Lucene Tokenizer Example: Automatic Phrasing
This proposed automatic phrasing tokenization filter can deal with some of the problems associated with multi-term descriptions of singular things.

Search Engine Algorithm – Tokenization and Inverse Mapping
All search engines work by dividing textual content into lexical chunks or “tokens” and then “inverse mapping” those tokens back to the documents and to the text fields that they came from. The tokenization process is therefore key to how a search engine performs both in a functional and non-functional sense. One of the great design features of the Lucene search engine is the ability that it affords for customization of this process. Many problems arise from and can be solved by attending to the details of this analysis/tokenization process. Solr provides a schema layer on top of Lucene that enables different field types to be analyzed/tokenized in unique ways. This provides tremendous flexibility that can be used to solve a wide variety of search problems. The ‘toolkit’ is large and powerful but there are still some gaps waiting to be filled. The subject of this blog is a proposed tokenization filter called automatic phrasing that can be used to deal with some of the problems associated with multi-term descriptions of singular things. Although no one tool solves all problems, the beauty of the Lucene design is that many problems can be solved by different combinations of the same basic tools. Here is one more to consider.
Rationale: Syntax and Semantics – Units of Language and Search – Bags of Words vs. Bags of Things
Language is composed of more basic elements: symbols (letters, numerals and punctuation characters in Western Language, pictograms in Asian languages), words, phrases, sentences, paragraphs and so on. Each language has rules that define how these symbols and groups of symbols should be combined to form written language. These rules form the spelling and syntax or grammar of the language. Furthermore, in any communication process there is a sender and receiver(s). The sender constructs the communication (as I am doing in writing this blog) and the receiver parses the communication, hopefully to derive the meaning that the sender intended. The parsing process begins with lexical or phonemic analysis to extract the words followed by syntactic analysis to derive the logical structure of the sentence from its lexical units (nouns, verbs, adjectives, etc). Next is the semantic level where a great deal of other processes come into play so that the intended meaning of the communication is discerned (such as detecting sentiment in the face of sarcasm, where current software does a really great job – Yeah, Right!). Suffice it to say that there is more to language communication than simple detection of what words (aka ‘tokens’) are being used, yet that is basically what search engines do and this can explain some of the problems that we encounter when using them!
Lucene ships with several “Tokenizers” which get the analysis chain started (after any Character stream filters have done their job) both at index and query time. One of the simplest is the WhiteSpaceTokenizer which separates text streams into individual tokens separated by whitespace characters (space, tab, new line, etc). Other tokenizers such as the StandardTokenizer recognize other characters as token separators (punctuation characters mostly) and some are wise enough to recognize certain patterns that should not be split (such as internet and email addresses). However, all of these tokenizers share the characteristic that they operate at the syntactic or pre-semantic level. That is, they break the text up into what is called a “bag of words”. Without additional processing (which is provided in Lucene by the use of Token Filters), all subsequent mapping to form the inverted index is done on these individual tokens. This is not to say that all hope is lost at the semantic level because one of the things that the inverse map knows about is the relative position of words. This enables things like phrase matching and even more powerfully, fuzzy phrase matching. But even with these enhancements, the basic “bag of words” paradigm often causes a mismatch or disjunction between what users want the search engine to do and what it actually does.
This problem becomes evident when users construct queries with multiple words intending by this to improve the precision of their query. What most users don’t know is that the search engine is answering a different question than they are asking – it returns the documents that have the words that they entered (or synonyms if the application designers have provided this) which is sometimes not exactly “what” they are looking for. With a “bag of words” system, putting in more words often leads to less precision because there is more chance that the extra words will cause unintended “hits”- because they have other linguistic usages than the one that the user had in mind. The search engine knows nothing about this because usage is a semantic not a syntactic distinction.
Phrase Tokenization – moving towards Semantic Search of a “Bag of Things”
At the semantic level, language deals with “things” or entities and what those entities do or what is done to them (subject – object). An entity can sometimes be completely described or labeled with a single token but often more than one is required. Personal or place names are two familiar examples (e.g. John Smith, Los Angeles, Tierra del Fuego, New York City). In this case, lexical analysis or tokenization is too fine grained because there are many people named “John” and many named “Smith” but many fewer named “John Smith”. To solve this problem, some kind of grouping must be done to recognize the entity or “thing” from the group of tokens that describe it. Entity extractors are algorithmic engines that can use syntactic patterns like capitalization, regular expressions or learning algorithms to extract higher level language units. Another approach is to use a dictionary to define phrases that should be treated as unitary tokens for the purpose of search. Once we have extracted things rather than just words, we can more precisely map the user’s query to what they are looking for. When done at both index and query time, we can ensure that a search for a particular entity finds all mentions of that entity without including documents that have some but not all of the words that comprise the entity’s label.
