Learning to Rank & Machine Learning on Search
Get the most out of your search by using machine learning and ltr (learning to rank). Here are the ins and outs of both.

Most companies know the value of a smooth user experience on their website. But what about their onsite search? Shoving Ye Olde Search Box in the upper right corner no longer cuts it. And having a bad website search could mean bad news for your online presence:
- 79% of people who don’t like what they find will jump ship and search for another site (Google).
- 15% of brands dedicate resources to optimize their site search experience (Econsultancy).
- 30% of visitors want to use a website’s search function – and when they do, they are twice as likely to convert (Moz).
This expands even further to the search applications inside an organization, like enterprise search, research portals, and knowledge management systems. Many teams focus a lot of resources on getting the user experience right: the user interactions and the color palette. But what about the quality of the search platform results themselves?
Automate Iterations With Machine Learning
Smart search teams iterate their algorithms to refine and improve relevancy and ranking continuously. But what if you could automate this process with machine learning? There are many methods and techniques that developers turn to as they continuously pursue the best relevance and ranking.
There are several approaches and methodologies to refining this art. One popular approach is called Learning-to-Rank or LTR.
Machine Learning
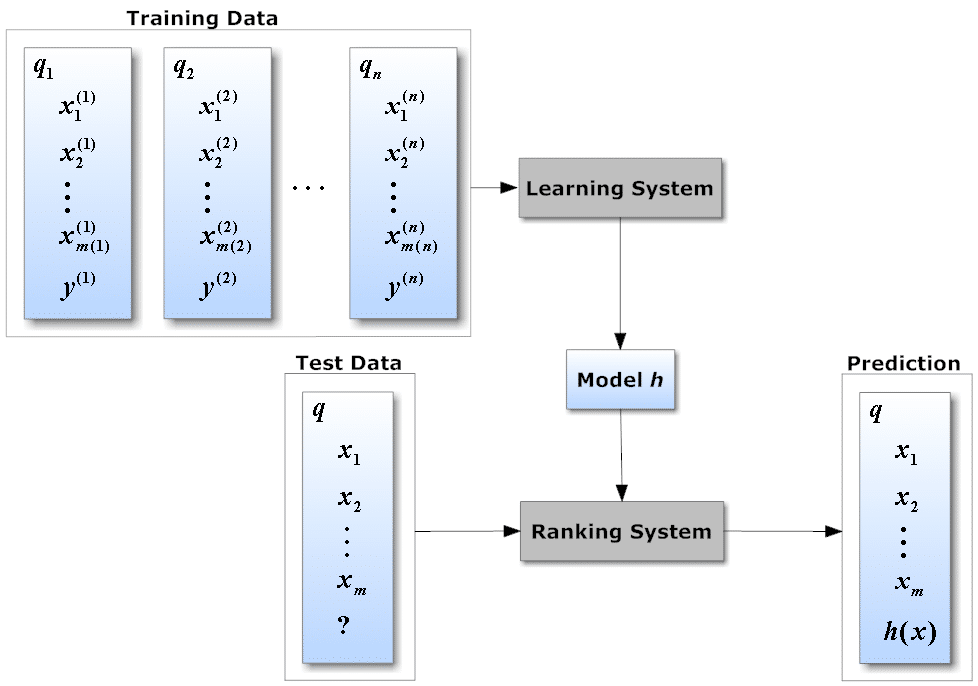
LTR is a powerful machine learning technique that uses supervised machine learning to train the model to find “relative order.” “Supervised” means having humans manually tune the results for each query in the training data set and using that data sample to teach the system to reorder a new set of results.
Popular site search engines have started bringing this functionality into their feature sets so developers can put this powerful algorithm to work on their search technology and discovery application deployments.
With this year’s Activate debuting an increased focus on search and AI-powered and related machine learning technologies, there are two sessions focused specifically on using LTR with Apache Solr deployments. To help you get the most out of these two sessions, we’ve put together a primer on LTR so you and your colleagues show up in Montreal ready to learn.
But first, some background.
