Full Text Search Engines vs. DBMS
A comparison of full-text search engines and relational databases, and how to choose the right one for your next project.

Most modern search engines offer features like storage and data manipulation logic. At the same time, most databases offer some sort of text-based search, but a database’s ability to provide relevancy is either non-existent or a bolted-on afterthought.
Some applications will naturally be served best by one or the other technologies. Some apps may start with a relational database at the core but then as the volume of data or users grow, the needs of the users may be better served by migrating to a full-text search system. Many applications rely on both technologies in tandem, either for different parts of the data or by duplicating some of the data in the two systems to get the advantages of both.
Let’s take a look at the benefits of full-text search systems compared to a relational database (RDMS).
Comparing Full-Text Search Engines and Relational Databases
Full-text systems are better for quickly searching high volumes of unstructured, semi-structured, or structured text for a specific word or words. They provide rich text search capabilities and sophisticated relevancy ranking for ordering results on how well they match a potentially “fuzzy” search query (words that don’t quite match, like typos or homonyms).
These systems also provide for various forms of natural language processing to understand user intent and have strong recommendation algorithms. These capabilities allow search systems to have a much more intuitive, personalized experience for the user.
Relational databases, on the other hand, excel at storing and manipulating structured data – anything that’s in a table format of rows and columns. They support flexible search of multiple record types for specific values of specific fields, and can be great for quickly and securely updating specific individual records.
Some of the fields in a database’s records can be free-form text (like a product description). Most relational databases provide support for doing keyword searching on these unstructured fields.
But, the relevancy ranking of results coming out of a database won’t have the same quality or sophistication as the best full-text search systems. Further, unless the database administrator (DBA) knows what questions the user will ask, the performance of an RDBMS will be quite slow and provide a poor user experience.
If the DBA knows that users will ask certain types of questions, they can architect the database/tables to provide better results, but as user requirements change and evolve, the ability for the DBA to keep-up with those changes quickly lags behind and users inherently begin to abandon the query mechanisms built on RDBMSs.
Let’s take a deeper dive into the details:
What Full-Text Search Engines Do Well
Full-text search systems excel at quickly and efficiently searching large volumes of text. This could include unstructured data like a Word document or semi-structured content like HTML web pages which have some structure and metadata, but mostly an abundance of text.
They can also categorize that information based on specific values within the data (alphabetical, price range, region, color, size, file type, author). The text search capabilities of the best systems are rich and flexible, and include support for basic keyword searching, Google-style +/- syntax, old fashioned Boolean operators, natural language processing, proximity operations, find-similar functions, and other features.
Full-text search engines also have relevancy ranking capabilities to determine the best match for a query. These calculations look at the frequency of query terms in the document, their frequency in the corpus as a whole, and proximity to each other in a document, among other factors.
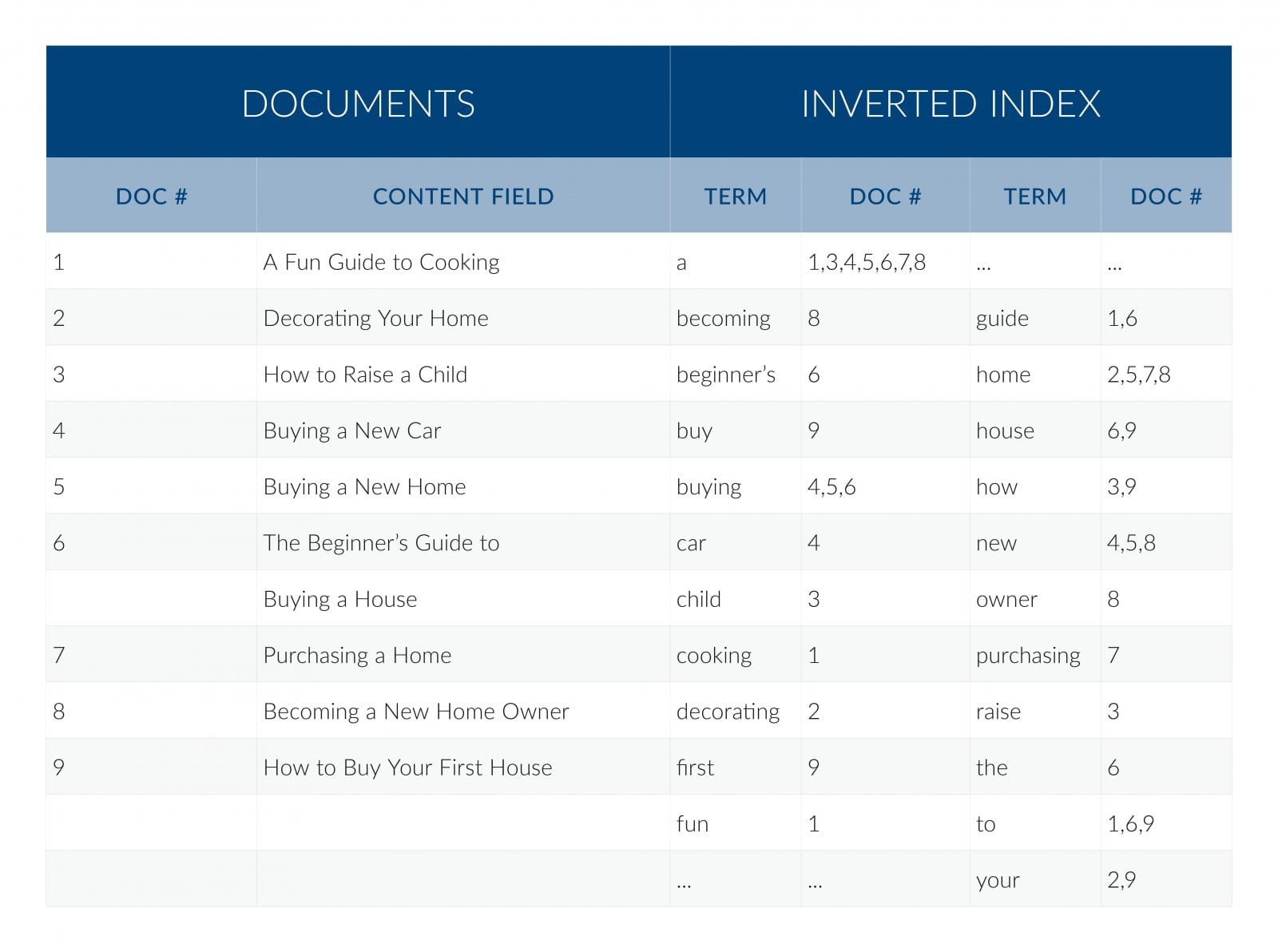
Full-text search systems rely on an index in order to perform queries. The most common type of index is an inverted index, which counts every term — every word, number, etc. — in every document with an indication of which documents contain that term and where they occur in the documents.
