Improving the Search Experience With Solr Suggester
How to configure and optimize Apache Solr's suggester component including both FST-based and AnalyzingInfix approaches (and a few 'gotchas' along the way).

How would you like to have your user type “energy”, and see suggestions like:
- Energa Gedania Gdansk
- Energies of God
- United States Secretary of Energy
- Kinetic energy
The Solr/Lucene suggester component can make this happen quickly enough to satisfy very demanding situations. This blog is about how to configure the suggesters to get this kind of response, and also talk about some of the “gotchas” that exist. One note, the first two above are from an FST-based suggester, and the second two are are from an AnalyzingInfix suggester. More on these suggester implementations later.
There’s been a new suggester in town for a while, thanks to some incredible work by some of the Lucene committers. Along about Solr 4.7 or so support made its way into Solr so you could configure these in solrconfig.xml. At the end of this post are links to several backgrounders that are interesting to me at least.
The huge difference with these suggesters is that they return the whole field where the input is found! [1]. This is much different than term-based suggestions because the user sees coherent suggestions for query terms from documents in your index. The implication here, of course, is that by and large these are not suitable for large text fields. In fact, if you throw > 32K fields at these, they error out. See [1] for the exception.
How We Used to Make Suggestions:
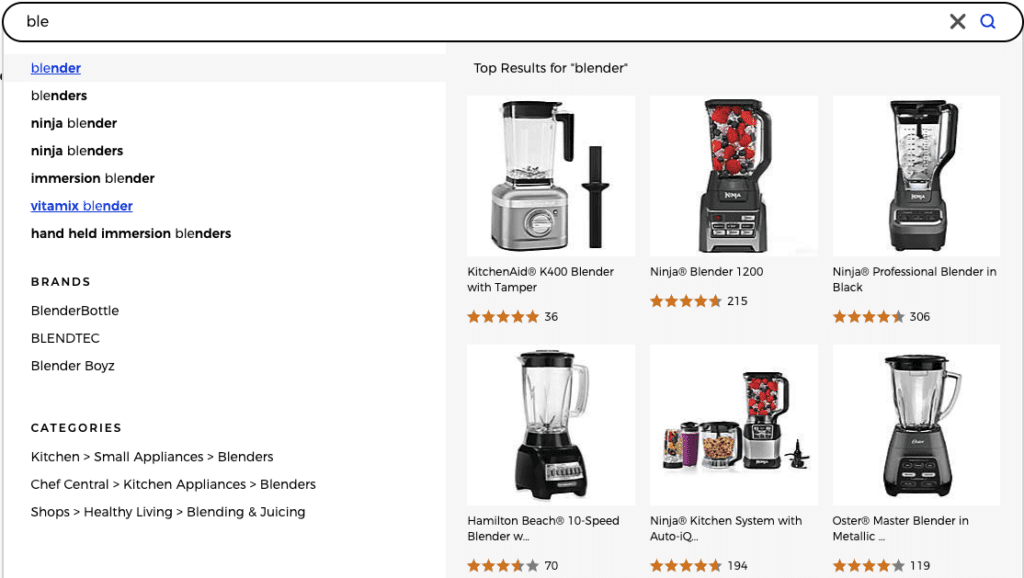
Autosuggest has been around in various more or less sophisticated forms for a while. The idea is that based on partial input, suggestions for query terms typed so far are returned, think “type ahead”. The approaches Apache Solr has used in the past usually centered around terms considered in isolation. There were a number of tricks we could utilize to make it seem like it was suggesting in a more context-sensitive way, all of which took effort and produced results that were of varying quality.
The Suggester Requires Care and Feeding:
There are two different “styles” of suggester I’ll touch on now, FST-based suggesters and AnalyzingInfix suggesters. Each has a different suggester implementation. The suggester implementation you select has significant implications for what is suggested and how it is built.
What you do care about is that the two approaches give significantly different results. It’s worth repeating that these suggesters suggest whole fields as suggestions for query terms! This is radically different than term-based suggestions that consider terms in isolation. [1]
The major distinction between the two styles of a suggester implementation is:
- FST-based suggesters typically operate on the beginnings of fields, although you can remove stopwords.
- AnalyzingInfix suggesters can make suggestions where suggest.q is something from the middle of the field.
FST-Based Suggesters:
The underlying suggester implementation builds these things called FSTs, or Finite State Transducers. Oh my aching head. I just accept that these are magic. The blogs linked at the end of this article will give you some insight into the process of coding these. “Many beers and much coffee” was mentioned as I remember.
