Query Explorer Jobs in Fusion 3.1
Query Explorer Jobs in Fusion 3.1
Introduction
Query analysis is the most powerful analytical tool in any search engineer’s arsenal. Queries are the only line of communication between a customer and a search engine administrator. Yet, most engineers don’t have the tools to help them better understand their queries. Enter, Lucidworks Fusion. Fusion 3.1 has some out-of-the-box spark analytics jobs to help you make sense of your queries and data more easily. Below are descriptions and use cases for three of these jobs.
Collection Analysis
This job gathers some basic overall statistical information about the queries in a given collection. The collection analysis job computes the percentage of queries that have one, two, three, four, five and six or more terms along with the average query length and the standard deviation1 in the length of the queries. The job returns these values as fields of a single document in the specified outputCollection.
The job also performs some outlier computations. The numDeviations parameter specifies how many standard deviations to permit, beyond which the length of the query deems it an “outlier”. The algorithm computes which queries have length greater than numDeviations standard deviations away from the average and returns those documents in the same specified output collection. This means this single job populates two types of documents in the same output collection. You can use the type field to distinguish between the two types of documents. The first, which provides the statistics described in the previous paragraph, will have a “type” field of “stats” and the second will have a type “outlier”.
Below is an example configuration and output for the job.
{
"type" : "collection_analysis",
"id" : "collections",
"outputCollection" : "outputCollectionName",
"numDeviations" : 2,
"type" : "collection_analysis",
"trainingCollection" : "inputCollectionName",
"dataFormat" : "solr",
"trainingDataFilterQuery" : "*:*",
"trainingDataSamplingPercentage" : 1.0,
"randomSeed" : 8180,
"fieldToVectorize" : "query_s",
"sourceFields" : "raw"
}
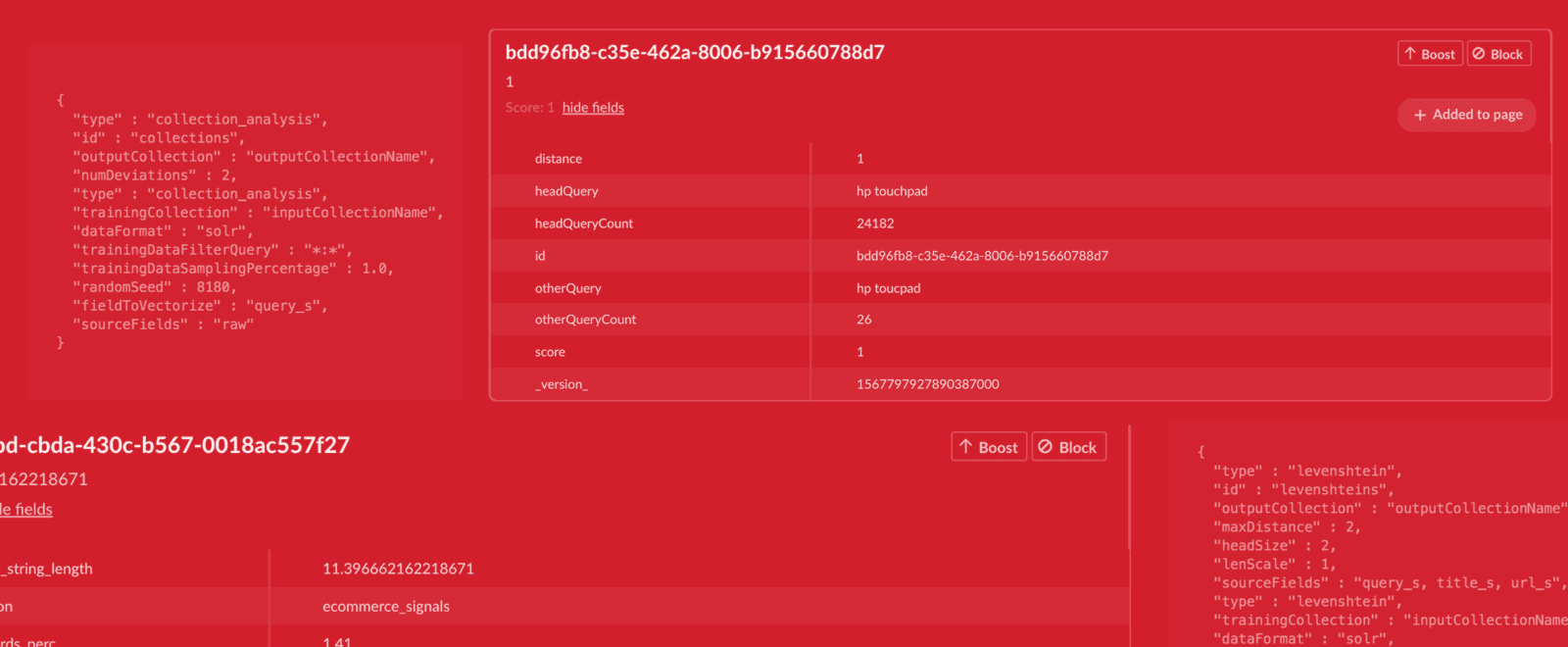
The fieldToVectorize corresponds to the query field. Running this job over a sample query set gives two types of documents. The first is a one time document that contains the statistics concerning the query lengths. An example of this document is below.
As we can see about 37 percent of the queries have only one term, whereas almost 45 percent have two terms. In addition we can see the standard deviation in the lengths of the queries is about 6.8 and the average length of the queries is approximately 11.
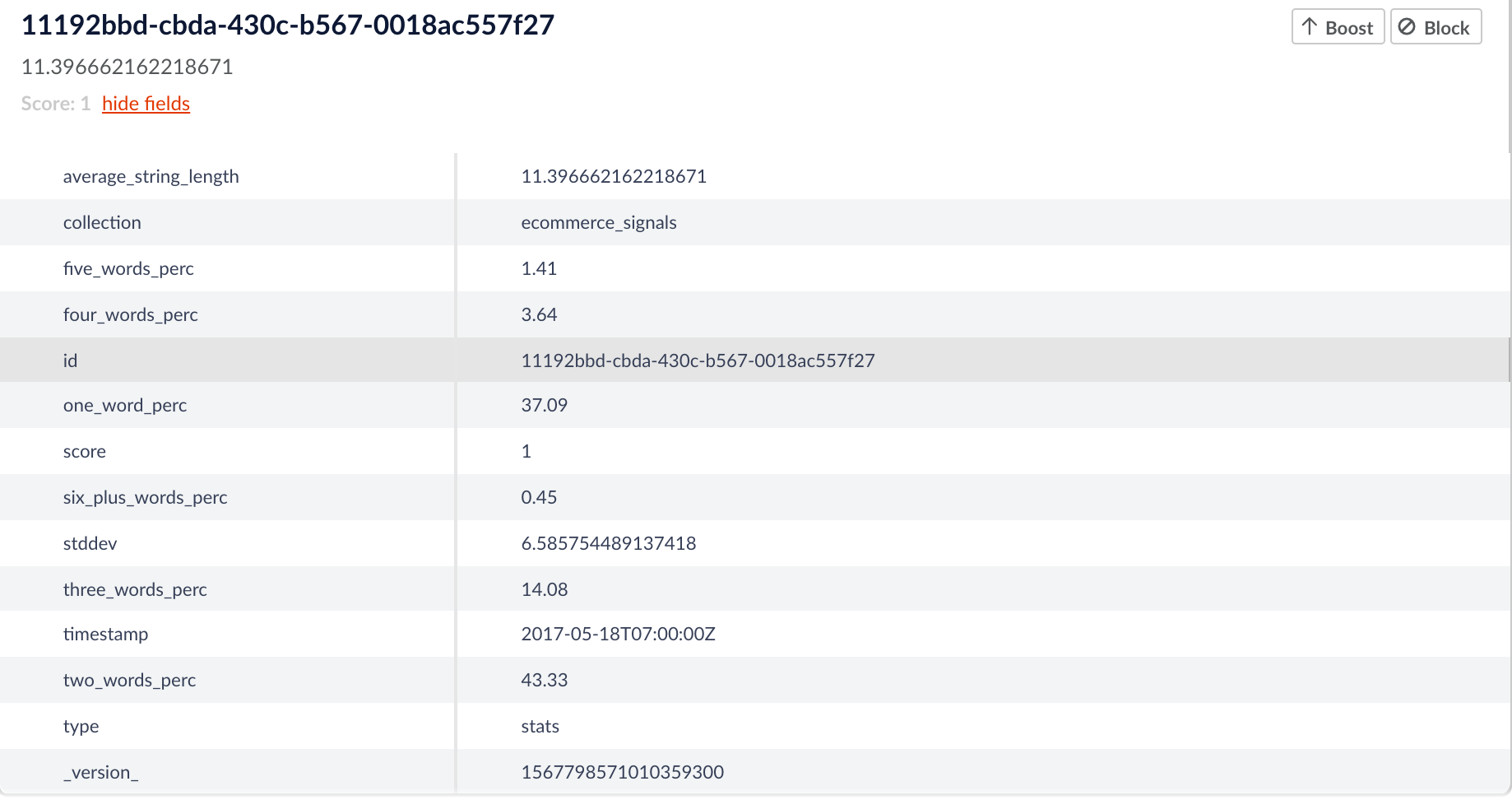
The other documents are those that make up the outlier set. Below is an example of what one of these documents might look like.
As we can see the length of the query in this document is 26. This is greater than 2 standard deviations away from the mean and so is deemed an “outlier” by the job.
Levenshtein Spell Checking
