Alert! Alert! Alert! (Implementing Alerts in Lucidworks Fusion)
We live in a streaming world. Tweets, updates, documents, logs, etc. are flowing in all around us all the time, begging us to take action on everything that passes by. At the same time, our attention span remains finite, so we need a way to separate the proverbial wheat from the chaff, the noise from the signal, the garbage from the gold.
We’ve long known that search is great for helping rank what is important in content. Historians of information retrieval will also note an interest in document routing or document filtering to match documents as they flow in against standing queries from the very early days of search. However, until recently, with the massive increase in content being ingested by search engines, there hasn’t been much focus on the problem outside of some niche areas.
To address the needs of streaming data and alerting, our latest release of Lucidworks Fusion, now includes a fully integrated messaging service as well as pipeline stages for quickly and easily setting up alerts at both index time and search time. While systems like Percolator (for Elasticsearch) and Luwak (for Solr) use techniques to manage and execute standing (alerting) queries (by storing them as documents), our approach makes it possible to not only match incoming data streams against standing queries, but also include regular expressions, database lookups and other criteria for deciding whether something is alert-worthy or not. Since our alerting mechanism is fully integrated into our pipeline architecture, any upstream stage can affect how an alert message gets sent. Currently, Fusion ships with support for sending emails and slack messages, but support for other integrations will be coming soon.
Let’s take a closer look with a video demo at the functionality and then I’ll show you the underpinnings of how this works in Fusion. For this demo, I’m going to assume you have downloaded Fusion, unpacked it and logged into the admin console.
With the demo now out of the way, let’s dig into how the system works.
Building Blocks
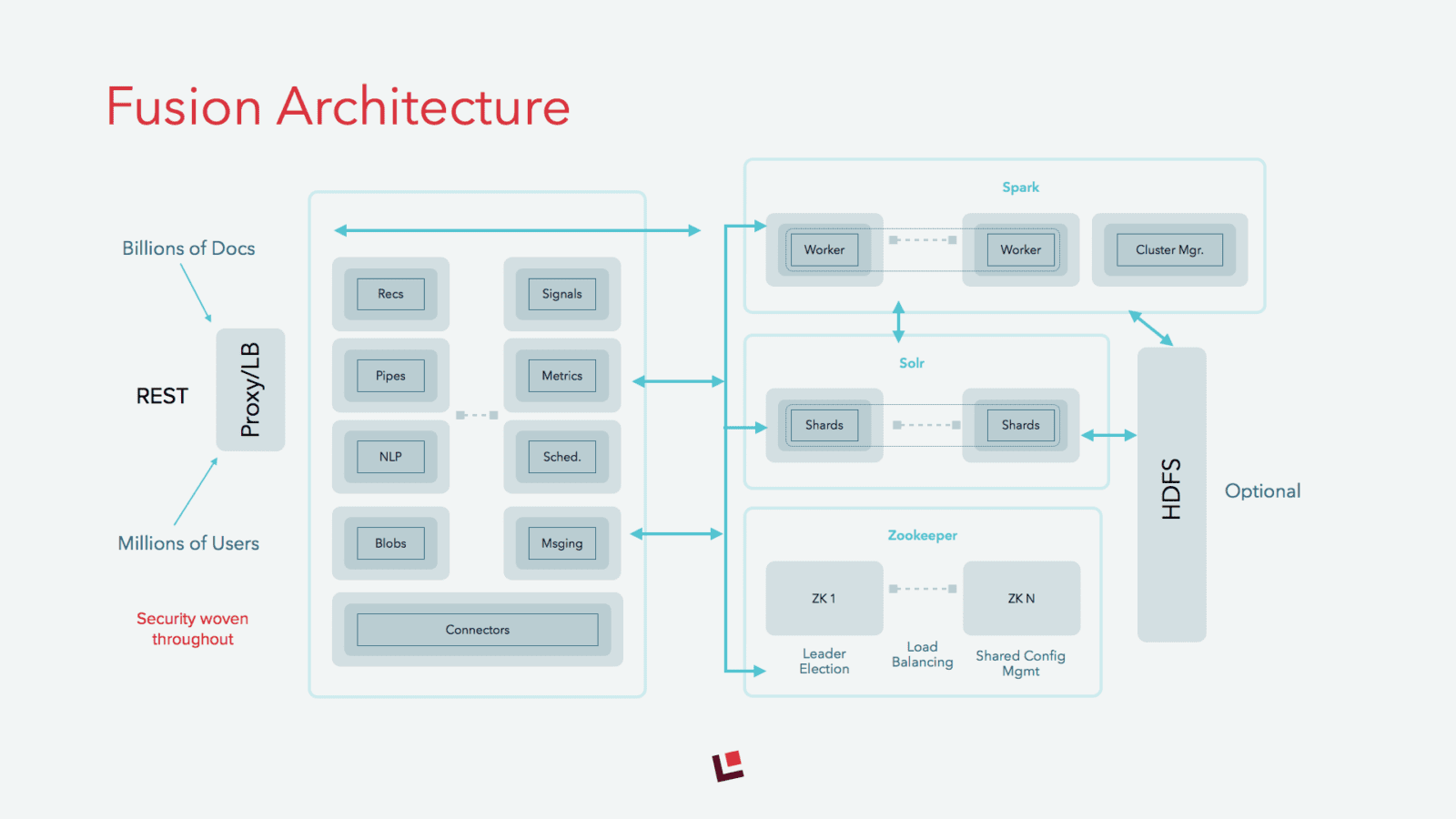
Fusion is made up of a number of services that work together to enable search, recommendations, large scale storage, alerting and other key services for sophisticated search apps. These services are deployed in almost all cases just as Solr is deployed (see the architecture diagram below for more detail). To enable alerting, we added a new service for delivering messages, called the Messaging Service, via one or more service providers as well as several new pipeline stages to enable alerting during both indexing and querying.