Nuts and Bolts – Synonym Filtering and Automatic Phrasing
One way to deal with the problem is to detect multi-term phrases at analysis time and map them to single terms using the Lucene SynonymFilter. Lucene synonym expansions can also produce multi-term tokens as a side effect of “same as” mapping from a single term. The problem with side effects is they often have unintended consequences and such is sometimes the case here. The Synonym Filter should only be used to map terms or phrases that mean the same thing. When it is used to fix problems associated with tokenization of some multi-term phrases, it can run into trouble. The basic reason is that synonym filters are operating at a semantic level (meaning) and can therefore introduce unintended usages at the syntactic level (tokens) – (although there are problems with the way that Lucene parallelizes synonymous tokens). Words that can have meaning on their own but can also be used as modifiers (adjectives or adverbs) for other terms is where danger lurks. See this blog by John Berryman for an excellent summary of the basic issue.
Another way to deal with this problem is with the use of a tokenization filter that is intended to be used where a single entity or concept is described by more than one word. Such an “automatic phrasing token filter” can help to reduce false hits especially when parts of the phrase have other non-synonymous usages. An example is the phrase “income tax”. This is a tax on income and is therefore is a kind of tax but it is not the same thing as income. Depending on how it is set up, a synonym expansion from tax -> ‘income tax’ could allow hits on ‘income’ where it finds ‘tax’ and although these are related terms, they are not synonymous. The scoring or relevance algorithms don’t know about these subtleties (they work on the syntactic level of term frequency and inverse document frequency, i.e., “word salad math”) and can rank erroneous results higher than their semantic relevance would warrant.
The auto-phrasing token filter can solve this particular problem by specifying that ‘income tax’ should be treated as a single token which can then be mapped to ‘tax’ but not to ‘income’. The key here is that enforcing linguistic precision at the analysis level can lead to better precision at search time. Although in some cases, the Synonym Filter can do the same thing that an Automatic Phrasing Filter can, they are not intended for the same semantic purpose. When these filters are misused from a semantic sense, they introduce precision errors that lead to user frustration. The user is telling the search engine what they want. They are looking for specific things, not specific words. The more that we can do to redress this mismatch between tokens and things, the better the user experience will be.
Design Goals and Implementation
To inject the capability to detect and tokenize phrases, an Automatic Phrazing Token Filter was developed using the Lucene TokenFilter API. This enables it be plugged into any Lucene or Solr analysis chain. The filter uses a list of phrases – extracted from a text file with one phrase per line. The format of the phrases in the input should conform to the initial form of tokenization used in the analyzer (e.g. all lower case if a lower case filter is to be used before this one). It works by detecting sequences of tokens in the incoming token stream that match those that were extracted from the input file. When a complete match is encountered, it emits the entire phrase rather than the individual tokens that make up the phrase. If the match terminates before the expected phrase is completed, the tokens are replayed to the next downstream processing element as if the auto-phrase filter was not involved.
The filter works for any length phrase (so called n-grams) and can handle overlapping phrases (which is one thing that a single Synonym Filter cannot do). In Solr, the filter can be configured as part of a Field type analysis chain. It is recommended that this filter be placed in both the query and index analysis chains. The example described above would suggest that it should be placed before any Synonym expansion is done and before Stop Word filtering in case the phrase list contains common words that should otherwise be ignored when indexing and searching. At index time but not at query time, the flag includeTokens=”true” is added so that all tokens will be indexed, but only phrases in the query will be found (not the single words that comprise the phrase).