This job generates the levenshtein edit distance1 between a set of the most popular queries and every other query. It returns the pairs within a specified edit distance of one another. This job is intended to be used to find common misspellings in popular queries. Below is an example configuration.
{
"type" : "levenshtein",
"id" : "levenshteins",
"outputCollection" : "outputCollectionName",
"maxDistance" : 2,
"headSize" : 2,
"lenScale" : 1,
"sourceFields" : "query_s, title_s, url_s",
"type" : "levenshtein",
"trainingCollection" : "inputCollectionName",
"dataFormat" : "solr",
"trainingDataFilterQuery" : "*:*",
"trainingDataSamplingPercentage" : 1.0,
"randomSeed" : 8180,
"fieldToVectorize" : "query_s",
}
This job leverages the idea that the most popular queries are the least likely to be misspelled. The job uses a parameter called “headSize”. This is the size of the set we want to consider the “head” and comprises of the top “headSize” most popular queries. For example in the above job configuration headSize has a value of 2 so we will be taking the top two most popular queries to be the “head” queries. The other queries are called the “tail” are more likely to be simple misspellings of a corresponding head query. The job compares every tail query to the set of head queries and determines if the edit distance between them is within the specified “maxDistance” (in the above configuration it is 2). If the tail query is within “maxDistance” edit distance from the head query the job outputs the head and tail query pair, their distance and the counts for the head and tail queries. Below is an example of an output document.
