Better Search with Fusion Signals
Signals in Lucidworks Fusion leverage information about external activity, e.g., information collected from logfiles and transaction databases, to improve the quality of search results. This post follows on my previous post, Basics of Storing Signals in Solr with Fusion for Data Engineers, which showed how to index and aggregate signal data. In this post, I show how to write and debug query pipelines using this aggregated signal information.
User clicks provide a link between what people ask for and what they choose to view, given a set of search results, usually with product images. In the aggregate, if users have winnowed the set of search results for a given kind of thing, down to a set of products that are exactly that kind of thing, e.g., if the logfile entries link queries for “Netgear”, or “router”, or “netgear router” to clicks for products that really are routers, then this information can be used to improve new searches over the product catalog.
The Story So Far
To show how signals can be used to improve search in an e-commerce application, I created a set of Fusion collections:
- A collection called “bb_catalog”, which contains Best Buy product data, a dataset comprised of over 1.2M items, mainly consumer electronics such as household appliances, TVs, computers, and entertainment media such as games, music, and movies. This is the primary collection.
- An auxiliary collection called “bb_catalog_signals”, created from a synthetic dataset over Best Buy query logs from 2011. This is the raw signals data, meaning that each logfile entry is stored as an individual document.
- An auxiliary collection called “bb_catalog_signals_aggr” derived from the data in “bb_catalog_signals” by aggregating all raw signal records based on the combination of search query, field “query_s”, item clicked on, field “doc_id_s”, and search categories, field “filters_ss”.
All documents in collection “bb_catalog” have a unique product ID stored in field “id”. All items belong to one of more categories which are stored in the field “categories_ss”.
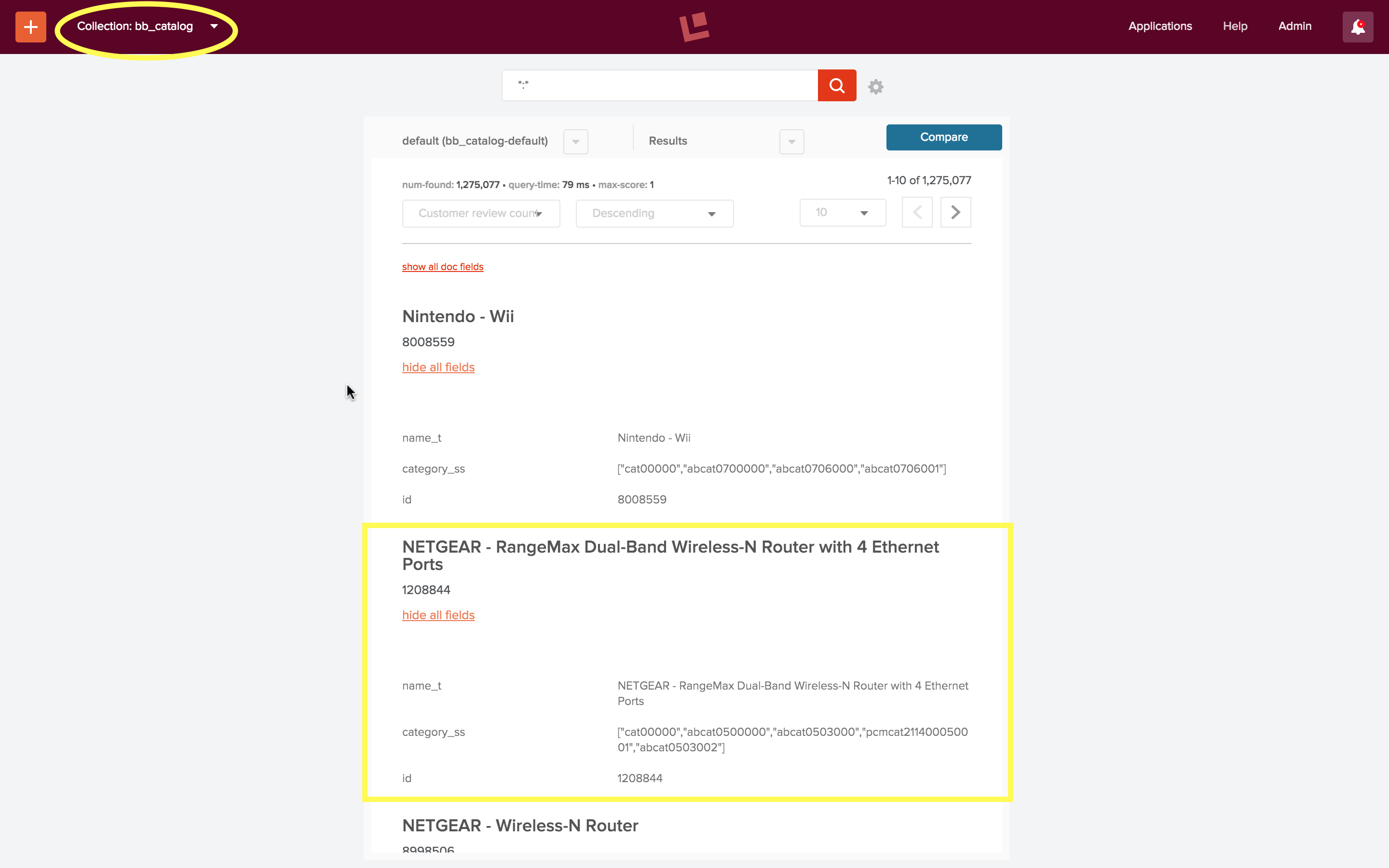
The following screenshot shows the Fusion UI search panel over collection “bb_catalog”, after using the Search UI Configuration tool to limit the document fields displayed. The gear icon next to the search box toggles this control open and closed. The “Documents” settings