The Modern Data Science Stack for Information Retrieval
Discover how Lucidworks builds a robust and scalable experience powered by AI without overwhelming front-end users with the complexity of the platform.

The technology stacks needed to run data science are an ever-evolving and accelerating field. This is both an exciting and nerve-wracking time, especially if you’re in charge of architecting systems to support the wide-reaching scope of data science in the enterprise.
Whether you are a product leader or engineering lead for a software vendor, or an enterprise architect for a customer-side enterprise, you will be faced with decisions about the architecture components and topologies to support data storage, movement, AI compute, API integration and dev-ops processes for a variety of applications.
At Lucidworks, we’ve spent the past decade building and implementing scalable, distributed systems for information retrieval (IR) in hundreds of organizations. These systems combine multiple types of compute paradigms, architecture components and AI processes implemented within bespoke processes and workflow.
This blog will discuss our experience building these systems and how we evolved them in order to respond to the changes in AI needs for IR. The most notable challenge being the need for a robust, scalable and versatile back-end that supports the front-end experience without surfacing that complexity to the users of the platform.
A Bit of History
Lucidworks Fusion platform as we know it today has evolved as an “open core” stack based primarily on Apache Solr as the main search index. Over time the platform added more components in order to integrate more Intelligence in the IR applications development flow. The initial foray in intelligence beyond keyword search was adding ML models to enhance how we use signals to boost the results and relevance based on user behavior. In order to better handle signals intake and ML jobs, Fusion integrated with Apache Spark in early 2017.
The next rev of the platform was Fusion 4, which brought a lot of enhancements on the stability of the enterprise platform. From an AI/ML/analytics perspective, Fusion 4 added:
- powerful ML for query understanding (rewrites),
- the ability to overlay business rules to complement the ML output with domain override,
- and a powerful/scalable SQL engine built on top of Apache Solr.
Until this point, the architecture of Fusion was a multi-tier monolithic stack that was stable, yet presented challenges with elasticity, upgradability and lack of certain functionality on the ML/AI side.
September 2019 was the milestone in which the new re-factored, services-based Fusion architecture was achieved. Outside of the obvious advantages for this cloud-native architecture in terms of caring and feeding the platform, the services-based architecture opened the Fusion platform up to a lot of innovation in how we support the AI functionality.
We are now able to take the ‘open core’ and ‘services’ mindset to the next level. We can focus it directly on how Fusion can manage AI workflows, especially external model pluggability, model training and deployment, all within a dev-ops oriented cloud environment. We now can target the best services available—commercial or open-source—for the tasks at hand, and integrate them into Fusion.
Artificial Intelligence in Fusion
The ongoing vision is to accelerate the development of intelligent IR applications through the use of low-code, intuitive environments powered by processes and workflows, or ‘jobs’ and ‘pipelines’ in Fusion speak. As we all know, making the AI process look easy to the users requires not only a well designed UI but also a well designed back-end. Let’s now focus on the architectural choices we have made to provide an intuitive and rich experience for the entire AI journey in Fusion.
AI-powered search is a process that requires a blend of workload profiles and workflows for embedding AI functionality directly in the IR applications. IR in general has two stages:
1. Indexing (data ingestion and treatment) which tends to be a blend of batch and near-real-time processing, and
2. Querying which is a real-time process with speeds measured in requests-per-second (RPS).
Embedding AI in these stages assumes a training/learning phase for model development and then deployment of the intelligence in the index or query stages as needed. This requires a robust distributed system, with components that work fully integrated yet can be managed individually. We designed Fusion to handle this complexity seamlessly and allow the users and administrators of the platform to spend their time on value-added tasks.
