3 Common Data Challenges That Hamper Your Customer’s Search Experience

In a recent post, Marie Griffin discussed AI-powered search’s ability to improve the customer experience, boost loyalty, and increase purchases. And while there is no doubt smart search can do all of that — the characteristics of product data can make that going rough and set you on a path to failure.
Artificial intelligence (AI) needs data to learn, and no matter how big a data set is, AI will fail if data quality is poor. Data often has structural issues, such as typos, irregular capitalization, and multiple labels for the same type of data. It can also be in different formats, be inconsistent, have outliers, and distractions.
Github Senior Data Scientist, Kavita Ganesan, explains how such data challenges hold companies back from adopting AI-powered solutions: “Whether its labeled or unlabeled data or search logs, organizations need to readily have a good data store in place for data scientists to explore and build models. Creating a highly accessible data store is a heavy investment and requires lots of data engineering time to make things happen.”
We’ve listed the three most common data scenarios that gunk up data training — and what you need to do to address them.
1. Messy Data Makes it Difficult to Find What You Need
Solution: Indexing pipeline, regex replace filtering, and scripting can help.
In an ideal world, your data is well organized, easy to sort through, and simple to understand. Unfortunately, you have to deal with the data you’re dealt. But there are ways to be clever with cleanup and massaging of messy data to improve discovery and classification, giving the user or customer the ability to easily navigate the site and find what they’re looking for.
Some basic janitorial duties include normalizing values. For example, you have a “color” field with values “Blue” and “blue.” A basic capitalize normalizer would funnel all bLuE values into just Blue. Using this not too-far contrived example, before and after data cleanup the facets look like this, using `clean_color` as a new field to be able to contrast them:
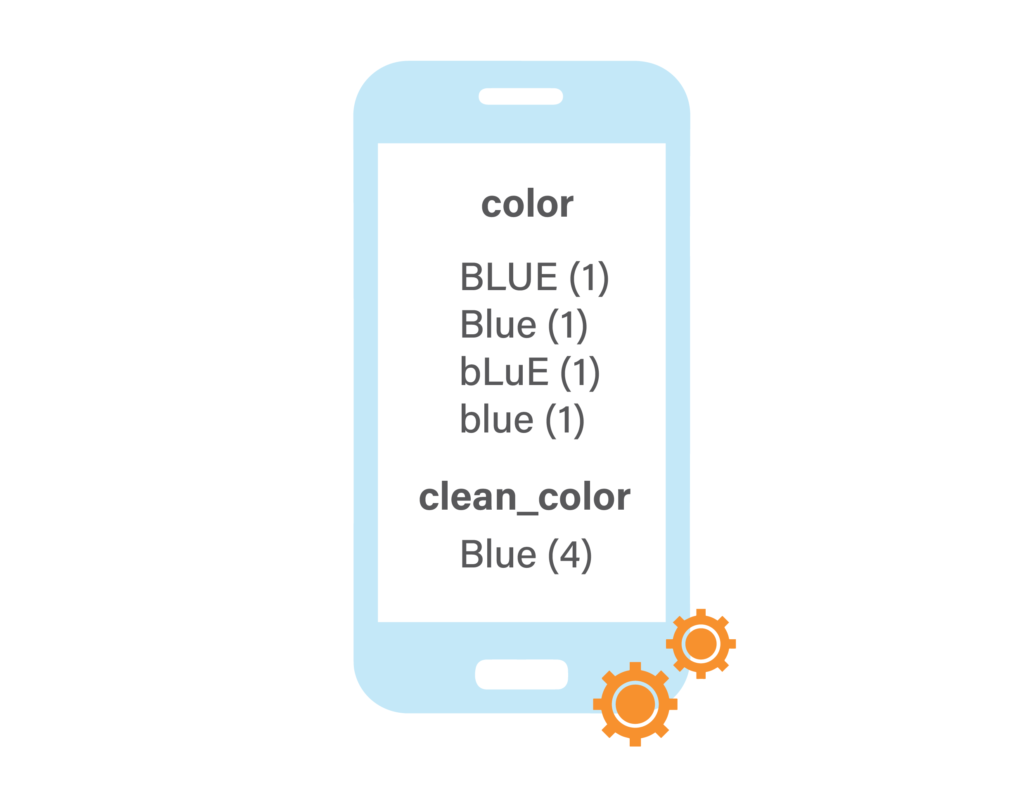
During indexing, the little bit of code below was added to capitalize the colors. In Fusion’s Index Workbench (IBW), this is done interactively; trial and error to get it right is how these things are tackled quickly:

The process of data ingestion and refinement requires several iterations to get ironed out, and in many cases is an ongoing effort of bringing in and refining new datasets to be effectively leveraged for querying. IBW allows quick visual iteration on datasource and parser configurations and index pipeline fiddling.