There may be a separate index for each field, or all fields may be contained in a single index. The system usually includes capabilities for handling non-text fields, like numeric range searching–especially when those ranges occur within the body of the text, the ability to sort results by any field, etc. but these capabilities generally need to be found in the documents themselves and are generally not computed in real-time by the search system.
In addition to indexing the data, most full-text search engines can store and retrieve the data in its original form. One reason for this is to easily populate a search result list with actual data from the documents listed giving users a better idea of a document before they click to see it. These systems also support incremental indexing, and the ability to add, delete or update individual records.
Search systems, however, are somewhat limited in their ability to rapidly and securely process database style transactional updates in the traditional index process and have had to adapt to changes being “pushed” into the index rather than relying on opportunistic incremental updates to the index. These near real-time changes allow complex product information to be shown to a user, such as inventory availability at their local store.
Search systems do not rely exclusively on text that has been “read” into the index for all relevancy measures. They can also rely on AI models to help influence relevance to user queries. Individual user interactions (clicks, views, queries, add-to-cart — also called signals) are aggregated and fed back into the system to provide more relevance results and enhanced user experience. These personalization techniques, first pioneered in the commerce world, are making their way into the digital workplace for enhanced productivity and better recommendations.

Another hallmark of search systems is the ability to index data from many different data sources. The index might hold data from file systems, web servers, CRM systems, databases and many other information sources. One user query may seek information in any and all of those systems and show them only the documents they are entitled to see based on their permissions and security privileges.
The capabilities of full-text search systems can be summarized as follows:
- Sub-second search responses when searching millions, possibly billions of documents containing one or more terms. This includes search of text fields, and somewhat more limited capabilities for searching non-text data. Plus, also includes efficient faceting or categorizing of content or search results based on specific values of specific fields.
- Rich and flexible text query tools and sophisticated ranking capabilities to find the best documents and records.
- Recommendations of content and experts to guide users to results that are most meaningful to their query
- Real-time relevancy boosts based on prior interactions, queries, and other users’ behavior.
- Capabilities for adding, deleting or updating documents and records.
- Basic functionality for storing the data beyond simply indexing and searching it.
- Limited capabilities for searching and manipulating data that actually represents different record types.
When to Use a Full-Text Search Engine in Your Application
The application requirements that might suggest choosing a full-text search system over a relational database:
- The application will be indexing a high volume of primarily textual information.
All possible user interactions and queries cannot be assumed up-front and might change over time. - Queries could span multiple systems and source repositories (file systems, web servers, CRM, databases, etc.)
- A high volume of queries will be submitted to the system.
- The application must support highly flexible full-text search querying.
- Optimal relevancy has not or cannot be achieved with existing relational database technology.
- An adaptable user experience is a primary business requirement.
Moving an App From a Database Architecture to Search
The list above provides some reasons to choose a full-text search system at the start of a project. But it can also make the case to migrate an existing application from a database to a full-text system.
A database may have been appropriate when an app was first built, but performance issues might slow things down over time. Growth in volume of data, queries, or users might start to degrade performance. In other cases this is because the original choice of a relational database was made less because of the real ‘relational’ (multi-table) or ‘database management’ (transaction processing) requirements and more because the team was more familiar with database architecture and its conventions.
A full-text search system may be a more effective tool once the data from several tables is ‘flattened’ into a single record format suitable for full-text operations. This is most useful when there are only one or a handful of tables and limited needs for rich transaction processing or recovery.
In some cases data needs to remain in the relational database because of technical requirements, even though the database’s search is not adequate. In these cases, the database can be indexed so it is searchable by the full-text system.
Summary
Search technologies excel at high-speed search and faceting of large volumes of data. They’re not as strong in handling multi-record types or transaction processing as relational databases. But the flexibility offered by a modern search system is more than adequate in most situations and often the only solution for user intensive applications.
Many legacy DBMS-based applications were built with databases due to convenience and developer familiarity, and less because the application is best-suited to the capabilities of a database. Many applications can be migrated and powered by a search system if the DBMS no longer meets the needs of the users or the business owner.
Other applications can be partially migrated to search systems to support the particular search needs of the project. Further data can be used in simultaneously in both systems to capture the advantages of each of those native systems.
LEARN MORE
Contact us today to learn how Lucidworks can help your team create powerful search and discovery applications for your customers and employees.