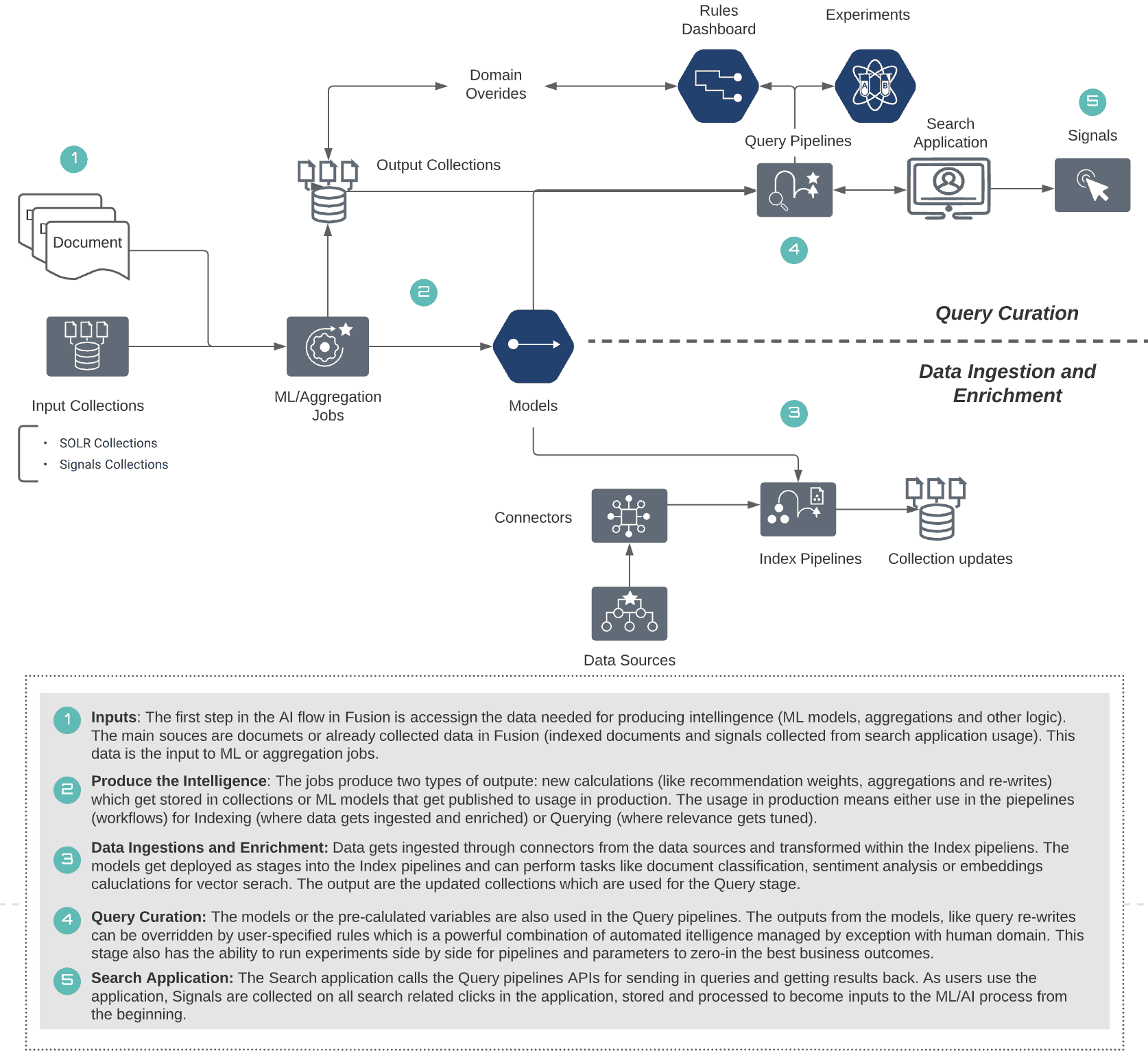
Scaling Infrastructure with the Best Services
The services-based approach to the architecture has allowed us to bring the best services for the job. Below is a representation of the services we will touch on:
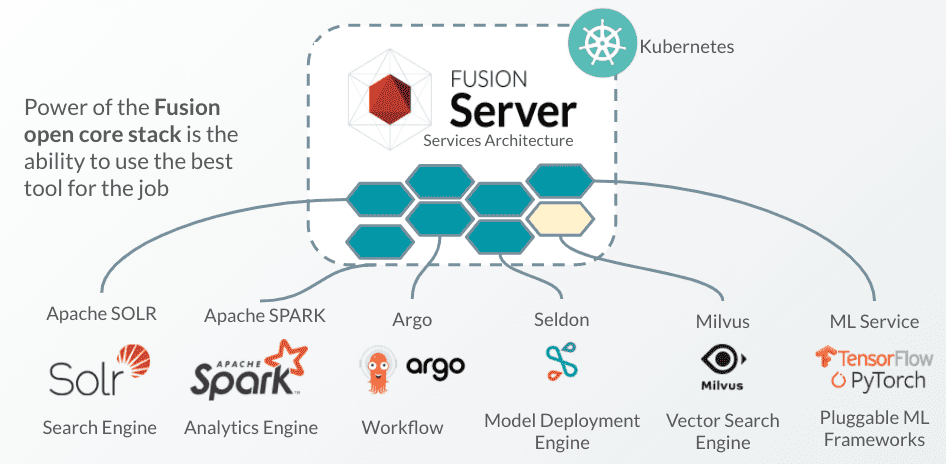
We will use the concept of “scaling” as an overall reference to the focus on scaling the infrastructure, but also the process—how it is built, deployed and supported. In designing the platform and it’s components we focused on the following scaling processes:
- Scale Infrastructure
- Scale Lexical Search
- Scale Analytics
- Scale Your Data Science
- Scale Vector Search
- Scale Workflow
Scale Infrastructure: Kubernetes
In early 2019 we moved from multi-tier, monolithic topology to a cloud-native, service-based architecture. This new architecture needed to support multiple workload profiles, including search, analytics, AI, and systems communication, plus multiple decoupled services, some of which needed to preserve state in order to meet the SLAs of mission critical IR. Kubernetes was the clear option as the container orchestrator needed to manage this type of high performance architecture.
Using Kubernetes as the foundation container platform, we designed the Fusion services and planned the workloads in separate node pools that allowed users to scale them up and down separately depending on the need of the application. As such, the real-time queries and ML models needed at run-time are all hosted and scaled on the query node pool. All the batch type workloads like aggregations, model training and the data needed to support them are all placed on the analytics node pool. If we need additional firepower on these nodes, we can add GPU instances to the cluster and speed up the processing used for deep learning models and recommenders. Finally, the system services are isolated on the systems node pool.
Kubernetes is the standard deployment of the Fusion platform. All the services that support the AI and analytics processing are containerized and orchestrated by Kubernetes. Once this foundation was laid out, integrating Kubernetes-native services was streamlined.
