Fusion 2.0 Now Available – Now With Apache Spark!
I’m really excited today to announce that we’ve released Lucidworks Fusion 2.0!
Of course, this a new major release, and as such there is some big changes from previous versions:
New User Experience
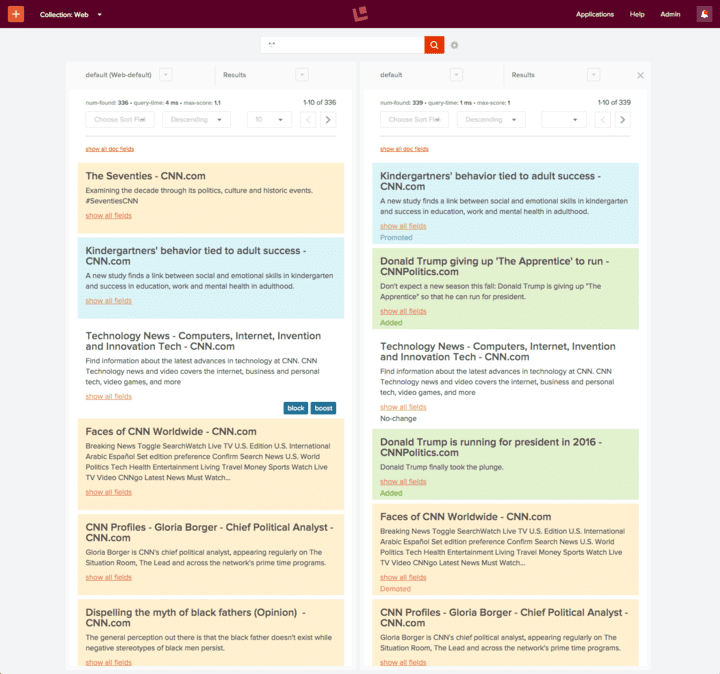
The most visible change is a completely new user interface. In Fusion 2.0, we’ve re-thought and re-designed the UI workflows. It’s now easier to create and configure Fusion, especially for users who are not familiar with Fusion and Solr architecture. Along with the new workflows, there’s a redesigned look and several convenience and usability improvements.
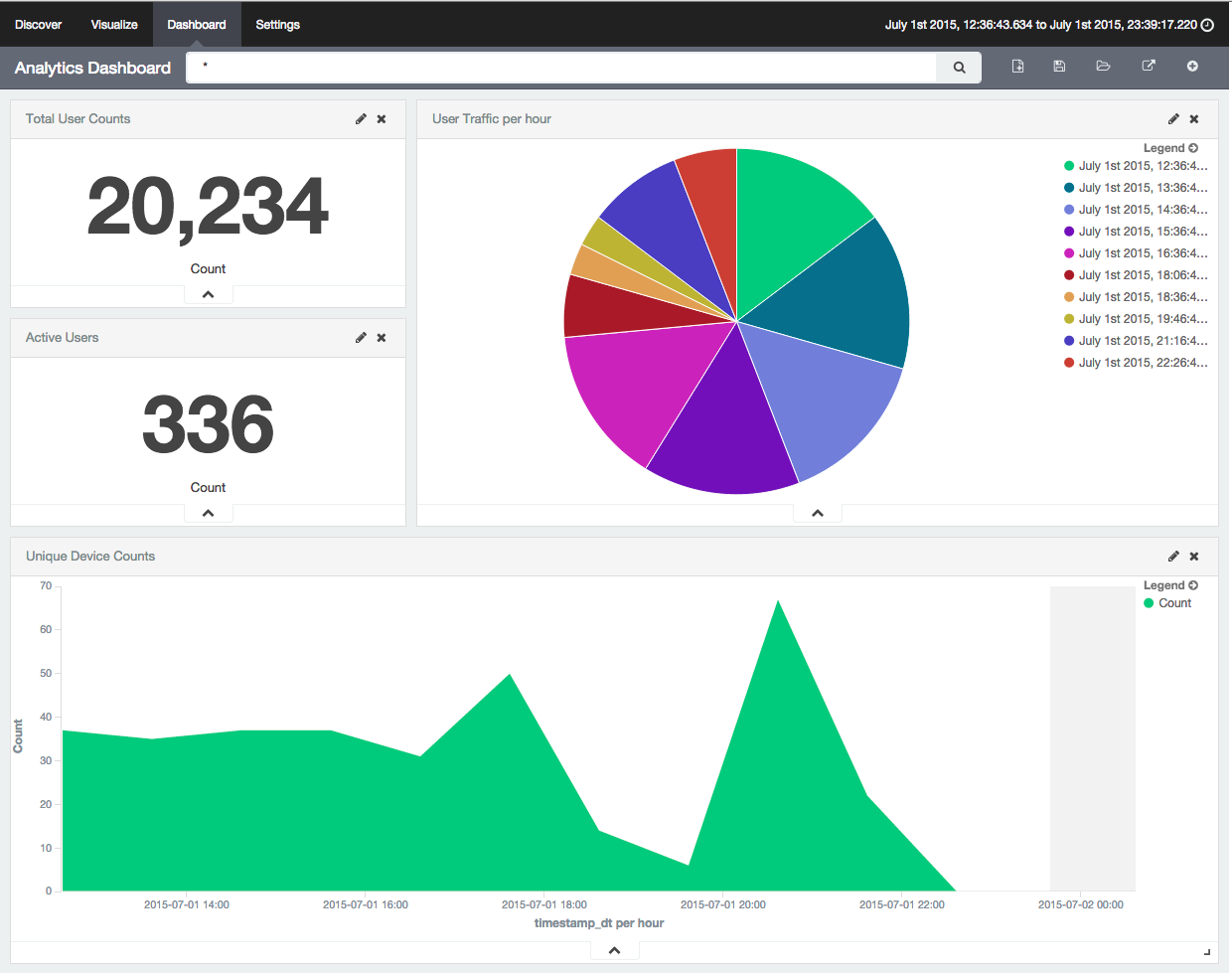
Another part of the UI that has been rebuilt is the Silk dashboard system. While the previous Silk/Banana framework was based on Kibana 3, we’ve updated to a new Silk dashboard framework based on Kibana 4.
Hierarchical facet management is now included. This lets administrators or developers change how search queries return data, depending on where and how a user is browsing results. The most straightforward use of this is to select different facets and fields according to (for example) the category or section that user is looking at.
And More
Along with this all-new front-end, the back-end of Fusion has been making less prominent but important incremental performance and stability improvements, especially around our integrations with external security systems like Kerberos and Active Directory and Sharepoint. We’ve already been supporting Solr 5.x, and In Fusion 2.0, we’re also shipping with Solr 5.x built-in. (We continue to support Solr 4.x versions as before.) And again as always, we’re putting down foundations for more exciting features around Apache Spark processing, deep learning, and system operations. But that’s for another day.