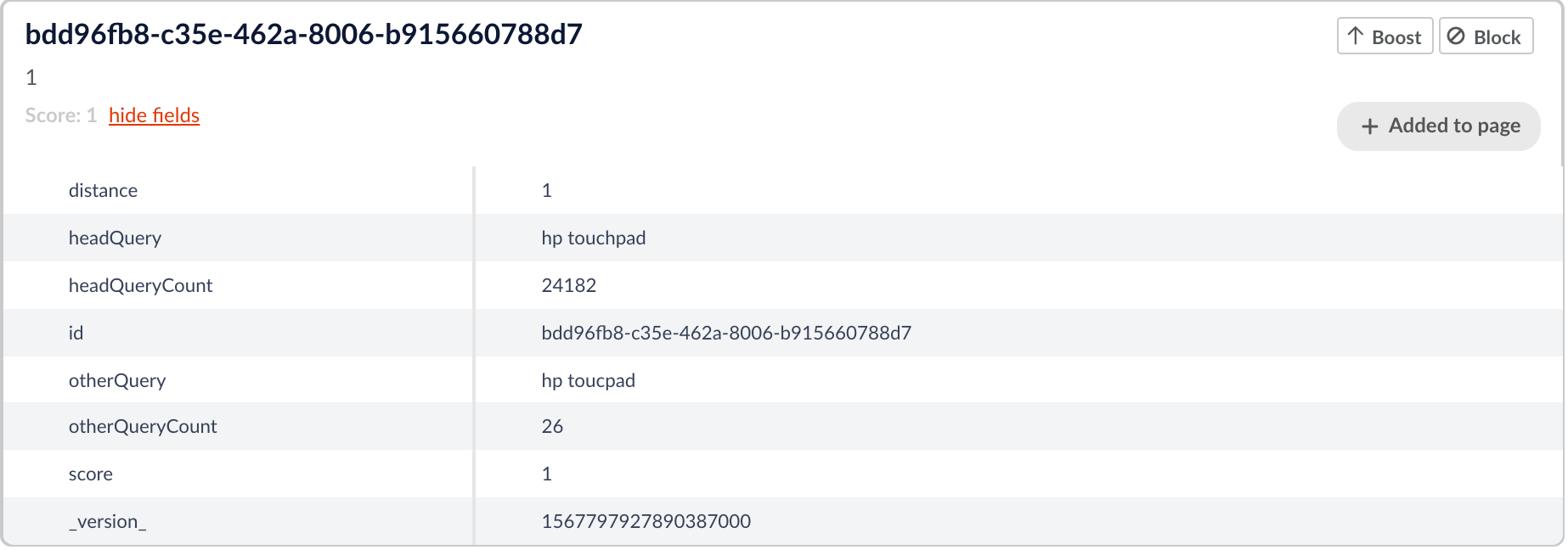
Here we see a head query of “hp touchpad” and a comparison query of “hp toucpad”. It is very likely that these are simple misspellings of one another and so the job returns the the pair and the edit distance between them.
There is an element of nuance with this job surrounding the lenScale parameter. This parameter effectively scales the edit distance with the length of the query. The scaling formula ensures the edit_distance <= query_length/length_scale. E.g., if we choose length_scale=3, then for query_length<=3, there won’t be pairs found. For queries with lengths between 4 and 6, edit distance has to be 1 to be chosen.
Statistically Interesting Phrases
This job is slightly different from the others. It is meant to be run over a corpus of text rather than a set of queries and it generates statistically interesting phrases1 from the corpus of text. A statistically interesting phrase is a phrase that occurs more frequently in a corpus than one might expect. Below is an illustrative example.
{
"id": "sips",
"type": "sip",
"analyzerConfig": "{
"analyzers": [ { "name": "StdTokLowerStop",
"tokenizer": { "type": "standard" },
"filters": [
{ "type": "lowercase" },
{ "type": "stop" }] }],
"fields": [{ "regex": ".+", "analyzer": "StdTokLowerStop" } ]}",
"inputCollection": "inputCollectionName",
"outputCollection": "outputCollectionName",
"descriptionField": "longDescription",
"ngramSize":"2",
"minmatch":"2"
}
The job takes a parameter “n” which corresponds to the size of the “phrase”. Below is an example of a configuration for a job. For example, if n is set to three then strings of three words will be considered phrases and the job will search for statistically interesting phrases of consisting of three or less words. Another interesting parameter is the minmatch. This is the minimum number of times a phrase must exist in the corpus to be considered statistically interesting. Below is an illustrative example of what the output of the job looks like.