AnalyzingInfix Suggesters:
The underlying framework is a “sidecar” Lucene index separate from your main index. In fact, if you specify the “indexPath” parameter when defining these you’ll see, well, a Lucene index in the path you specify.
The cost of all this goodness:
Both styles of suggesters have to be “built”. In the FST-based suggester implementations, the result is a binary blob that can optionally be stored on disk. The AnalyzingInfix suggesters have to have their underlying Lucene index, which can also be optionally stored on disk. You build them either automatically or by an explicit command (browser URL, curl command or the like). The result can be stored to disk in which case they’ll be re-used until their built again, even if documents are added/updated/removed from the “regular” index.
Note the sweet spot here. These suggesters are very powerful. They’re very flexible. But TANSTAAFL, There Ain’t No Such Thing As A Free Lunch. These particular suggesters are, IMO, not suitable for use in any large corpus where the suggestions have to be available in Near Real Time (NRT). The underlying documents can be updated NRT, but there’ll be a lag before suggestions from the new documents show up, i.e. until you rebuild the suggester. And building these is expensive on large indexes.
In particular, any version that uses a “DocumentDictionaryFactory” reads the raw data from stored field when building the suggester!
That means that if you’ve added 1M docs to your index and start a build, each and every document must:
- Be read from disk
- Be decompressed
- Be incorporated into the suggester’s data structures.
- A consequence of this is that the field specified in the configs must have stored=”true” set in your schema.
As you can imagine, this can take a while and is not to be done lightly. “A while” is almost 10 minutes on an 11M doc Wikipedia dump on a Mac Pro.
I’ll call out one more thing in particular about DocumentDictionaryFactory, the field from which it’s built must have stored=”true” set in the schema.
Suggester definitions that use file-based sources (FileDictionaryFactory rather than DocumentDictionaryFactory) are much quicker to build, but require curating the “official list” of suggestions rather than using fields from documents in the index. Use whichever best suits your needs.
So Where Exactly Does That Leave Us?
These suggester implementations are most suitable for situations where the suggestions don’t have to be absolutely up-to-date, or for a curated (possibly hand-edited) set of suggestions.
When you are using this suggestion infrastructure, you probably want to pay particular attention to these:
-
- The “lookupImpl” parameter defines the how the suggester component is gets data to suggest, see Mike McCandless’ blog below. The two that I’m using for this illustration are:
- The FuzzyLookupFactory that creates suggestions for misspelled words in fields.
- The AnalyzingInfixLookupFactory that matches places other than from the beginnings of fields.
- The parameter for the directory for storing the suggester structure after it’s built should be specified. This means that when you issue the build command, the result gets stored in binary form on disk and is available without rebuilding. So the next time you start up your Solr, the data is loaded from disk ready to go. The load is very fast. This parameter is:
- “storeDir” for the FuzzyLookupFactory
- “indexPath” for theAnalyzingInfixLookupFactory
- The “buildOnStartup” parameter should be set to “false”. Really. This can lead to very long startup times, many minutes on very large indexes. Do you really want to re-read, decompress and and add the field from every document to the suggester every time you start Solr! Likely not, but you can if you want to.
- The “buildOnCommit” parameter should be set to “false”. Really. Do you really want to re-read, decompress and and add the field from every document to the suggester every time you commit! Likely not, but you can if you want to.
- About “weightField“. Currently (Solr 4.10 and Solr 5.0) the fact that you must have “weightField” specified is just over-zealous checking. It will be removed as a requirement in Solr trunk and 5.1. It’s hacky but it works to just define a float field in your schema, never mention it again and use it or the “weightField”. Even if you never add that field to any document, the code compensates.
- The “suggestAnalyzerFieldType” This can be as complex as you want, but I’d start simple, see the example at the end of this blog.
- This fieldType is completely independent from the analysis chain applied to the field you specify for your suggester. It’s perfectly reasonable to have the two fieldTypes be much different.
- Speaking of garbage… This is a prime candidate for cleanup on the part of the indexing program. Garbage In/Garbage Out comes to mind.
- The “string” fieldType should probably NOT be used. Whenever a “string” type is appropriate for the use case, the TermsComponent will probably serve as well and is much simpler.