are set so that the primary field displayed is “name_t”, the secondary field is “id”, and additional fields are “name_t”, “id”, and “category_ss”. The document in the yellow rectangle is a Netgear router with product id “1208844”.
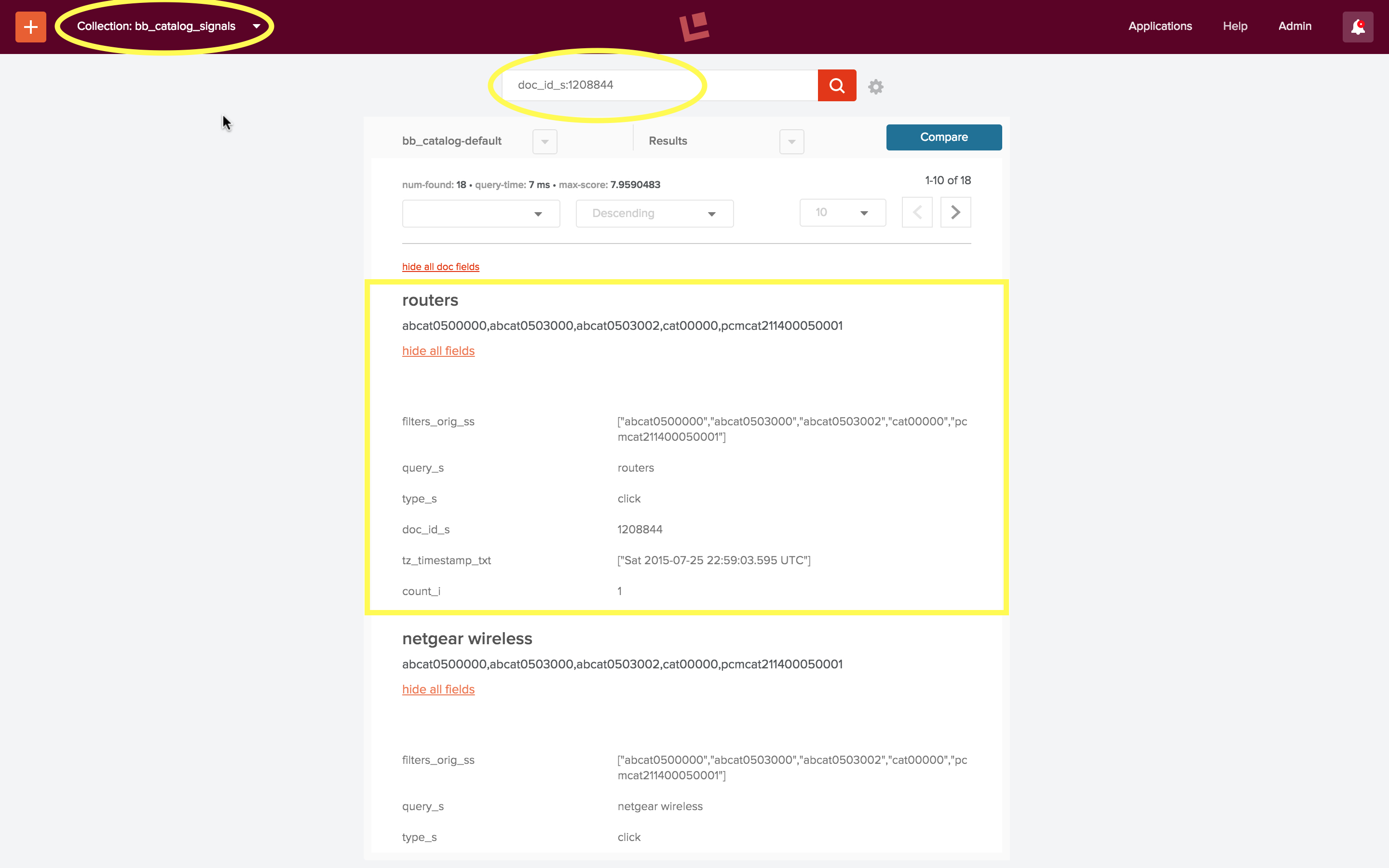
For collection “bb_catalog_signals”, the search query string is stored in field “query_s”, the timestamp is stored in field “tz_timestamp_txt”, the id of the document clicked on is stored in field “doc_id_s”, and the set of category filters are stored in fields “filters_ss” as well as “filters_orig_ss”.
The following screenshot shows the results of a search for raw signals where the id of the product clicked on was “1208844”.
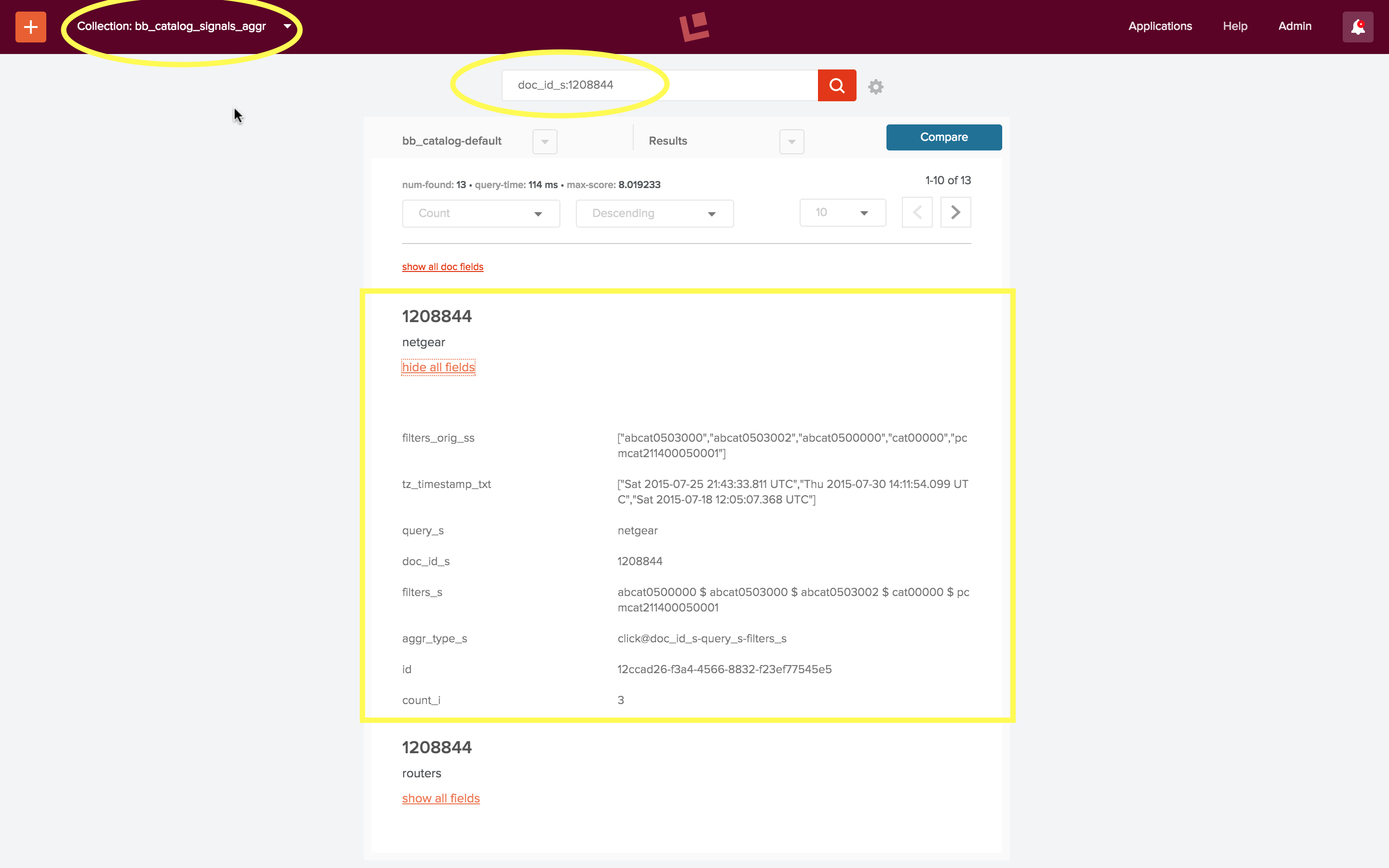
The collection “bb_catalog_signals_aggr” contains aggregated signals. In addition to the fields “doc_id_s”, “query_s”, and “filter_ss”, aggregated click signals contain fields:
- “count_i” – the number of raw signals found for this query, doc, filter combo.
- “weight_d” – a real-number used as a multiplier to boost the score of these documents.
- “tz_timestamp_txt” – all timestamps of raw signals, stored as a list of strings.
The following screenshot shows aggregated signals for searches for “netgear”. There were 3 raw signals where the search query “netgear” and some set of category choices resulted in a click on the item with id “1208844”:
Using Click Signals in a Fusion Query Pipeline
Fusion’s Query Pipelines take as input a set of search terms and process them into Solr query request. The Fusion UI Search panel has a control which allows you to choose the processing pipeline. In the following screenshot of the collection “bb_catalog”, the query pipeline control is just below the search input box. Here the pipeline chosen is “bb_catalog-default” (circled in yellow):

The pre-configured default query pipelines consist of 3 stages:
- A Search Fields query stage, used to define common Solr query parameters. The initial configuration specifies that the 10 best-scoring documents should be returned.
- A Facet query stage which defines the facets to be returned as part of the Solr search results. No facet field names are specified in the initial defaults.
- A Solr query stage which transforms a query request object into a Solr query and submits the request to Solr. The default configuration specifies the HTTP method as a POST request.