How LTR Differs From Other ML Techniques
Learning to Rank (LTR) diverges from traditional machine learning solutions, which generally focus on predicting specific instances or events, generating binary yes/no decisions or numerical scores. Typical applications include fraud detection, email spam filtering, or anomaly identification. On the other hand, LTR transcends single-item focus, analyzing and ranking a set of items based on optimal relevance.
While both involve scoring, LTR emphasizes the final ordering and ranking of items over the actual numerical scoring of individual items. In LTR, the system learns from a model or ‘ground truth’ – an ideal set of ranked data curated by subject matter experts or aggregated from user behaviors like clicks, views, or likes. This approach is pivotal for precise academic or scientific data ranking, making LTR a powerful tool for enhancing site search relevance and user satisfaction.
How LTR Knows How to Rank Things
The LTR approach requires a model or example of how items should be ideally ranked. This is often a set of results manually curated by subject matter experts (again, supervised learning). This relies on well-labeled training data and, of course, human experts.
The ideal set of ranked data is called “ground truth” and becomes the data set that the system “trains” on to learn how best to rank automatically. This method is ideal for precise academic or scientific data.
A second way to create an ideal training data set is to aggregate user behavior like likes, clicks, views, or other signals. This is a far more scalable and efficient approach.
LTR With Apache Solr
With version 6.4, Apache Solr introduced LTR as part of its libraries and API-level building blocks. But, the reference documentation might only make sense to a seasoned search engineer.
79% of people who don’t like what they find will jump ship and search for another site – Google.
Solr’s LTR component does not do the training on any models — it is left to your team to build a model training pipeline from scratch. Plus, figuring out how all these bits and pieces come together to form an end-to-end LTR solution isn’t straightforward if you haven’t done it before.
So let’s turn to the experts.
Live Case Study: Bloomberg
Financial information services giant Bloomberg runs one of the world’s largest Solr deployments and is always looking for ways to increase and optimize relevancy while maintaining split-second query response times to millions of financial professionals and investors.
In their quest to continuously improve result ranking and the user experience, Bloomberg turned to LTR and developed, built, tested, and committed the LTR component inside the Solr codebase.
Those engineers from Bloomberg were onstage at the Activate conference in Montreal in October 2018 to talk about LTR. They discussed their architecture and challenges in scaling and how they developed a plugin that made Apache Solr the first open-source search technology that can perform LTR operations out of the box.
The team told the full war story of how Bloomberg’s real-time, low-latency news search engine was trained on LTR, how your team can do it, and the many ways not to do it. Here’s the video:
Live Demo: Practical End-to-End Learning to Rank Using Fusion
Also at Activate 2018, Lucidworks Senior Data Engineer Andy Liu presented a three-part demonstration on setting up, configuring, and training a simple LTR model using Fusion and Solr.
Liu demonstrated how to include more complex features and improve model accuracy in an iterative workflow typical in data science. Particular emphasis was given to best practices around utilizing time-sensitive user-generated signals.
15% of brands dedicate resources to optimize their site search experience – Econsultancy.
The session explored some of the tradeoffs between engineering and data science, as well as Solr querying/indexing strategies (sidecar indexes, payloads) to deploy a model that is both production-grade and accurate effectively. Here’s the video:
So that’s a brief overview of LTR in the abstract and where to see it in action with a real-world case study and a practical demo of implementing it yourself. Here’s even more reading to ensure you get the most out of this field.
More LTR Resources
Bloomberg’s behind-the-scenes look at how they developed the LTR plugin and brought it into the Apache Solr codebase
Our ebook Learning to Rank with Lucidworks Fusion on the basics of the LTR approach and how to access its power with our Fusion platform. Accompanying webinar. and our blog post the ABC’s of LTR.
An intuitive explanation of Learning to Rank by Google Engineer Nikhil Dandekar that details several popular LTR approaches, including RankNet, LambdaRank, and LambdaMART
Pointwise vs. Pairwise vs. Listwise Learning to Rank also by Dandekar
A real-world example of Learning to Rank for Flight Itinerary by Skyscanner app engineer Neil Lathia
Learning to Rank 101 by Pere Urbon-Bayes, another intro/overview of LTR, including how to implement the approach in Elasticsearch
LEARN MORE
Contact us today to learn how Lucidworks can help your team create powerful search and discovery applications for your customers and employees.