Scale Lexical (Keyword) Search: Apache Solr
Apache Solr is the backbone framework that supports lexical (keyword) search for Fusion. There have been multiple improvements to Apache Solr over the years to make it faster and scalable for high-volume, real-time traffic, with concepts like sharding and data replication across the cluster solved by the Solr community already.
Scale Analytics: Apache Spark and Fusion SQL
A search engine produces a lot of data in production. Queries, sessions, clicks, and logs are all stored and can be used for continually enhancing search intelligence. Running data pipelines that aggregate the data and make it available downstream for AI or other process workflows was critical. We needed a scalable analytics engine.
Apache Spark came in early in our platform design in order to complement Apache Solr. We have also leveraged Apache Spark’s ML capabilities for Fusion, although as we’ll explain in the next section, we have broadened the frameworks that we use for Fusion’s ML features.
As more and more organizations used Apache Solr as a store of documents, URL, etc., Lucidworks took advantage of the powerful SQL interface to query the Apache Solr data. Fusion SQL has evolved overtime to become a powerful querying facilitator that takes advantage of Apache Solr, streaming expressions and if needed Apache Spark.
The Fusion SQL engine allows Fusion to offer ad-hoc data exploration using the familiar syntax, while overlaying powerful statistical analysis and search functions directly in SQL. Fusion SQL can be accessed in tools like Jupyter notebooks to visualization platforms like Superset.
Scale Data Science: ML Service and Seldon Core
AI needs to be embedded in search processes. Search is interesting from an AI delivery perspective because of the indexing and query stages. Per the description above, these stages have different requirements in terms of response times and integration.
The AI models need to not only be highly accurate, but they have to be flexible and streamlined to be deployed both in batch processing and also real-time search apps, with concurrency up to 2000 queries per second.