- The “lookupImpl” parameter defines the how the suggester component is gets data to suggest, see Mike McCandless’ blog below. The two that I’m using for this illustration are:
Here’s a basic configuration:
<searchComponent name="suggest" class="solr.SuggestComponent">
<lst name="suggester">
<str name="name">mySuggester</str>
<str name="lookupImpl">FuzzyLookupFactory</str>
<str name="storeDir">suggester_fuzzy_dir</str>
<!-- Substitute these for the two above for another "flavor"
<str name="lookupImpl">AnalyzingInfixLookupFactory</str>
<str name=”indexPath”>suggester_infix_dir</str>
-->
<str name="dictionaryImpl">DocumentDictionaryFactory</str>
<str name="field">title</str>
<str name="suggestAnalyzerFieldType">suggestType</str>
<str name="buildOnStartup">false</str>
<str name="buildOnCommit">false</str>
</lst>
</searchComponent>
<requestHandler name="/suggesthandler" class="solr.SearchHandler" startup="lazy" >
<lst name="defaults">
<str name="suggest">true</str>
<str name="suggest.count">10</str>
<str name="suggest.dictionary">mySuggester</str>
</lst>
<arr name="components">
<str>suggest</str>
</arr>
</requestHandler>
Fine, How Do I Use the Suggester?

First, I really want to give some warnings, just some bullet points to keep in mind:
- Consider using Solr 5.1+ as the suggesters get built every time Solr starts on earlier versions, possibly leading to very long startup times.
- Building can be a lengthy process.
- Building is CPU intensive.
- Be cautious about setting buildOnStartup or buildOnCommit to “true”, see above.
- Log messages about not having built your suggesters or stack traces indicating the same are benign, they’ll go away when you build your suggesters.
- Some of the literature (I’ll fix what I can find) suggests that you can use copyField directives to add a bunch of terms from different fields to a single field and generate suggestions from the destination field. This is not true until Solr 5.0, see: LUCENE-5833. To copy multiple fields to one field, the destination must be multiValued, and the suggesters can’t be built from multiValued fields before Solr 5.0.
Finally, Actually Getting Suggestions:
OK, with all that out of the way, then actually using this is very simple. Assume all the URLs below start with the collection you want to have suggestions returned from. You can issue these commands from a browser, curl, SolrJ etc..
- Build the suggester (Set the “storeDir” or “indexPath” parameter if desired). Issue …/suggesthandler?suggest.build=true. Until you do this step, no suggestions are returned and you’ll see messages and/or stack traces in the logs.
- Ask for suggestions. As you can see above, the suggester component is just a searchComponent, and we define it in a request handler. Simply issue “…/suggesthandler?suggest.q=whatever“.
There, that’s it. Here are some examples from a Wikipedia dump, the “title” field with the fieldType below.
Some Examples From FuzzyLookupFactory:
- suggest.q=enrgy
- Energy
- Energy balance
- Energy Corporation
- suggest.q=energy
- Energa Gedania Gdansk
- Energies of God
- suggest.q= quantity
- Quantitative analysis
- Quantitative structure-property relationship
- suggest.q=technical analysis
- Technical analysis
- Technical analysis software
- suggest.q=technical ana
- Technical analysis
- Technical and further education
Some Examples From AnalyzingInfixLookupFactory:
- suggest.q=enrgy
- no suggestions returned
- suggest.q=energy
- United States Secretary of Energy
- Kinetic energy
- suggest.q=quantity
- Dimensionless quantity
- Quantity theory of money
- suggest.q=technical analysis
- Technical analysis
- Resistance(technical analysis)
- suggest.q=technical ana
- Technical analysis software
- Resistance (technical analysis)
You can see that the two suggester implementations do different things. The AnalyzingInfixSuggester highlights the response as well as gets terms “in the middle”, but doesn’t quite do spelling correction. The Fuzzy suggester returned suggestions for misspelled “enrgy” whereas Infix returned no suggestions. Fuzzy also assumes that what you’re sending as the suggest.q parameter is the beginning of the suggestion.
There are knobs I haven’t turned here, such as:
- weightField: This allows you to alter the importance of the terms based on another field in the doc.
- threshold: A percentage of the documents a term must appear in. This can be useful for reducing the number of garbage returns due to misspellings if you haven’t scrubbed the input.
There are several other suggester implementations I didn’t include above:
- WFSTLookup: a suggester component that offers more fine-grained control over results ranking than FST
- TSTLookup: “a simple, compact trie-based lookup”. Whatever that means.
