linen sheets” (add “in san francisco” for even more color):

The sub-string “white” is ambiguous here, as it is a color and also part of “white linen” (a brand). There’s a parameter to the tagger (overlaps) that controls how to handle overlapping tagged text. The default is NO_SUB, so that no overlapping tags are returned, only the outermost ones, which causes “white linen” to be tagged as a brand, not as a brand with a color name inside it.
End Offset – What’s Next?
Well, that’s cool – we’re able to tag substrings in text and associate them with documents. The real magic materializes when the tagged information and documents are put to use. Using the tagged information, for example, we can extract the entities from a query string and turn them into filters.
For example, if someone searched for “blue shoes,” and blue is tagged as a color, we can find it with the tagger and extract it from the query string and add it as a filter query. Effectively, we can convert “blue shoes” to q=shoes&fq=color_s:blue with just a few lines of string manipulation code. This changes the structure of the query and makes it more relevant. For one, we’re looking for blue in a color field instead of the document or product description generally. For two, it can be more efficient for longer queries which generally get carried away by spreading terms across all fields regardless of whether the query terms actually make sense for those fields.
Taking tagging to another level, Lucidworks Chief Algorithms Officer, Trey Grainger, presented Natural Language Search with Knowledge Graphs at the recent Haystack Conference. In this presentation, Trey leveraged the Solr Tagger to tag not only tag things (“haystack” in his example), but also command/operator words (“near”). The Solr Tagger provides a necessary piece to natural language search.
Try It Now on Lucidworks Labs

The Solr Tagger example described above has been packaged into a Lucidworks Lab, making it launchable from https://de.lucidworks.com/labs/apps/tagger/
Erik explores search-based capabilities with Lucene, Solr, and Fusion. He co-founded Lucidworks, and co-authored ‘Lucene in Action.’
LEARN MORE
Contact us today to learn how Lucidworks can help your team create powerful search and discovery applications for your customers and employees.