The advances in the methodologies available across multiple AI development tools and frameworks (Tensorflow, PyTorch) were the catalyst for our engineers to build a pluggable service that allowed us to offer more options on top of what was already available in Spark libraries. This service opened us up to three powerful capabilities:
Build and Embed Our Own Models into Fusion:
Our AI Labs team has been using the full flexibility of developing models in python, Tensorflow or Pytorch and then easily publishing the models through the ML service to the Fusion Pipelines. The data and parameter inputs needed for training and publishing the models are baked directly into the intuitive, low-code experience of Fusion using smart defaults to accelerate the production and deployment of models in Fusion.
Embed Industry Pre-Trained Models in Fusion:
Through the same ML service, when we find models that are pre-trained on massive datasets from the community, we make them available directly into Fusion through access to curated container images that users can easily download and publish to Fusion. This accelerates the time to value of AI-powered search applications and addresses cold-start problems like not having data, or not having the volume of data needed to build robust models.
Allow Organizations to Bring-Your-Own-Model (BYOM) to Fusion:
Information retrieval is becoming a very important component of digital transformation for most companies, both on the enterprise and ecommerce side. Data science teams are increasingly jumping into the fray and experimenting with a blend of home-grown methods and community models. Since the last mile of model deployment in a business process—like mission-critical search applications—is one of the longest ones in the AI lifecycle, the Fusion ML service offers a streamlined process that accelerates that last deployment leg for data scientists.
Model Deployment Streamlining:
The backbone for deploying models in our Kubernetes-based environments is Seldon Core. This provides us the ability to deploy models using a variety of frameworks such as PyTorch, Tensorflow, or JAX in a consistent manner. It also gives us the ability to scale the deployments with standard Kubernetes policies.
Scale Vector Search: Milvus
Search methodologies have been progressing at breakneck pace in the last few years. Word-matching and frequency-based lexical (key-word) search have been enhanced with user behavior signals to boost relevancy.
These methods work very well for certain cases. However, when it comes to interpreting the intent of medium to longer queries (looking more like questions than keywords) and serving back relevant answers or sections of documents that are similar in meaning, new methods are needed. This is where vector search is a powerful complement. This method is a computational-heavy approach that uses deep neural networks to train models against data and understand these semantic/vector similarities between works, sentences and phrases.
Once models are trained, they need to be deployed at the scale and speed needed for search. Vector search models can be used at index time to produce embeddings, or vector representations, of the incoming data. At query time, the same models take the incoming query, represent it as a vector and then compare it to the available vectors already indexed, serving the most similar document or portion of the document as a result to the query.
These methods are successfully used in application for question and answers systems like Smart Answers, content-based recommenders when we have a cold-start situation with no historical data, or solving zero-results search as a back-up to lexical search. These use cases assume the ability to handle millions if not billions of vectors at millisecond speed. For that we needed a powerful and scalable embeddings engine.
Enter Milvus. We took this Kubernetes-native embeddings engine and wrapped it as a service in Fusion to help us support the volumes and speed needed to deploy vector-based deep learning models. The Milvus engineer stores the models and embeddings and works hand-in-hand with our document index (SOLR) to deliver the most similar document details for each query.