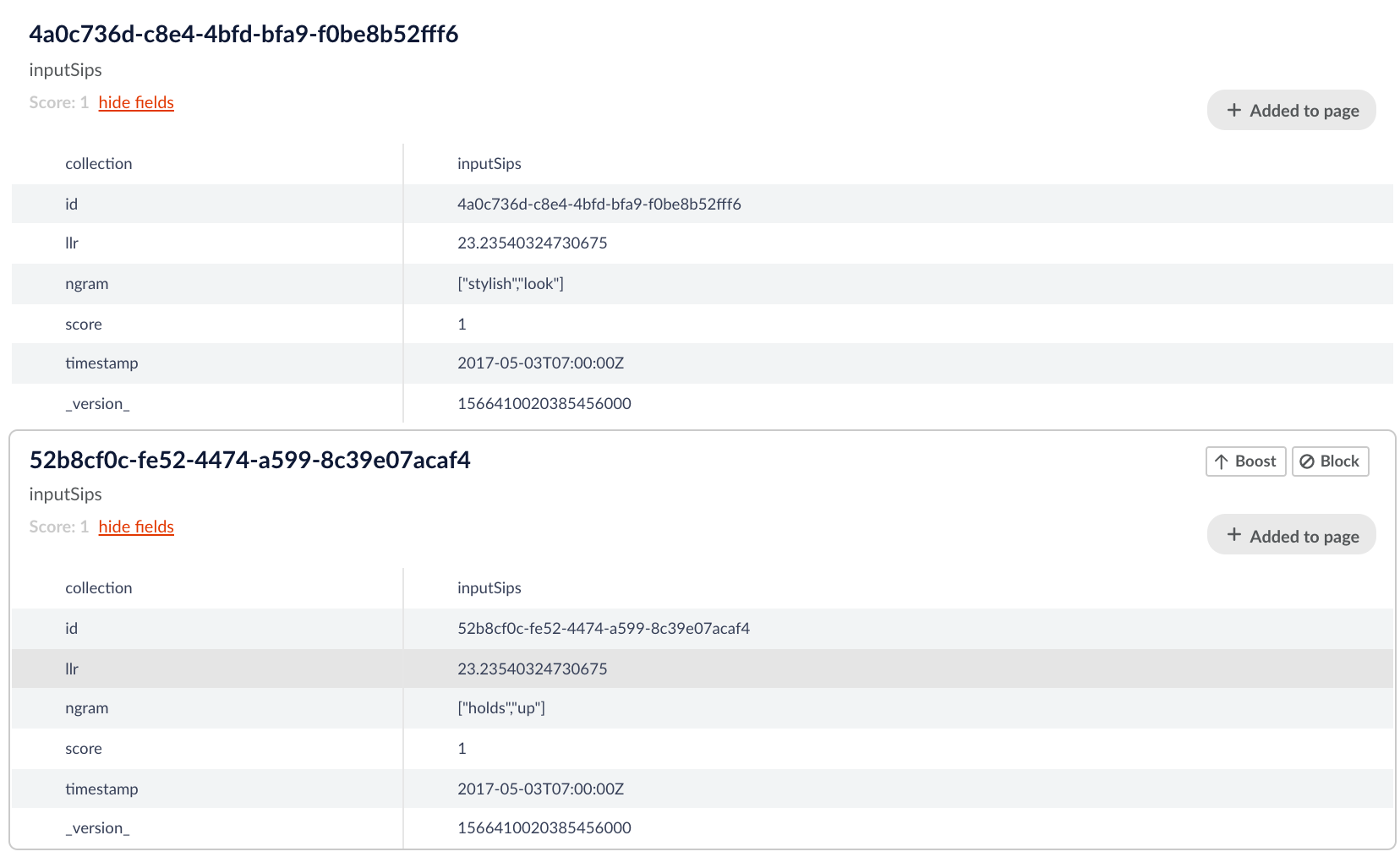
As we can see in the above documents these words have a high llr which indicates they occur together more often than is statistically likely. This indicates the ngram the words create is likely a “phrase”. Examining the ngrams logically the ngrams “holds up” and “stylish look” would certainly be considered phrases in the english language and so we can see that the SIP job has given a logical output.
