Multi level composite-id routing in SolrCloud
SolrCloud over the last year has evolved into a rather intelligent system with a lot of interesting and useful features going in. One of them has been the work for intelligent routing of documents and queries.
SolrCloud started off with a basic hash based routing in 4.0. It then got interesting with the composite id router being introduced with 4.1 which enabled smarter routing of documents and queries to achieve things like multi-tenancy and co-location. With 4.7, the 2-level composite id routing will be expanded to work for 3-levels (SOLR-5320).
A good post about how document routing generally works can be found here. Now, let’s look at how the composite-id routing extends to 3-levels and how we can really use it to query specific documents in our corpus.
An important thing to note here is that the 3-level router only extends the 2-level one. It’s the same router and the same java class i.e. you don’t really need to ‘set it up’.
Where would you want to use the multi-level composite-id router?
The multi-level implementation further extends the support for multi tenancy and co-location of documents provided by the already existing composite-id router. Consider a scenario where a single setup is used to host data for multiple applications (or departments) and each of them have a set of users. Each user further has documents associated with them. Using a 3-level composite-id router, a user can route the documents to the right shards at index time without having to really worry about the actual routing. This would also enable users to target queries for specific users or applications using the shard.keys parameter at query time.
How does it work?
Every document in Solr, in order to be routed needs to have a unique document id.
e.g. doc1
A hash of the id is calculated which is then used for routing.
This id can be modified to also contain routing keys for the purpose of composite-id router.
e.g. routekey1!routekey2!doc1
In case of a composite-id router, every document is routed using both, the route key (components) and the original document id. Routing is done using a 32 bit value derived using the various components of the routing key.
In case of 2-level composite-id routing, the first 16 bits (MSB) of the hash are derived from the hash of route key whereas the last 16 bits come from the document id itself
In case of a 3-level composite-id routing, the three components default to determining 8, 8 and 16 bits of the routing hash.
ID: myapp!user1!doc
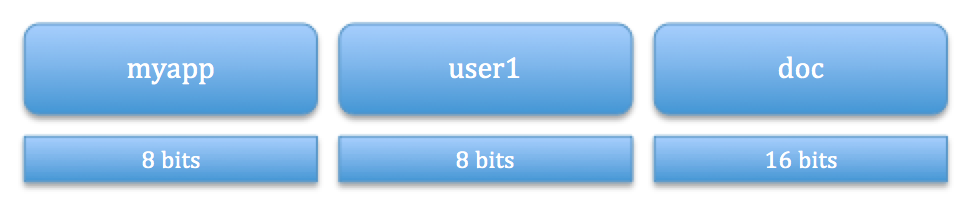
1st 8 bits from murmur3 hash of myapp
2nd 8 bits from murmur3 hash of user1
3rd 16 bits from doc
This can be altered for custom cases where the user may want to have more (or less) bits being contributed by each of the components. Here’s the example:
ID : myapp/6!user1/14!doc

1st 6 bits from myapp
2nd 14 bits from user1
3rd 12 (32-20) bits from doc
How do you actually use it in your application?
During indexing:
Add a document id with routing related information for each document. e.g. myapp!user1!doc
At query time:
To query all records for myapp: shard.keys=myapp/8!
Note the explicit mention of 8 bits in case of querying by component 1 only i.e. app level. This is required because the usage of the router as 2 or 3 level isn’t implicit. Specifying ‘8’ bits for the component highlights the use of ‘3’ level router.
To query all records belonging to user1 for myapp: shard.keys=myapp!user1!
Hope this clarifies to an extent about the how/why and what of the multi level composite id router.
LEARN MORE
Contact us today to learn how Lucidworks can help your team create powerful search and discovery applications for your customers and employees.