While I’m very proud of this release and could go on at greater length about it, I’ll instead encourage you to try it out yourself.
Coverage in Silicon Angle:
“Lucidworks Inc. has added integration with the speedy data crunching framework in the new version of its flagship enterprise search engine that debuted this morning as part of an effort to catch up with the changing requirements of CIOs embarking on analytics projects. .. That’s thanks mainly to its combination of speed and versatility, which Fusion 2.0 harnesses to try and provide more accurate results for queries run against unstructured data. More specifically, the software – a commercial implementation of Solr, one of the most popular open-source search engines for Hadoop, in turn the de facto storage backend for Spark – uses the project’s native machine learning component to help hone the relevance of results.”
Coverage in Software Development Times:
Fusion 2.0’s Spark integration within its data-processing layer enables real-time analytics within the enterprise search platform, adding Spark to the Solr architecture to accelerate data retrieval and analysis. Developers using Fusion now also have access to Spark’s store of machine-learning libraries for data-driven analytics. “Spark allows users to leverage real-time streams of data, which can be accessed to drive the weighting of results in search applications,” said Lucidworks CEO Will Hayes. “In regards to enterprise search innovation, the ability to use an entirely different system architecture, Apache Spark, cannot be overstated. This is an entirely new approach for us, and one that our customers have been requesting for quite some time.”
LEARN MORE
Contact us today to learn how Lucidworks can help your team create powerful search and discovery applications for your customers and employees.