Important chunks of metadata often exist even in the most minimal of provided product data. A crude description of “This is a blue iPod armband” and some basic domain terminology cross references, this is straightforwardly ingested as:
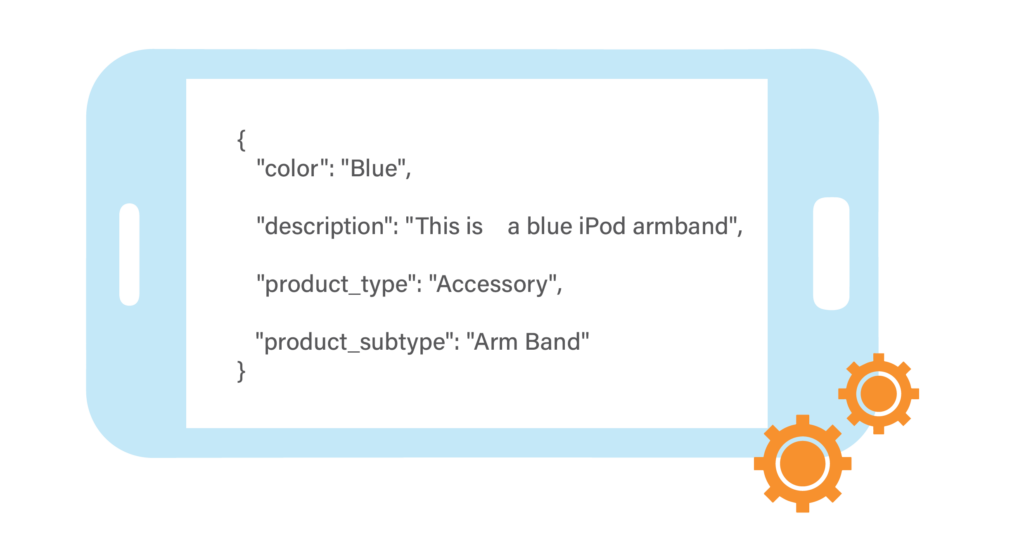
This allows for smoother, more effective navigation of your data.
2. Little Data Structure — So You’re Missing Matches
Solution: Add structure with basic tagging and extraction up to automated classification.
Typos and messes happen, so being less strict in classification can ensure that you’re not mistakenly cutting out potential matches. Searching through data with fuzzy logic, phonetic spellings, and regex formatting are ways to avoid skipping over what you’re looking for.
But, really, before firing up anything to do with machine learning, before writing code, and before getting out the data cleaning tricks, it’s best to get the source data corrected. The data came from somewhere – push back upstream to see if you can correct the data (and even related processes) well before it reaches you. It’s worth a try and makes life easier when data starts clean and stays clean.
[If you’re starting from scratch, here are some gauidelines on building a classifier.]
Here’s a real life example of how bad data impacts projects
Once upon a time, a friend was presenting a new, improved Solr-based search system to a room of big wig stakeholders, when a big wig domain expert pointed out that they could not deploy this system because of all the “bad data” it was showing. The folks in the room had never seen their data faceted, and it was easy to spot the mistakes.
”Financial (37)” was acceptable, but ”Finacnial (1)” was glaring. Just fix that record and re-index! Or if you can’t, keep reading for further solutions to that one poor record, left in a typoed category, and unfindable through intuitive navigation.
Imagine a product like “ipad” — where “ipda” is as likely to be typed.
And here’s a reinforcement: “However if a document is not appropriately tagged, it may become invisible to the user once the facet that it should be included in (but is not) is selected,”said our beloved Ted Sullivan in a prescient, aged article titled Thoughts on “Search vs. Discovery.”
3. Data That Doesn’t Learn Along the Way Creates Stagnancy
Solution: Collect user signals and feed improvements back into the system.
Considering the usage of our data systems — everything is a search-based app nowadays — there’s a lot to be gleaned from the queries and what users are accessing them from. We’ve gotten pretty good at search and logging, but the missing magic is when the two are married with machine learned improvements that continually tune results.
Your data is being used. Or is it? And who’s using it? Are some products/documents not seeing the light of day because they rarely appear in the search results? Looking into your knowledge system usage helps identify hot topics and trends, but don’t forget to look in those dark and dusty corners where things are hiding and forgotten.
- Learning about usage helps identify spelling corrections. Learn from me when I want ”bleu shoes,” oops, backspace backspace, correct, I mean ”blue shoes.”
- Learn that the item on the second page is really more relevant and useful because I clicked on it, skipping over the first page of results.
- Learn the relevant parts of queries using Head/Tail analysis so your system better understands users’ intent on unclearly phrased queries.
The short of it? You’ve got data. And you’ve got metadata, such as domain terminology, categories, taxonomies, and the like. Make the most of what you’ve got, using modern tools that can fix, improve, and learn from these things.
Data needs care and feeding to realize its full glory. In the case of retailers, successful systems power incredible customer experience. Be sure your data toolbox includes everything from basic regexes to machine learning to avoid those three most common obstacles to the data discovery and classification that’s feeding your shopper’s search and experience.
Businesses that put in the time and money to address these three most common (and fixable) pitfalls to data discovery and classification will take the lead in the long run. Being better prepared to incorporate the latest machine learning tools into their search experience will enable them to deliver the highly-coveted, best-in-class customer experience.
Erik explores search-based capabilities with Lucene, Solr, and Fusion. He co-founded Lucidworks, and co-authored ‘Lucene in Action.’
LEARN MORE
Contact us today to learn how Lucidworks can help your team create powerful search and discovery applications for your customers and employees.