In order to get text-based search over the collection “bb_catalog” to work as expected, the Search Field query stage must be configured to specify the set of fields that which contain relevant text. For the majority of the 1.2M products in the product catalog, the item name, found in field “name_t” is only field amenable to free text search. The following screenshot shows how to add this field to the Search Fields stage by editing the query pipeline via the Fusion 2 UI:
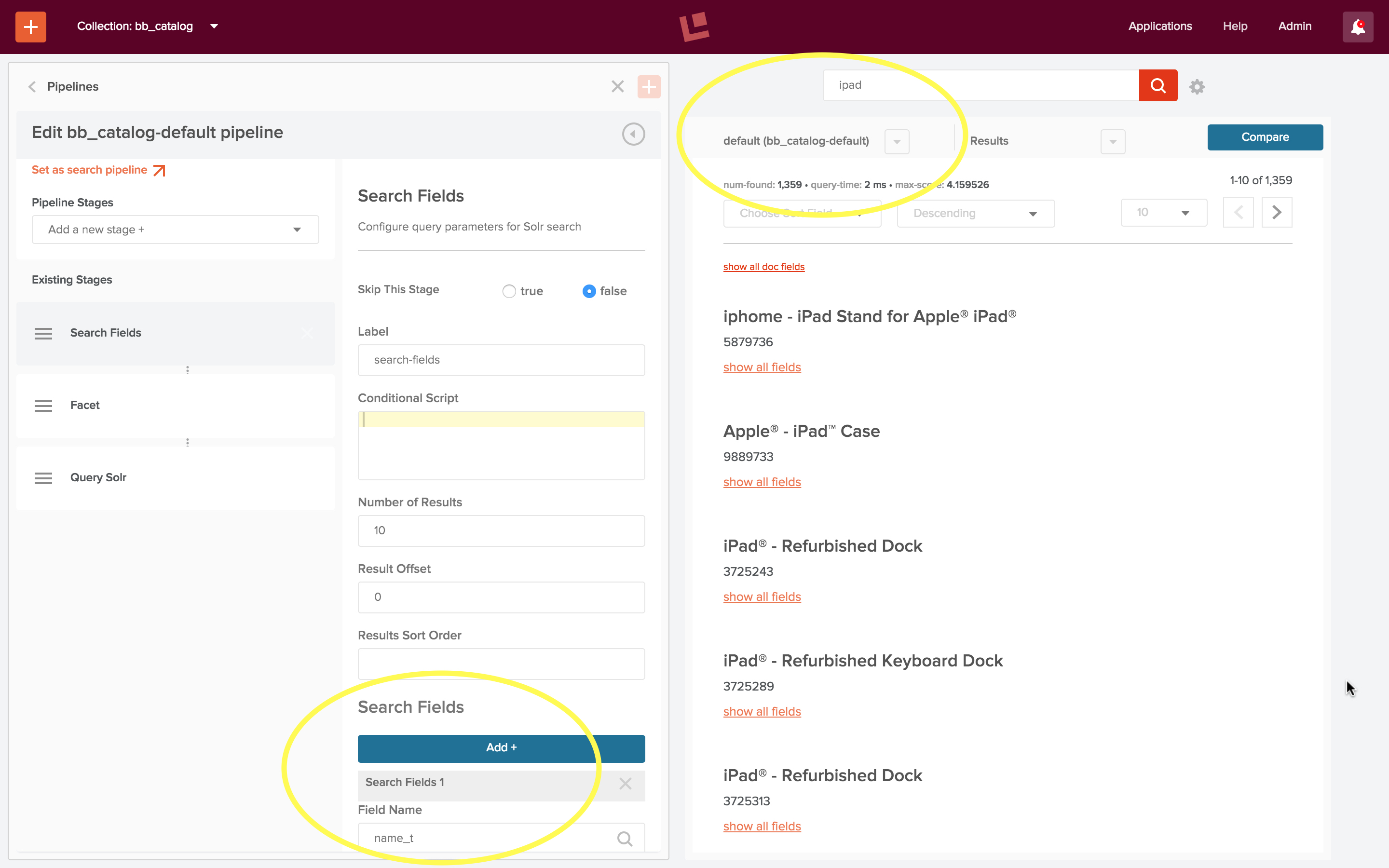
The search panel on the right displays the results of a search for “ipad”. There were 1,359 hits for this query, which far exceeds the number of items that are an Apple iPad. The best scoring items contain “iPad” in the title, sometimes twice, but these are all iPad accessories, not the device itself.