<fieldType name="text_en_auto" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="com.lucidworks.analysis.AutoPhrasingTokenFilterFactory"
phrases="autophrases.txt"
includeTokens="true" />
<filter class="solr.SynonymFilterFactory" expand="true" ignoreCase="true" synonyms="synonyms.txt"/>
<filter class="solr.WordDelimiterFilterFactory" catenateAll="1" catenateWords="1" catenateNumbers="1"/>
<filter class="solr.ASCIIFoldingFilterFactory"/>
<filter class="solr.StemmerOverrideFilterFactory" dictionary="stemdict.txt" ignoreCase="false"/>
<filter class="solr.KStemFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="com.lucidworks.analysis.AutoPhrasingTokenFilterFactory" phrases="autophrases.txt" />
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt"/>
<filter class="solr.WordDelimiterFilterFactory" catenateAll="1"/>
<filter class="solr.ASCIIFoldingFilterFactory"/>
<filter class="solr.StemmerOverrideFilterFactory" dictionary="stemdict.txt" ignoreCase="false"/>
<filter class="solr.KStemFilterFactory"/>
</analyzer>
</fieldType>
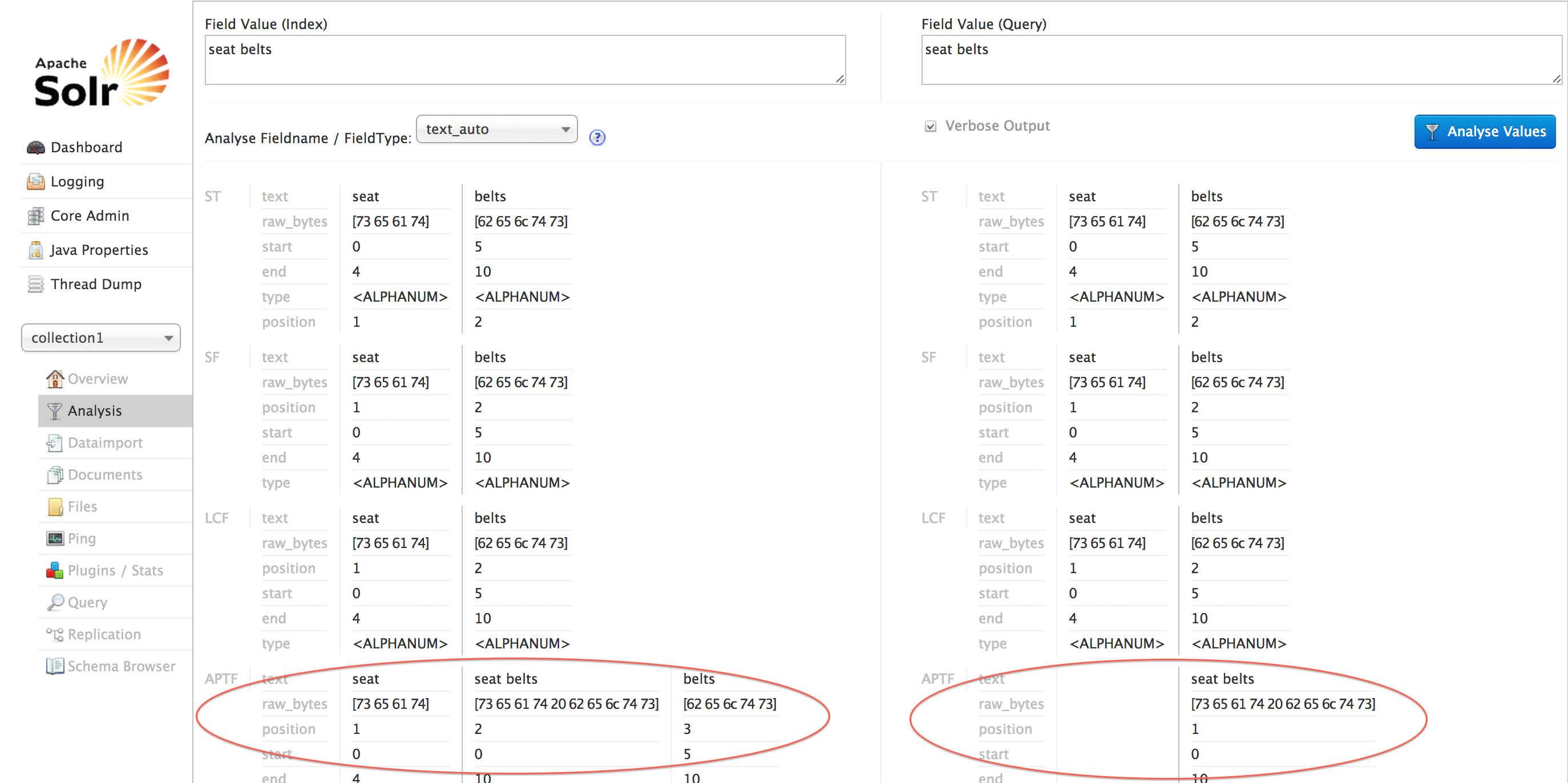
A simple testing of the filter can be done using the Solr Admin UI – select collection1, click the Analysis tab, select the text_auto field and put ‘seat belts’ into the index and query boxes, click ‘Analyze Values’. Note that on the index side, the token filter has exported ‘seat’, seat belts’ and ‘belts’. The query side just exported ‘seat belts’.
