Enhance SQL with Search and Statistical Analysis
Dying to enhance your SQL experience? Learn how to integrate search, statistical discovery and visualizations.

This article was co-authored by Radu Miclaus and Joel Bernstein.
The journey to digital transformation mandates that companies must transform the way they make use of their data. This includes how they access it, explore it, develop intelligence and use those insights to make decisions. SQL is the lingua franca for business intelligence and the users of SQL frameworks are asking for expanded capabilities to speak their language more effectively.
There are currently gaps in the SQL experience. Based on the data collected within organizations, SQL engines need to handle structured, semi-structured and unstructured data without prejudice. The way SQL currently handles unstructured data is relatively immature. As part of discoverability for unstructured data, SQL engines need to support “search” activities based on natural language processing (NLP) and text analyzers in order to extract and interpret information from documents.
If you are very knowledgeable in SQL and would like to do statistical analysis, the current options are slim to none… better learn Python or R. What if you could use statistical functions directly in the SQL experience, with syntax that you are familiar with? Novel idea!
Fusion SQL Delivers A Better Experience
At Lucidworks, we believe that as an SQL user, you should be able to have your cake and eat it too. A powerful SQL experience should blend the intuitive syntax we all know and love with powerful search and statistical analysis, on top of a fast, scalable engine.
We are looking empathetically to the SQL user and are addressing the following needs through enhancements in Fusion SQL. We do not disrupt the SQL learning curve, we aim to augment it. Why force SQL users to always interrupt their data exploration experience—SQL in one tool, analytics in another, visualization in yet another? You have invested in the learning curve, what would it look like if you could do much more in the SQL syntax?
The Power of the Fusion SQL User-Defined Functions (UDFs):
Fusion SQL is built on the powerful Solr engine. Solr architecturally supports the use of composable functions, hence the ability to use powerful math and streaming expressions. They have a wide variety of applications, especially in statistical analysis, however there is one catch: the syntax is complex.
Fusion SQL is now supporting powerful UDFs which simplify the complex syntax of SOLR streaming expressions and math functions into clean, intuitive SQL syntax.

Areas of Focus for Fusion SQL UDFs:
Search |
Time Series |
Text Analytics |
Miscellaneous |
|
|
Layering Visualization to the Experience Makes All the Difference
SQL users need a way to interactively slice and dice the data, sample it and analyze it. Interactive visualization of the data as they progress through the exploration is an important ingredient for understanding trends and presenting the intelligence discovered at each step. The Fusion SQL engine can integrate with interfaces like Jupyter notebooks and BI tools like Superset through adaptors to enable interactive visualizations.
Jupyter Notebooks:
Jupyter Notebooks have increased in popularity due to a surge in adoption by the data science community. It gives access to powerful visualization libraries that can be used for basic graphs as well as highly customized visualizations (matplotlib, seaborn, others). Fusion SQL integrates nicely with Jupyter Notebooks.
Example of connecting Fusion SQL to a Jupyter Notebook instance:
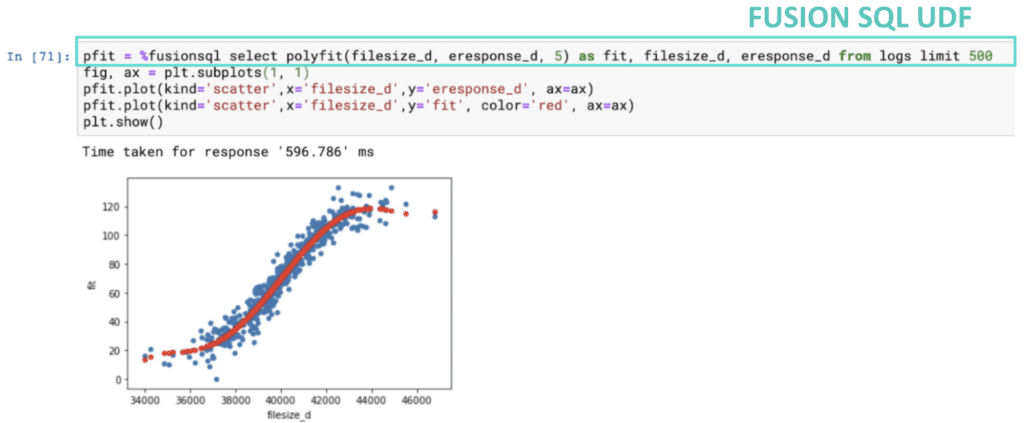
Example of a Polynomial Non-Linear regression using Fusion SQL UDF and Plotting
For a full guide on how to use Jupyter Notebooks with Fusion SQL, see the documentation here.