Recommendation Boosting query stage
A Recommendation Boosting stage uses aggregated signals to selectively boost items in the set of search results. The following screenshot show the results of the same search after adding a Recommendations Boosting stage to the query pipeline:
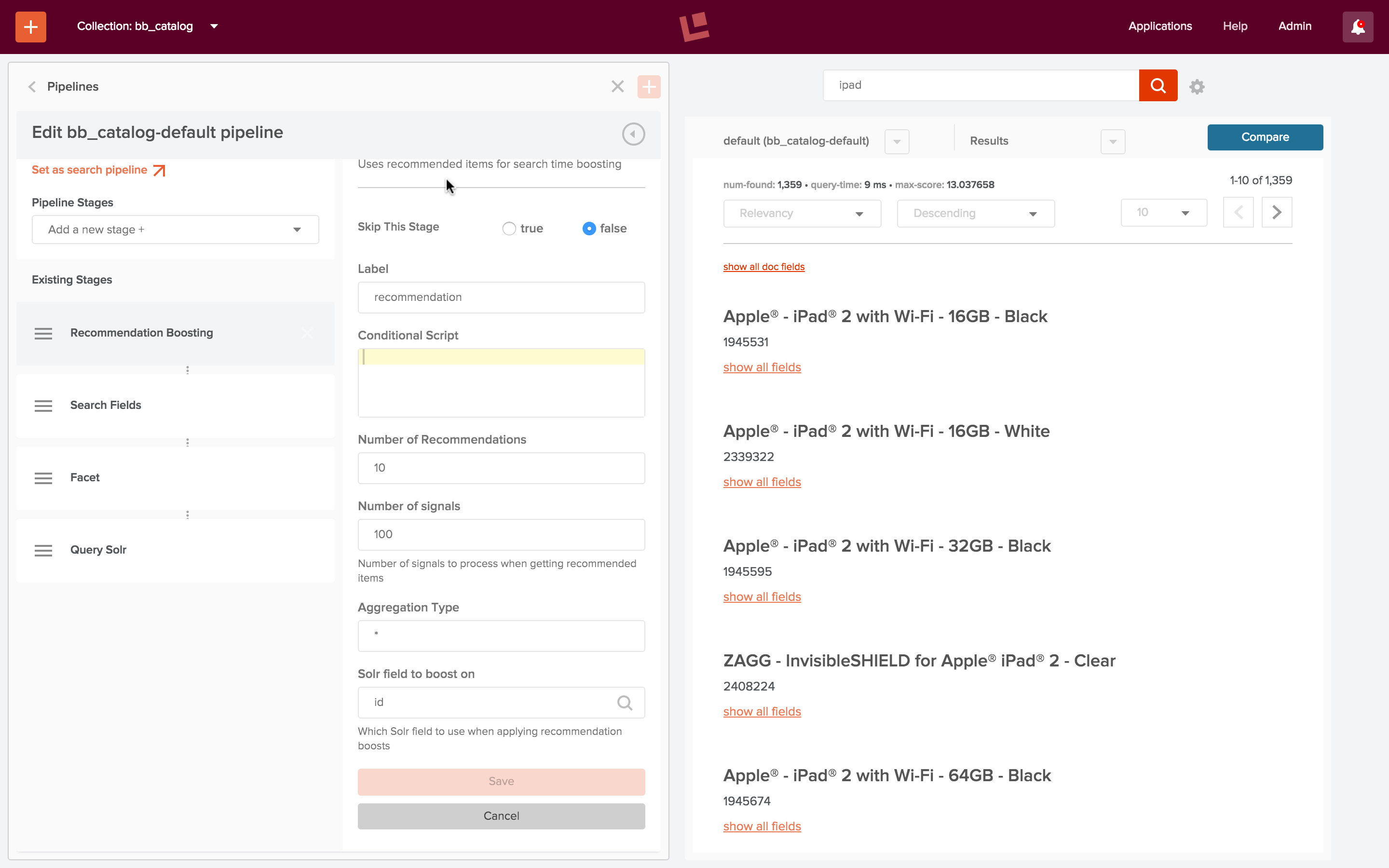
The edit pipeline panel on the left shows the updated query pipeline “bb_catalog-default” after adding a “Recommendations Boosting” stage. All parameter settings for this stage have been left at their default values. In particular, the recommendation boosts are applied to field “id”. The search panel on the right shows the updated results for the search query “ipad”. Now the three most relevant items are for Apple iPads. They are iPad 2 models because the click dataset used here is based on logfile data from 2011, and at that time, the iPad 2 was the most recent iPad on the market. There were more clicks on the 16GB iPads over the more expensive 32GB model, and for the color black over the color white.