The following example has a lower llr but still one above the specified threshold.
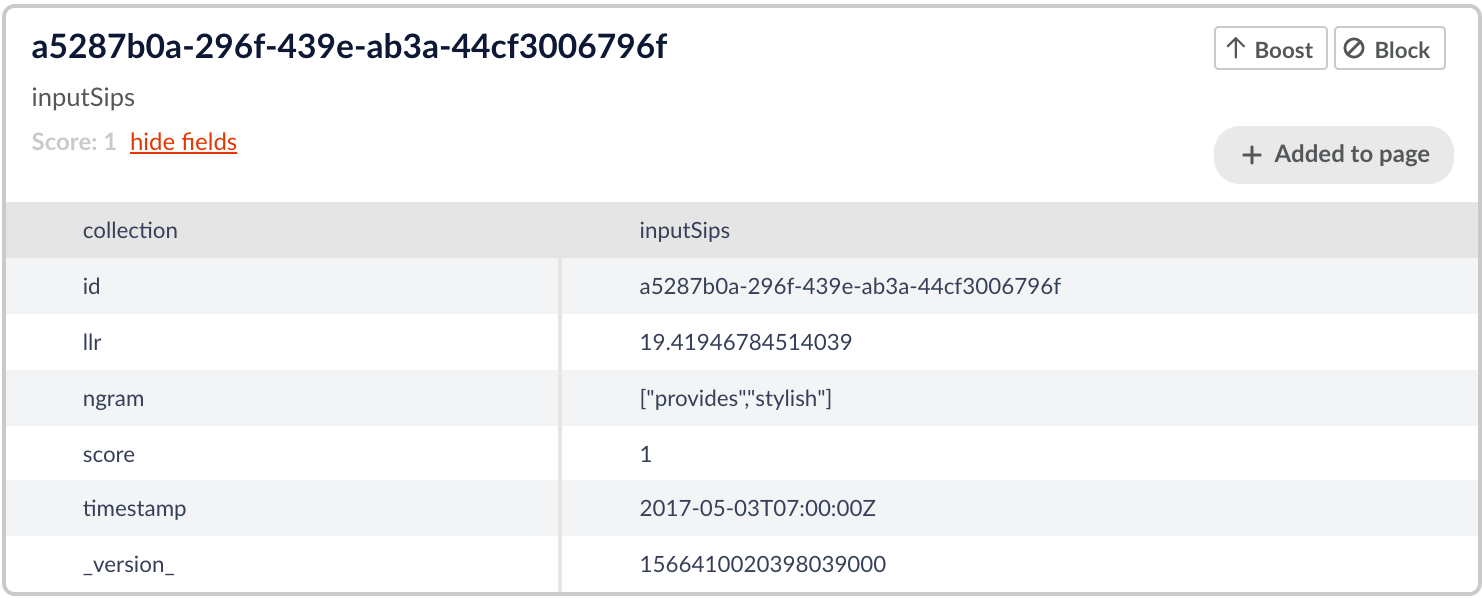
As we can see the phrase “provides stylish” is not a very common phrase but these two terms still seem likely to coincide in a corpus of text and the phrase “provides stylish” is logical. Not as likely to coincide as the phrases in the above figure, but still pretty likely.
Conclusion
These jobs give a data engineer an easy way to begin examining their query logs with just a few clicks in Fusion. For more information check out the Fusion documentation.
LEARN MORE
Contact us today to learn how Lucidworks can help your team create powerful search and discovery applications for your customers and employees.