Auto phrasING token filter algorithm
The auto phrasing token filter uses a list of phrases that should be kept together as single tokens. As tokens are received by the filter, it keeps a partial phrase that matches the beginning of one or more phrases in this list. It will keep appending tokens to this ‘match’ phrase as long as at least one phrase in the list continues to match the newly appended tokens. If the match breaks before any phrase completes, the filter will replay the now unmatched tokens that it has collected. If a phrase match completes, that phrase will be emitted to the next filter in the chain. If a token does not match any of the leading terms in its phrase list, it will be passed on to the next filter unmolested.
This algorithm is fairly simple to implement and can handle overlapping phrases which is very difficult to do with the Synonym Filter (even given the arguments above that you would want to use Synonym Filter for this purpose). The source code for the filter is available on github.
BUT …. THERE’S A PROBLEM at query time – LUCENE-2605!
So far so good, in the Solr admin Analysis window it looks as if the auto phrasing token filter works as expected on both the index and query sides. But, there’s a problem in using this filter from the query side that is due to the behavior of the Lucene/Solr query parsers. When a query is parsed, whitespace in the query is ignored and each token is sent to the analyzer individually (LUCENE-2605). This prevents the auto phrasing filter from “seeing” across whitespace which prevents it from doing its job. This issue also affects the handling of multi-term synonyms on the query side and a few other things. It is a difficult problem to fix because the parser has to negotiate query tokens embedded with query syntax (operators such as ‘:’, ‘+’ and ‘-‘).
To solve this problem, auto phrasing needs to be done on the query side before the query is sent to the query parser. This can be accomplished by creating a QParserPlugin wrapper class (AutoPhrasingQParserPlugin) that filters the incoming query string “in place” by first protecting operators from manipulation, auto phrasing the query and then sending the filtered query to the Lucene/Solr query parsers. The AutoPhrasingQParserPlugin is included with the source distribution on github.
Test Case: solving a gnarly problem with multi-term synonyms – cross phrase matching
One of the pernicious problems that Solr has with phrases is cross matching of terms within phrases. For example, if I want to search for a specific thing that requires multiple terms to describe it (e.g. ‘seat cushion’) I don’t want hits on other things pertaining to car seats like ‘seat belts’ or ‘rear seat’. A ‘seat cushion’ is a thing (as is a seat belt) and I should be able to search for a particular thing without having to worry about other things that have some of the same words. However, if I search for ‘seat’ alone, I should see all of the things that are related to ‘seat’ (i.e. both belts and cushions). To solve this problem with the AutoPhrasingTokenFilter, we can set up the index analyzer to add multi-term phrases as tokens to the original token stream, but in the query analyzer to remove single tokens that are part of a phrase and only output the whole phrase as a token. This way, if I search for ‘seat’, I will find all of the documents that have the term ‘seat’ but if I search for ‘seat cushions’ I will only find documents that have this exact phrase. To do this, the index-time token filter is configured with ‘includeTokens=true’ as shown in the following fieldType definition in schema.xml. The query-time token filter (embedded in the AutoPhrasingQParserPlugin) keeps this flag at the default or ‘false’ state.
<fieldType name="text_autophrase" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true"
words="stopwords.txt"
enablePositionIncrements="true" />
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="com.lucidworks.analysis.AutoPhrasingTokenFilterFactory"
phrases="autophrases.txt" includeTokens="true" replaceWhitespaceWith="x" />
<filter class="solr.PorterStemFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true"
words="stopwords.txt" enablePositionIncrements="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.PorterStemFilterFactory"/>
</analyzer>
</fieldType>
The AutoPhrasingQParserPlugin is configured in the solrconfig.xml by creating a new /autophrase SearchHandler:
<requestHandler name="/autophrase" class="solr.SearchHandler">
<lst name="defaults">
<str name="echoParams">explicit</str>
<int name="rows">10</int>
<str name="df">text
<str name="defType">autophrasingParser</str>
</lst>
</requestHandler>
...
