Solr as an Apache Spark SQL DataSource
Part 1 of 2: Read Solr results as a DataFrame
This post is the first in a two-part series where I introduce an open source toolkit created by Lucidworks that exposes Solr as a Spark SQL DataSource. The DataSource API provides a clean abstraction layer for Spark developers to read and write structured data from/to an external data source. In this first post, I cover how to read data from Solr into Spark. In the next post, I’ll cover how to write structured data from Spark into Solr.
To begin, you’ll need to clone the project from github and build it using Maven:
git clone https://github.com/Lucidworks/spark-solr.git cd spark-solr mvn clean package -DskipTests
After building, run the twitter-to-solr example to populate Solr with some tweets. You’ll need your own Twitter API keys, which can be created by following the steps documented here.
Start Solr running in Cloud mode and create a collection named “socialdata” partitioned into two shards:
bin/solr -c && bin/solr create -c socialdata -shards 2
The remaining sections in this document assume Solr is running in cloud mode on port 8983 with embedded ZooKeeper listening on localhost:9983.
Also, to ensure you can see tweets as they are indexed in near real-time, you should enable auto soft-commits using Solr’s Config API. Specifically, for this exercise, we’ll commit tweets every 2 seconds.
curl -XPOST http://localhost:8983/solr/socialdata/config
-d '{"set-property":{"updateHandler.autoSoftCommit.maxTime":"2000"}}'
Now, let’s populate Solr with tweets using Spark streaming:
$SPARK_HOME/bin/spark-submit --master $SPARK_MASTER --conf "spark.executor.extraJavaOptions=-Dtwitter4j.oauth.consumerKey=? -Dtwitter4j.oauth.consumerSecret=? -Dtwitter4j.oauth.accessToken=? -Dtwitter4j.oauth.accessTokenSecret=?" --class com.lucidworks.spark.SparkApp ./target/spark-solr-1.0-SNAPSHOT-shaded.jar twitter-to-solr -zkHost localhost:9983 -collection socialdata
Replace $SPARK_MASTER with the URL of your Spark master server. If you don’t have access to a Spark cluster, you can run the Spark job in local mode by passing:
--master local[2]
However, when running in local mode, there is no executor, so you’ll need to pass the Twitter credentials in the spark.driver.extraJavaOptions parameter instead of spark.executor.extraJavaOptions.
Tweets will start flowing into Solr; be sure to let the streaming job run for a few minutes to build up a few thousand tweets in your socialdata collection. You can kill the job using ctrl-C.
Next, let’s start up the Spark Scala REPL shell to do some interactive data exploration with our indexed tweets:
cd $SPARK_HOME ADD_JARS=$PROJECT_HOME/target/spark-solr-1.0-SNAPSHOT-shaded.jar bin/spark-shell
$PROJECT_HOME is the location where you cloned the spark-solr project.
Next, let’s load the socialdata collection into Spark by executing the following Scala code in the shell:
val tweets = sqlContext.load("solr",
Map("zkHost" -> "localhost:9983", "collection" -> "socialdata")
).filter("provider_s='twitter'")
On line 1, we use the sqlContext object loaded into the shell automatically by Spark to load a DataSource named “solr”. Behind the scenes, Spark locates the solr.DefaultSource class in the project JAR file we added to the shell using the ADD_JARS environment variable.
On line 2, we pass configuration parameters needed by the Solr DataSource to connect to Solr using a Scala Map. At a minimum, we need to pass the ZooKeeper connection string (zkHost) and collection name. By default, the DataSource matches all documents in the collection, but you can pass a Solr query to the DataSource using the optional “query” parameter. This allows to you restrict the documents seen by the DataSource using a Solr query.
On line 3, we use a filter to only select documents that come from Twitter (provider_s=’twitter’).
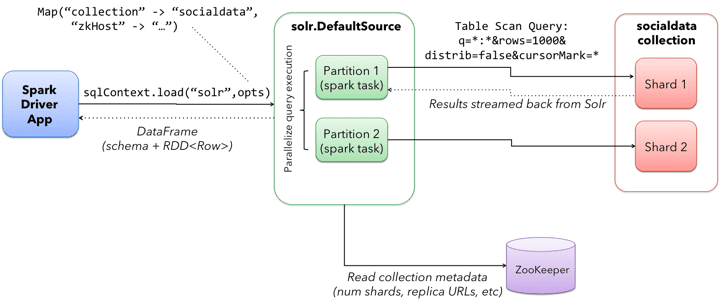
At this point, we have a Spark SQL DataFrame object that can read tweets from Solr. In Spark, a DataFrame is a distributed collection of data organized into named columns (see: https://databricks.com/blog/2015/02/17/introducing-dataframes-in-spark-for-large-scale-data-science.html). Conceptually, DataFrames are similar to tables in a relational database except they are partitioned across multiple nodes in a Spark cluster. The following diagram depicts how a DataFrame is constructed by querying our two-shard socialdata collection in Solr using the DataSource API:
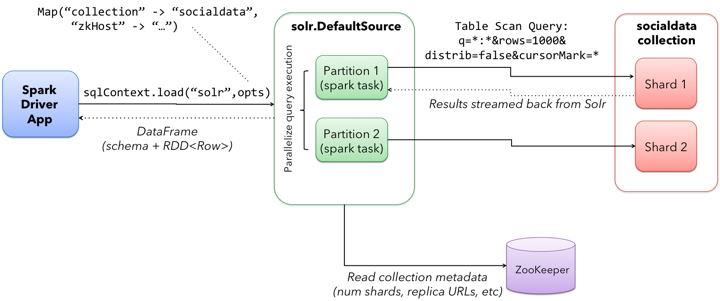
It’s important to understand that Spark does not actually load the socialdata collection into memory at this point. We’re only setting up to perform some analysis on that data; the actual data isn’t loaded into Spark until it is needed to perform some calculation later in the job. This allows Spark to perform the necessary column and partition pruning operations to optimize data access into Solr.