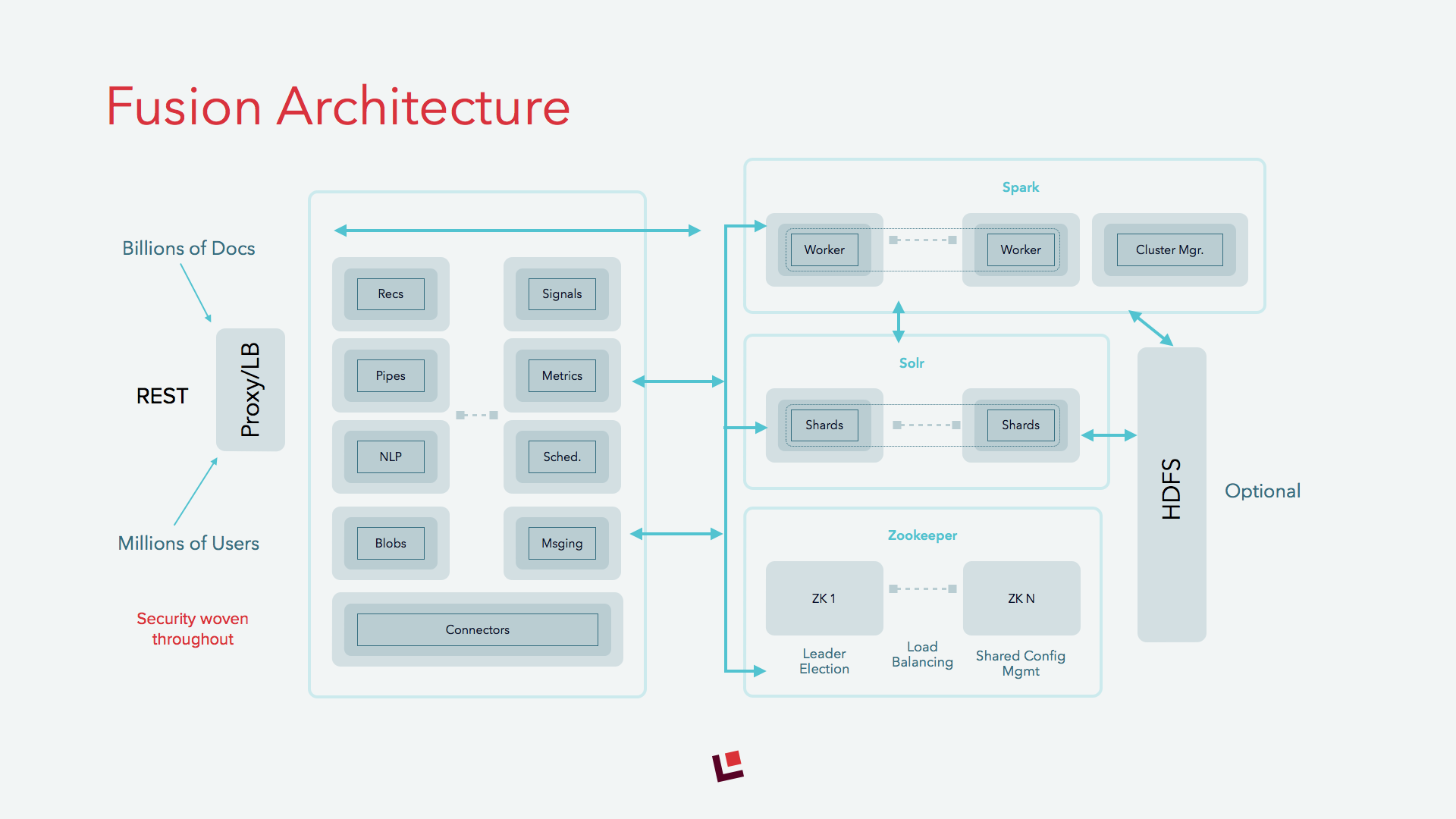
Messaging Service
The Messaging Service provides implementations to send messages of specific types (e.g. Slack, email) to one or more recipients. It also enables the scheduling of the sending of messages by integrating with Fusion’s built in scheduler. Furthermore, it can even save all messages to Solr so that they can be searched later. See the Appendix below on Message Service Configuration for more information on this and other configuration options.
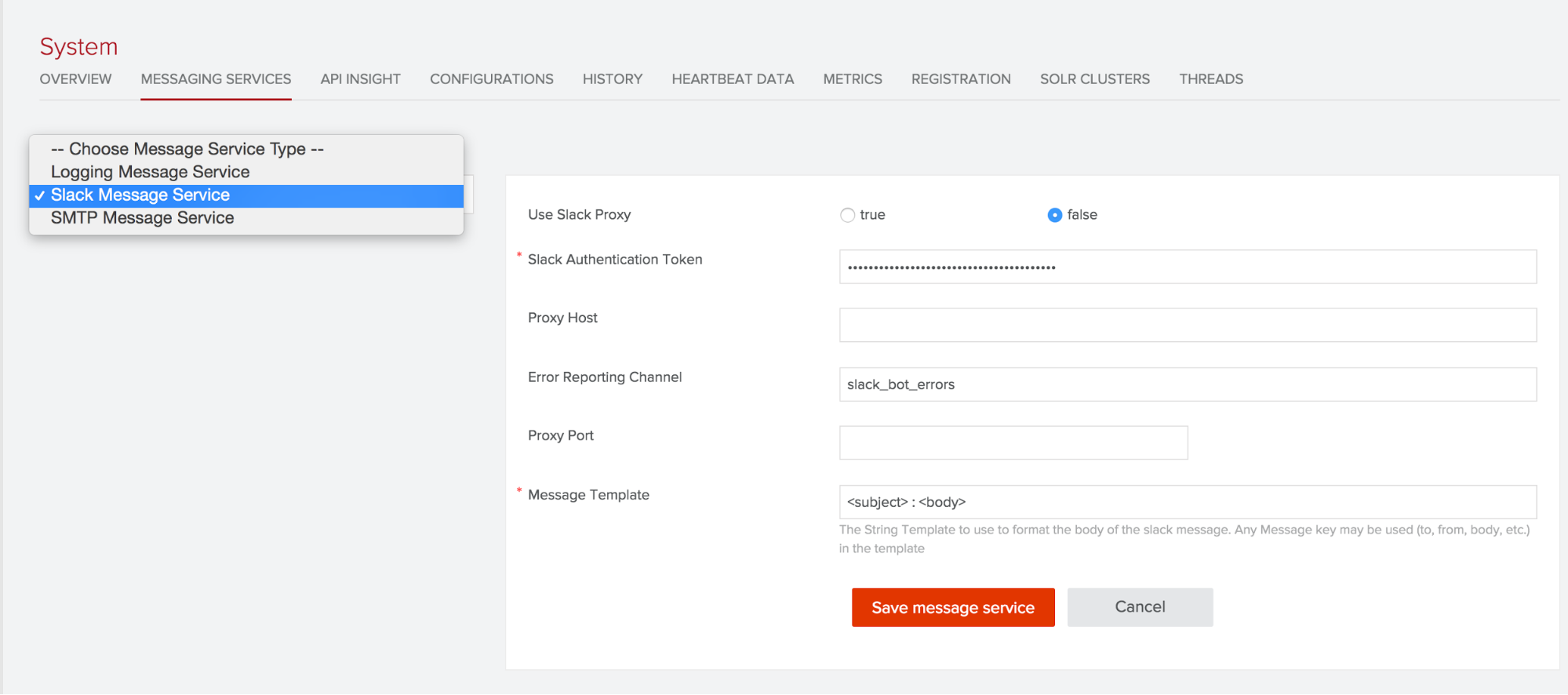
The Messaging Service currently supports three services: email, logging and Slack. To leverage the new messaging service, the service must first be setup. This can be done via the Fusion Admin (System->Messaging Services) UI, as in the screen grab below or via the API. Given a configured service instance (hint, the logging service is setup by default), we can then send messages either via a pipeline stage or via the APIs. We’ll cover the API approach in the next subsection and the pipeline approach in the section below on pipeline stages.