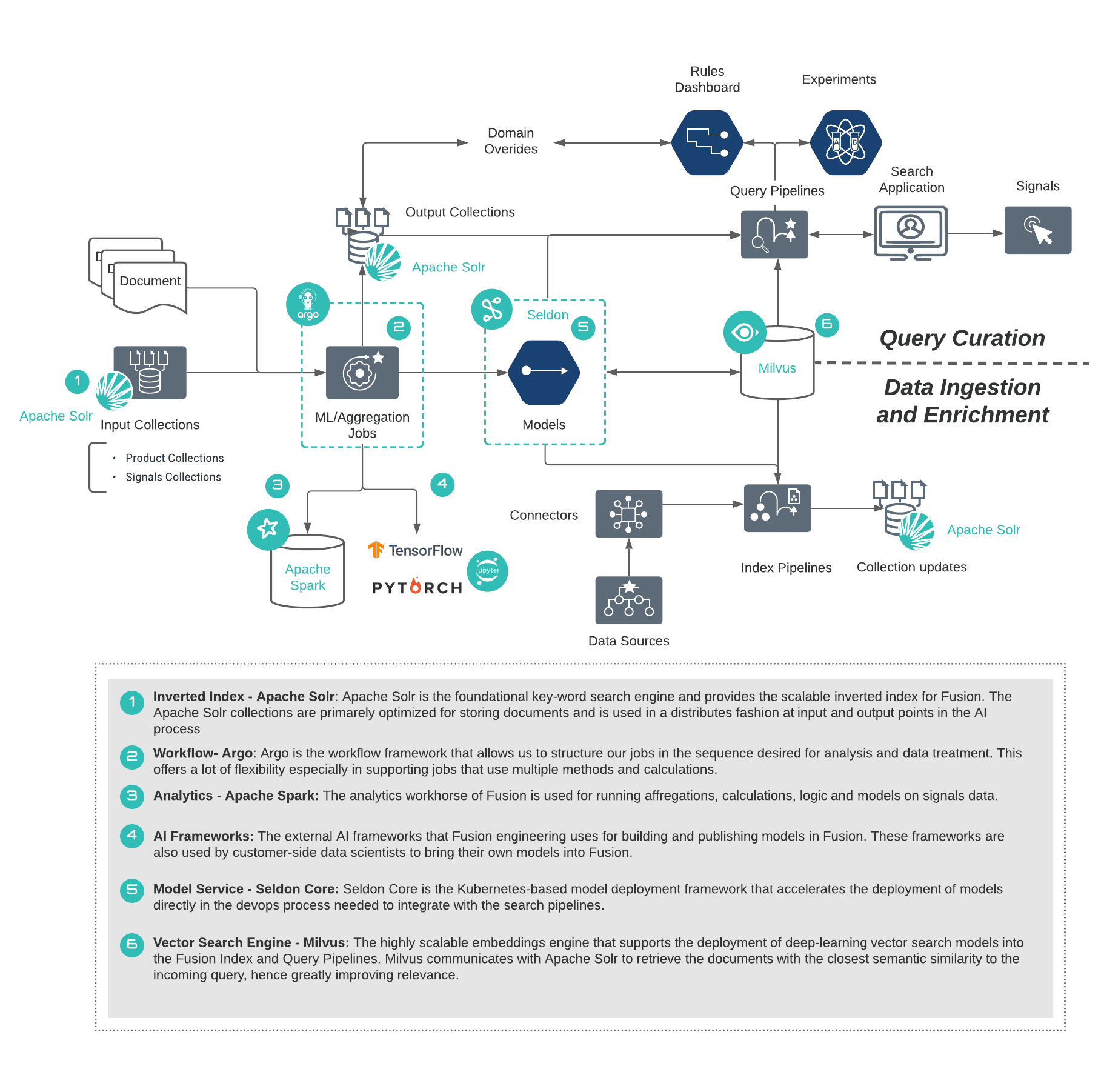
Pulling It All Together
These services are designed to augment the AI capabilities when it comes to AI methods pluggability, scalability of the infrastructure needed to run high performance search applications, as well as processes that accelerate the delivery of models to production workflows.
The diagram below summarizes how the services are overlaid on the AI flow that we described above:
 Conclusion
Conclusion
As a vendor and technology partner in this dynamic space of search and IR, Lucidworks has been working with organizations to accelerate their time to value for their search applications. The back-end that supports the front-end experience needs to be robust, scalable and versatile, without surfacing that complexity to the users.
Our cloud-native, services oriented architecture allowed us to build a highly intelligent real-time system based on workflow and embedded AI. With this foundational investment, Lucidworks is planning an aggressive move towards SaaS offerings and more specifically, AI-augmented business applications that work OOTB and focus on areas like enterprise knowledge management, customer support and product discovery. Interested in learning more about where we’re headed next? Check out this post: “The Next Frontier: Connected Experience Cloud.”
LEARN MORE
Contact us today to learn how Lucidworks can help your team create powerful search and discovery applications for your customers and employees.