Every DataFrame has a schema. You can use the printSchema() function to get information about the fields available for the tweets DataFrame:
tweets.printSchema()
Behind the scenes, our DataSource implementation uses Solr’s Schema API to determine the fields and field types for the collection automatically.
scala> tweets.printSchema() root |-- _indexed_at_tdt: timestamp (nullable = true) |-- _version_: long (nullable = true) |-- accessLevel_i: integer (nullable = true) |-- author_s: string (nullable = true) |-- createdAt_tdt: timestamp (nullable = true) |-- currentUserRetweetId_l: long (nullable = true) |-- favorited_b: boolean (nullable = true) |-- id: string (nullable = true) |-- id_l: long (nullable = true) ...
Next, let’s register the tweets DataFrame as a temp table so that we can use it in SQL queries:
tweets.registerTempTable("tweets")
For example, we can count the number of retweets by doing:
sqlContext.sql("SELECT COUNT(type_s) FROM tweets WHERE type_s='echo'").show()
If you check your Solr log, you’ll see the following query was generated by the Solr DataSource to process the SQL statement (note I added the newlines between parameters to make it easier to read the query):
q=*:*& fq=provider_s:twitter& fq=type_s:echo& distrib=false& fl=type_s,provider_s& cursorMark=*& start=0& sort=id+asc& collection=socialdata& rows=1000
There are a couple of interesting aspects of this query. First, notice that the provider_s field filter we used when we declared the DataFrame translated into a Solr filter query parameter (fq=provider_s:twitter). Solr will cache an efficient data structure for this filter that can be reused across queries, which improves performance when reading data from Solr to Spark.
In addition, the SQL statement included a WHERE clause that also translated into an additional filter query (fq=type_s:echo). Our DataSource implementation handles the translation of SQL clauses to Solr specific query constructs. On the backend, Spark handles the distribution and optimization of the logical plan to execute a job that accesses data sources.
Even though there are many fields available for each tweet in our collection, Spark ensures that only the fields needed to satisfy the query are retrieved from the data source, which in this case is only type_s and provider_s. In general, it’s a good idea to only request the specific fields you need access to when reading data in Spark.
The query also uses deep-paging cursors to efficiently read documents deep into the result set. If you’re curious how deep paging cursors work in Solr, please read: https://de.lucidworks.com/post/coming-soon-to-solr-efficient-cursor-based-iteration-of-large-result-sets/. Also, matching documents are streamed back from Solr, which improves performance because the client side (Spark task) does not have to wait for a full page of documents (1000) to be constructed on the Solr side before receiving data. In other words, documents are streamed back from Solr as soon as the first hit is identified.
The last interesting aspect of this query is the distrib=false parameter. Behind the scenes, the Solr DataSource will read data from all shards in a collection in parallel from different Spark tasks. In other words, if you have a collection with ten shards, then the Solr DataSource implementation will use 10 Spark tasks to read from each shard in parallel. The distrib=false parameter ensures that each shard will only execute the query locally instead of distributing it to other shards.
However, reading from all shards in parallel does not work for Top N type use cases where you need to read documents from Solr in ranked order across all shards. You can disable the parallelization feature by setting the parallel_shards parameter to false. When set to false, the Solr DataSource will execute a standard distributed query. Consequently, you should use caution when disabling this feature, especially when reading very large result sets from Solr.
Not only SQL
Beyond SQL, the Spark API exposes a number of functional operations you can perform on a DataFrame. For example, if we wanted to determine the top authors based on the number of posts, we could use the following SQL:
sqlContext.sql("select author_s, COUNT(author_s) num_posts from tweets where type_s='post' group by author_s order by num_posts desc limit 10").show()
Or, you can use the DataFrame API to achieve the same:
tweets.filter("type_s='post'").groupBy("author_s").count().
orderBy(desc("count")).limit(10).show()
Another subtle aspect of working with DataFrames is that you as a developer need to decide when to cache the DataFrame based on how expensive it was to create it. For instance, if you load 10’s of millions of rows from Solr and then perform some costly transformation that trims your DataFrame down to 10,000 rows, then it would be wise to cache the smaller DataFrame so that you won’t have to re-read millions of rows from Solr again. On the other hand, caching the original millions of rows pulled from Solr is probably not very useful, as that will consume too much memory. The general advice I follow is to cache DataFrames when you need to reuse them for additional computation and they require some computation to generate.
Wrap-up
Of course, you don’t need the power of Spark to perform a simple count operation as I did in my example. However, the key takeaway is that the Spark SQL DataSource API makes it very easy to expose the results of any Solr query as a DataFrame. Among other things, this allows you to combine data from Solr with data from other enterprise systems, such as Hive or Postgres, to perform advanced data analysis tasks at scale. Another advantage of the DataSource API is that it allows developers to interact with a data source using any language supported by Spark. For instance, there is no native R interface to Solr, but using Spark SQL, a data scientist can pull data from Solr into an R job seamlessly.
In the next post, I’ll cover how to write a DataFrame to Solr using the DataSource API.
LEARN MORE
Contact us today to learn how Lucidworks can help your team create powerful search and discovery applications for your customers and employees.