Sending a message via the Messaging API
The Messaging API supports the generic concept of a message, which consists of attributes like to, from, subject, body and other fields. See the Message Attributes section in the Appendix below for the full listing of attributes. Each Message Service implementation is responsible for interpreting what the attributes mean in the context of its system. For instance, “to” in the context of Slack means the channel to post the message to while to in the context of email (SMTP) means an email address. An example Slack message might look like:
[
{
"id": "this-is-my-id",
"type": "slack",
"subject": "Slackity Slack",
"body": "This is a slack message that I am sending to the #bottestchannel",
"to": ["bottestchannel"],
"from": "bob"
}
]
An example SMTP message might look like:
[
{
"id": "foo",
"type": "smtp",
"subject": "Fusion Developer Position",
"body": "Hi, I’m interested in the engineering posting listed at https://de.lucidworks.com/company/careers/",
"to": ["careers@lucidworks.com"],
"from": "bob@bob.com",
"messageServiceParams":{
"smtp.username": "robert.robertson@bob.com",
"smtp.password": "XXXXXXXX"
}
}
]
Depending on how the Message Service template is set up will determine what aspects of the message are sent. For instance, in the screen grab above, the Slack message service is setup to post the subject and the body as <subject>: <body> to Slack, as set by the Message Template attribute of the service.
Tying this all together, we can send the actual message by POSTing the JSON above to the send endpoint, as shown in the screen grab from the Postman REST client plugin for Chrome:
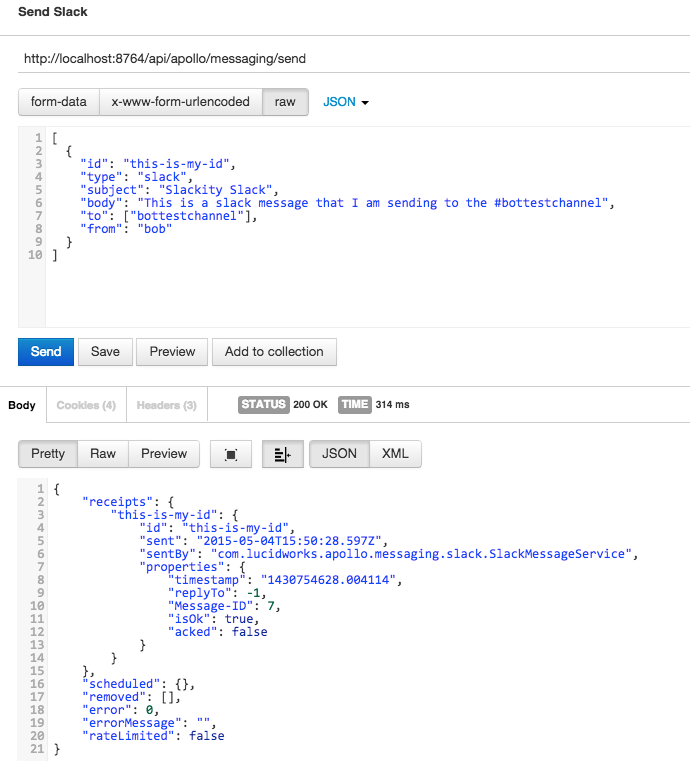
That’s it! You now have a full messaging service available to use as you see fit. Just like the rest of Fusion, you can secure access to the messaging service so that only appropriate applications and users can actually send messages. While the ability to send arbitrary messages is nice to have, the main use of the message service is as part of pipelines, so let’s take a look at how it works.