- JaspellLookup: see the Jaspell
The implementations just above all build and search their respective suggesters somewhat differently. In addition, there are two important sources for the terms:
- Field-based. This source uses fields from the documents in the index to make the suggester. The field must have “stored=true” set in its field definition in schema.xml.
- File-based. This source takes the suggestions from an external file, giving you complete control over what is suggested (and weights for each) and in all probability building the suggester very quickly.
A Random Musing:
I use the 11M Wikipedia dump for my examples. “When I was a boy”, well actually we didn’t have the capability to do this at all. Maybe “a few short years ago” is a better way to say it. Anyway, “back then”, 11M docs was a large collection. Now its something I build regularly just for fun. Time does march on.
Multiple Suggesters:
It takes a little bit of care, but it’s perfectly reasonable to have multiple suggester components configured in the same Solr instance. In this example, both of my suggesters were defined as separate request handlers in solrconfig.xml, giving quite a bit of flexibility in what suggestions are returned by choosing one or the other request handler.
Suggester Size:
Usually I’m very reluctant to try to gauge the memory requirements from the size on disk. In this case, at least for the Fuzzy suggester, I expect the in-memory size to closely approximate the size on disk for my 11M titles:
- Fuzzy: 256M
- AnalyzingInfix: 811M, although this is a Lucene index and in this case I didn’t try to optimize for size.
Parting Thoughts:

The suggester infrastructure is somewhat complex, and requires some care and feeding. The best way to figure out “which suggester is right for me” is to experiment.
Here are some of the bits in the “it depends” category; choose which ones apply to your situation:
- In distributed environments (i.e. SolrCloud), consider a suggest-only collection, possibly with replicas rather than have each and every replica in your “main” index have its own suggester (and build process). Not to mention that getting suggestions from a single replica is bound to be faster than getting distributed suggestions.
- Curate your suggestions. If you’re not just using the TermsComponent, then you’ve decided that high-quality suggestions are worth the effort. You can make them even more useful to your users if you take some care to only put high-quality source material in the suggester. This can reflect the specific domain knowledge you have that Solr doesn’t, and you can go as crazy as you want with, say, semantic analysis to guide users to high-value documents. Given that you can specify weights to the suggestions, the possibilities are endless.
- TANSTAAFL: There Ain’t No Such Thing As A Free Lunch. We’d all like to just push a button and have Solr “do the right thing” by magic. Unfortunately, the Do What I Mean (DWIM) version of Solr is still in the planning stages. And will be long after I retire. Expect to spend some development time for getting suggestions right.
- Don’t over-engineer. The above bullet notwithstanding, and borrowing from the eXtreme Programming folks, “do the simplest thing that could possibly work”. In this case, define a simple suggester and see if that’s “good enough for this phase”, whatever “this phase” is. If it is, use it and stop. You can refine it later.
- As of Solr 5.0, you can have the suggester work from multValued fields. Suggestions are returned from within the individual value! So you could quite reasonably copy a bunch of short fields into a “suggest” field and build your suggester from that field. Let’s say you added two values to a field in a doc, “my value 3” and “another entry”. “suggest.q= value” (AnalyzingInfixSuggester) would return”my value 3″ .
This has rambled on long enough, so happy suggesting!
A Few Useful Links:
Mike McCandless’ discussions of suggesters:
- A long time ago in the early hours of the morning: Early history.
- FST based suggesters are fast.: Lucene fuzzy query 100 times faster.
- Infix (aka, not necessarily starting letters matched): AnalyzingInfixSuggester.
- Finite State Transducers: Finite State Transducers In Lucene.
You should really have a copy of the Solr Reference Guide on your machine and be searching that locally. You can download the whole thing (or older versions) as a single PDF from the upper-left corner of this page: Solr Reference Guide. Since much of this blog is about Solr 5.1, though, you’ll want to use the on-line version until Solr 5.1 is released.
My simple analyzer for the AnalyzingFieldType, removing all non alphanumerics and making my suggester case-insensitive. NOTE: even though the analysis is case-insensitive, the suggestions returned still have their original case:
<fieldType name="suggestTypeLc" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<charFilter class="solr.PatternReplaceCharFilterFactory" pattern="[^a-zA-Z0-9]" replacement=" " />
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
[1] I’m cheating a little here, the FreeTextLookupFactory will suggest terms in isolation but this post has enough distractions as it is.
This post originally published on March 24, 2015.
LEARN MORE
Contact us today to learn how Lucidworks can help your team create powerful search and discovery applications for your customers and employees.