<queryParser name="autophrasingParser" class="com.lucidworks.analysis.AutoPhrasingQParserPlugin" >
<str name="phrases">autophrases.txt</str>
</queryParser>
The auto phrasing filter uses a text file with a list of phrases – autophrases.txt, one per line (similar to a stop words list) which should be put in the collection’s ‘conf’ directory:
air filter air bag air conditioning rear window rear seat rear spoiler rear tow bar seat belts seat cushions bucket seat timing belt fan belt front seat heated seat keyless entry keyless ignition electronic ignition
To test the auto phrasing filter, a small Solr collection was created in which the content contains some of the phrases in the auto phrase list:
<add>
<doc>
<field name="id">1</field>
<field name="name">Doc 1</field>
<field name="text">This has a rear window defroster and really cool bucket seats.</field>
</doc>
<doc>
<field name="id">2</field>
<field name="name">Doc 2</field>
<field name="text">This one has rear seat cushions and air conditioning – what a ride!</field>
</doc>
<doc>
<field name="id">3</field>
<field name="name">Doc 3</field>
<field name="text">This one has gold seat belts front and rear.</field>
</doc>
<doc>
<field name="id">4</field>
<field name="name">Doc 4</field>
<field name="text">This one has front and side air bags and a heated seat.
The fan belt never breaks.</field>
</doc>
<doc>
<field name="id">5</field>
Doc 5</field>
<field name="text">This one has big rear wheels and a seat cushion.
It doesn't have a timing belt.</field>
</doc>
</add>
This XML file was then indexed into the Solr collection:
curl "http://localhost:8983/solr/collection1/update?stream.file=/Users/tedsullivan/Desktop/Lucidworks/ResearchProjects/AutoPhrasing/solrtest/testdocs.xml&stream.contentType=text/xml;charset=utf-8&commit=true"
Now, if I search for text:seat or text:seat cushions, using the standard ‘/select’ Search Handler I get all five records back:
{
"responseHeader": {
"status": 0,
"QTime": 1,
"params": {
"indent": "true",
"q": "text:seat cushions",
"_": "1404250305148",
"wt": "json"
}
},
"response": {
"numFound": 5,
"start": 0,
"docs": [
{
"id": "2",
"name": "Doc 2",
"text": "This one has rear seat cushions and air
conditioning – what a ride!",
"_version_": 1472463103504416800
},
{
"id": "5",
"name": "Doc 5",
"text": "This one has big rear wheels and a seat cushion.
It doesn't have a timing belt.",
"_version_": 1472463103506514000
},
{
"id": "3",
"name": "Doc 3",
"text": "This one has gold seat belts front and rear.",
"_version_": 1472463103505465300
},
{
"id": "1",
"name": "Doc 1",
"text": "This has a rear window defroster and
really cool bucket seats.",
"_version_": 1472463103480299500
},
{
"id": "4",
"name": "Doc 4",
"text": "This one has front and side air bags and a
heated seat. The fan belt never breaks.",
"_version_": 1472463103506514000
}
]
}
}
However, if I search with text:seat cushions using the ‘/autophrase’ SearchHandler – I only get two! – because these are the only records that have this exact phrase – (or its stemmed version)
{
"responseHeader": {
"status": 0,
"QTime": 1,
"params": {
"indent": "true",
"q": "text_auto:seat cushions",
"_": "1404250987658",
"wt": "json"
}
},
"response": {
"numFound": 2,
"start": 0,
"docs": [
{
"id": "2",
"name": "Doc 2",
"text": "This one has rear seat cushions and
air conditioning – what a ride!",
"_version_": 1472463103504416800
},
{
"id": "5",
"name": "Doc 5",
"text": "This one has big rear wheels and a seat cushion.
It doesn't have a timing belt.",
"_version_": 1472463103506514000
}
]
}
}
Conclusion
So, we have achieved more precision by giving the search engine more precise information – just what users expect it to do – nice! Granted, this filter should not be used for any multi-term phrase (which would be impossible anyway since it requires an unending knowledge base), but can be very useful in cases where a user is looking for something specific and ‘noise’ hits abound due to noun-phrase overlaps.
LEARN MORE
Contact us today to learn how Lucidworks can help your team create powerful search and discovery applications for your customers and employees.