Peeking Under the Hood
Of course, under the hood, Fusion is leveraging the awesome power of Solr. To see how this works, I show both the Fusion query and the JSON of the Solr response. To display the Fusion query, I go into the Search UI Configuration and change the “General” settings and check the set “Show Query URL” option. To see the Solr response in JSON format, I change the display control from “Results” to “JSON”.
The following screenshot shows the Fusion UI search display for “ipad”:
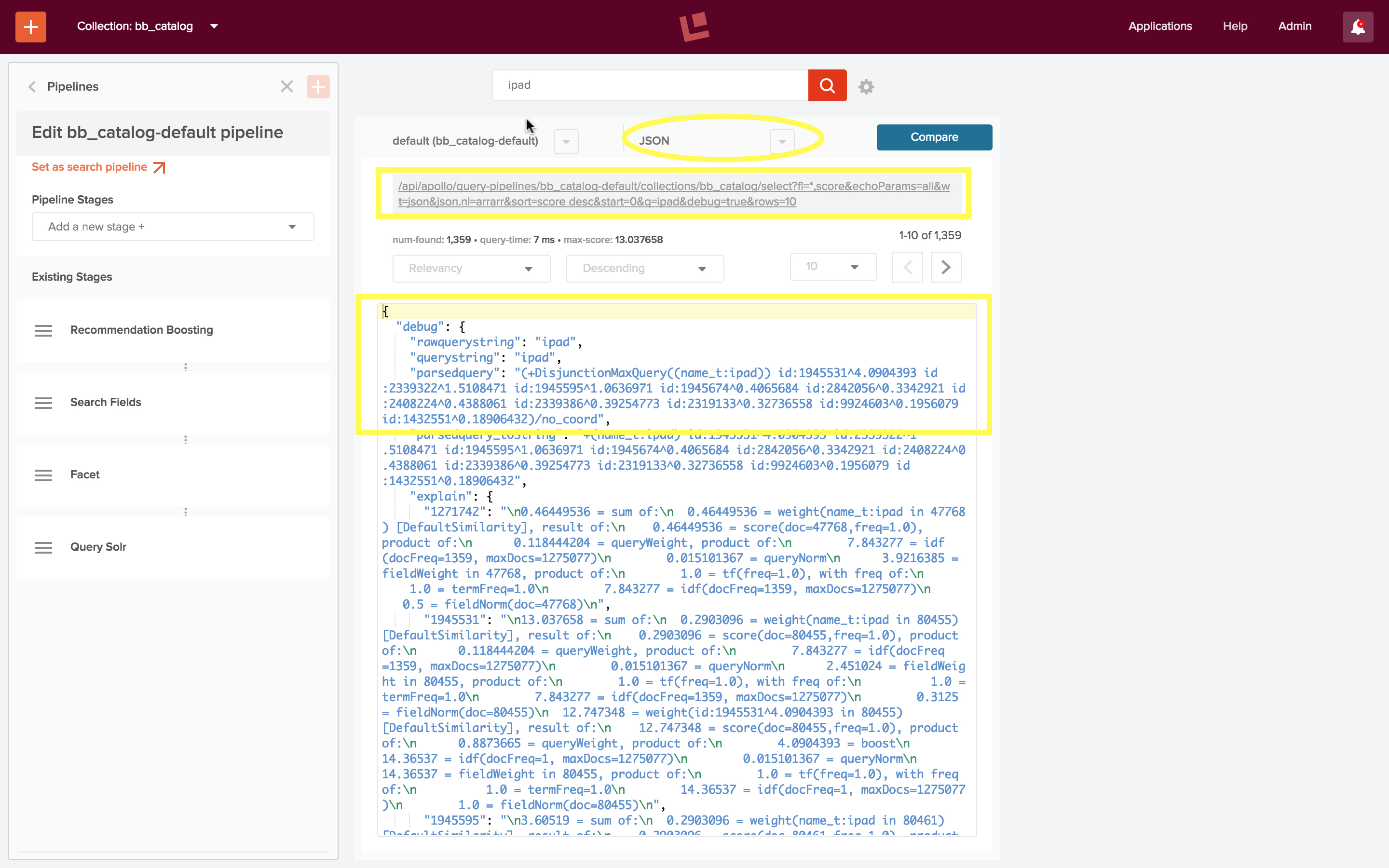
The query “ipad” entered via the Fusion UI search box is transformed into the following request sent to the Fusion REST-API:
/api/apollo/query-pipelines/bb_catalog-default/collections/bb_catalog/select?fl=*,score&echoParams=all&wt=json&json.nl=arrarr&sort&start=0&q=ipad&debug=true&rows=10
This request to the
"parsedquery": "(+DisjunctionMaxQuery((name_t:ipad)) id:1945531^4.0904393 id:2339322^1.5108471 id:1945595^1.0636971 id:1945674^0.4065684 id:2842056^0.3342921 id:2408224^0.4388061 id:2339386^0.39254773 id:2319133^0.32736558 id:9924603^0.1956079 id:1432551^0.18906432)/no_coord"
The outer part of this expression, “( … )/no_coord” is a reporting detail, indicating Solr’s “coord scoring” feature wasn’t used.
The enclosed expression consists of:
- The search: “+DisjunctionMaxQuery(name_t:ipad)”.
- A set of selective boosts to be applied to the search results
The field name “name_t” is supplied by the set of search fields specified by the Search Fields query stage. (Note: if no search fields are specified, the default search field name “text” is used. Since the documents in collection “bb_catalog” don’t contain a field named “text”, this stage must be configured with the appropriate set of search fields.)
The Recommendations Boosting stage was configured with the default parameters:
- Number of Recommendations: 10
- Number of Signals: 100
There are 10 documents boosted, with ids ( 1945531, 2339322, 1945595, 1945674, 2842056, 2408224, 2339386, 2319133, 9924603, 1432551 ). This set of 10 documents represents documents which had at least 100 clicks where “ipad” occurred in the user search query. The boost factor is a number derived from the aggregated signals by the Recommendation Boosting stage. If those documents contain the term “name_t:ipad”, then they will be boosted. If those documents don’t contain the term, then they won’t be returned by the Solr query.
To summarize: adding in the Recommendations Boosting stage results in a Solr query where selective boosts will be applied to 10 documents, based on clickstream information from an undifferentiated set of previous searches. The improvement in the quality of the search results is dramatic.
Even Better Search
Adding more processing to the query pipeline allows for user-specific and search-specific refinements. Like the Recommendations Boosting stage, these more complex query pipelines leverage Solr’s expressive query language, flexible scoring, and lightning fast search and indexing. Fusion query pipelines plus aggregated signals give you the tools you need to rapidly improve the user search experience.
LEARN MORE
Contact us today to learn how Lucidworks can help your team create powerful search and discovery applications for your customers and employees.