Pipeline Stages
Lucidworks Fusion ships with both index time and query time pipelines, enabling an easy way to manage dynamic document and query handling experiences. Each pipeline is made up of one or more stages and an application may have multiple pipelines setup to handle different scenarios, such as for testing different document scenarios, A/B testing and more.
In the context of alerting, Fusion 1.4 ships with several new pipelines stages:
- SMTP, Slack and Logging Messaging stages for delivering messages
- A new, lightweight index only conditional stage (called Set Property) that handles setting properties without using Javascript
As you saw in the video, combining these stages enables the ability to send alerting messages when certain conditions are met in the application. The keys to building more complex alerting systems is to know what values are available in the pipeline, which depends on whether it is a query pipeline or an index pipeline, both of which are outlined below.
Index Pipeline Data Structures
The index pipeline has available two key data structures: 1) the Pipeline Document and 2) The Pipeline Context. The former, as the name implies, is the actual document that was submitted by the application or the connector, while the latter is a request scoped key/value pair containing information placed in it by upstream stages. Context items are not automatically added to the document and they do not get sent to Solr upon indexing. The context is the main way to make flags and other values available to downstream stages. The best way to see what is in either the document or the pipeline context is to use the Logging Stage or the UI index pipeline preview page.
Query Pipeline Data Structures
The main difference between the index pipeline and the query pipeline is that the document is replaced by access to the request, the response and any headers that are passed in. As in indexing, the pipeline context is available and has the same semantics as indexing time, albeit with different data in it. To understand what’s available for data structures, please see the sections on Query Request Objects and Query Response Objects in the documentation.
Next Steps
If you’ve made it this far, you’ve seen a number of new features in action:
- A quick demo of setting up an alerting system in Fusion
- Sending arbitrary messages via Fusion’s messaging service
- Some details on how all of these things are built and where you can find more information
While we love what 1.4 brings to the table for alerting, we have a lot more planned. For instance, we are currently working on higher level APIs for alerting for those who don’t want to know the fine grained aspects of the pipeline stages as well as more messaging service integrations. It’s a bit too early to announce the latter just yet, but we can give a hint: it involves integration of several widely deployed messaging systems that will dramatically increase the types of messages you can send as well as add workflow options to those messages. We will also publish an SDK for the Messaging Service in the near future for those who wish to integrate their own messaging systems into Fusion. As always, if there is something you’d like to see in Fusion, feel free to contact us. Otherwise, happy alerting!
Appendix
Message Attributes
| Message Attribute | Description |
| id | An application specific id for tracking the message. Must be unique. If you are not sure what to use, then generate a UUID. |
| type | The type of message to send. As of 1.4, may be: slack, smtp or log. Send a GET to http://HOST:PORT/api/apollo/messaging/ to get a list of supported types. |
| to | One or more destinations for the message, as a list. |
| from | Who/what the message is from. |
| subject | The subject of the message. |
| body | The main body of the message. |
| schedule | If the message should be sent at a later time or on a recurring basis, pass in the schedule object. See the Scheduler documentation for more information. |
| messageServiceParams | Pass in a map of any message service specific parameters. For instance, the SMTP Message Service requires the application to pass in the SMTP user and password. |
Messaging Service Configuration
The Message Service as a system supports two attributes, which can be configured via the configurations API. The attributes are:
- rateLimit — The time, in milliseconds, to wait between sending messages on a per request basis. Please note, this does not synchronize throttling between different requests.
- storeAllMessages — Boolean flag indicating whether we should store/index all messages sent by the system. By default, only scheduled messages are stored, as they need to be retrieved by the scheduler at a later time. Storing all messages can be useful for auditing the system, but it will have an impact on the system storage requirements.
A word on String Templates
Woven throughout much of the system is integration with Terence Parr’s excellent String Template library, which we use in several places throughout to “fill in the blanks” of a template with actual values from the working system, such as the name of the document or the query. You can see this in action on the Messaging Service System setup, where we set the Message Template to be <subject>: <body>, but it is available in many other places as well. Just look for a mention of “String Template” and know that you can use them as appropriate.
LEARN MORE
Contact us today to learn how Lucidworks can help your team create powerful search and discovery applications for your customers and employees.