Superset BI Tool
Superset is a powerful visualization tool that offers an interesting blend of dashboarding, interactive no-code experience as well as a robust SQL editor. This combination allows users of different skill sets to consume, explore and even customize the SQL code and resulting visualization as needed. It is a great tool for teams to use collaboratively.
Superset is very powerful in exploring geospatial data, NLP and time series analysis.
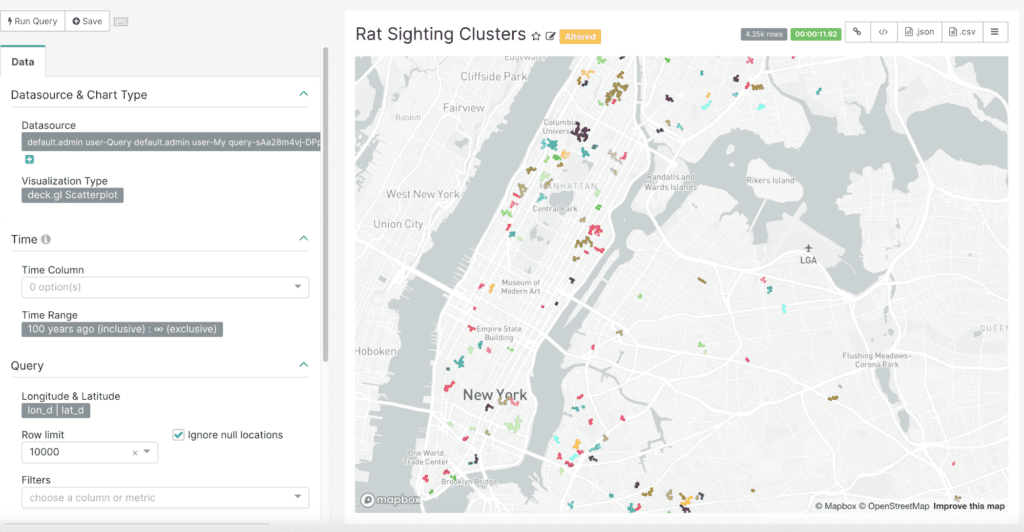
Example of Geospatial Clustering based on sample data:
Example of Correlation output based on co-occurrence:
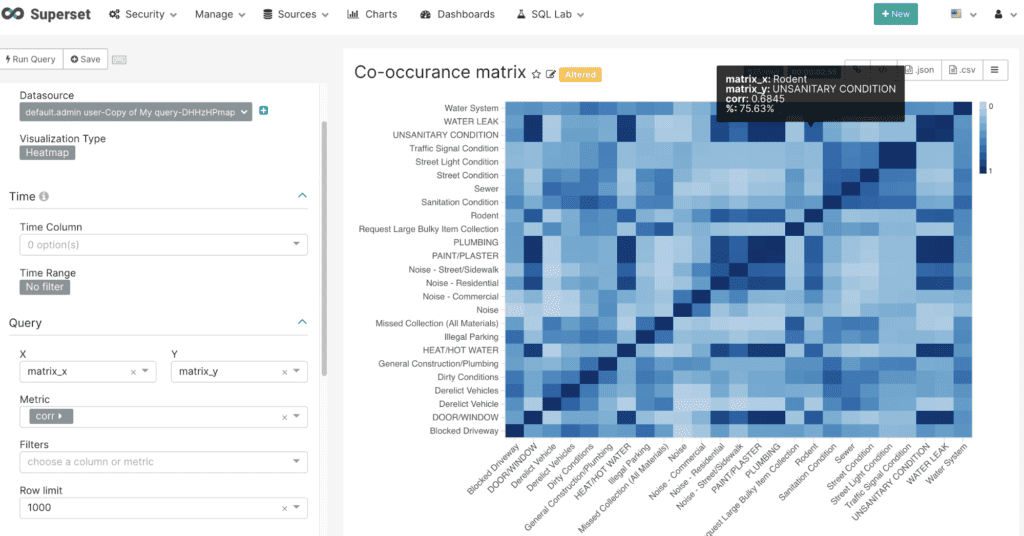
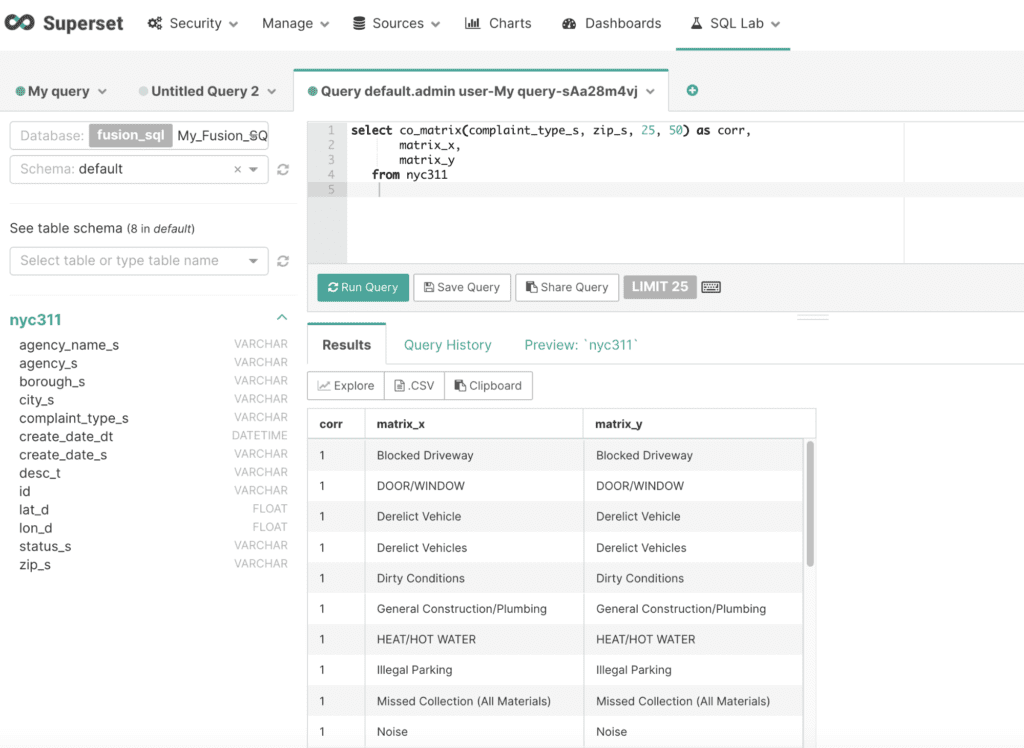
Example of the SQL Editor Experience using the Correlation UDF in Fusion SQL:
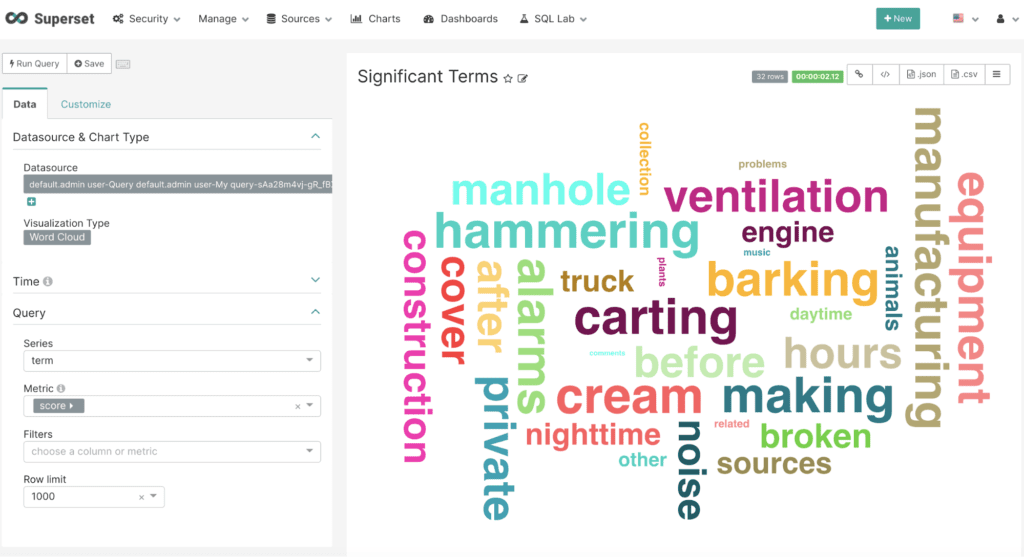
Example of WordCloud using Significant Terms Search UDF in Fusion SQL:
For a full guide on how to use Superset with Fusion SQL, see the documentation here.
Use Cases for Fusion SQL
Organizations are finding that Fusion SQL is highly versatile in its ability to tackle data discovery and analysis in business problems across two wide areas:
Explore Search Engine Data:
The Fusion platform produces a lot of data in the context of the search experience. Below are the use cases addressed by Fusion SQL:
- Log Analysis: Descriptive statistics, aggregations and time series analysis are applied to Solr logs to understand node activity, impact of updates and commits on query performance, query performance trends over time, identify trending, slow and zero result queries, identifying errors and performance impacts of collection topology.
- Documents Collections (and Data Enrichment) Exploration: As new data and metadata is added to collections during the jobs and ingest pipelines (document classification, entities, sentiment, aggregations) users have the ability to run descriptive statistics on the updated collections and understand what data is available at each step of the way.
- Signals/Telematics Collections Exploration: The signals and signals aggregation collections store the user activity data. When partnered with the documents and/or the product catalogs, this gives the search developers the ability to understand the coverage of search across documents/products and other meaningful insight from usage, conversion and business outcomes for search.
Explore Any Knowledge Base
Fusion SQL is able to explore any knowledge base that combines structured, semi-structured, and unstructured data. Here are a few use cases:
- Data Collected from Conversational Platforms: Data coming from non-search systems such as chatbots and other conversational platforms can be augmented with additional customer data, explored and analyzed at scale with Fusion SQL.
- Data Collected and Centralized for Customer 360 Applications: Similar to the scenario mentioned above, data that follows the customer journey throughout the organization can be centralized and explored in one place, especially if a large proportion of that data is unstructured and needs search.
- Data Collected and Centralized Across Entire Product Lifecycle: Companies that deal with challenges in unifying, exploring, searching and analyzing data across manufacturing and development, testing, CRM, after-market notes, tech support and services, can now use Fusion SQL as the scalable engine to do so efficiently.
Conclusion
Ad-hoc, interactive exploration is the best avenue to understanding your data. SQL remains the most accessible medium for multiple business analyst personas. To meet this demand, companies need to offer an enhanced SQL experience that is scalable, smart, intuitive and visual. Fusion SQL hits the mark on all four of these and has proven to be a powerful intelligence tool for our customers.
Don’t hesitate to reach out if you’re ready to enhance SQL. Contact us today.
LEARN MORE
Contact us today to learn how Lucidworks can help your team create powerful search and discovery applications for your customers and employees.