The ABCs of Learning to Rank
Learn how the machine learning method, learning to rank, helps you serve up results that are relevant and ranked by relevance.

Finding just the right thing when shopping can be exhausting. You can spend hours sifting through kind-of-related results only to give up in frustration. Maybe that’s why 79 percent of people who don’t like what they find will jump ship and search for another site.
There has to be a better way to serve customers with better website search.
And there is. Learning to rank is a machine learning method that helps you serve up relevant results and are … wait for it … ranked by that relevancy.
Search engines have been using learning to rank for almost two decades, so you may wonder why you haven’t heard more about it.
Like earlier machine learning processes, we needed more data and were using only a handful of features to rank on, including term frequency, inverse document frequency, and document length.
79 percent of people who don’t like what they find will jump ship and search for another site.
So people tuned by hand and iterated over and over. Now the data scientists are the exhausted ones instead of the shoppers. Exhaustion all around!
Today, we have larger training sets and better machine-learning capabilities.
But there are still challenges, notably around defining features; converting search catalog data into practical training sets; obtaining relevant judgments, including both explicit judgments by humans and implicit judgments based on search logs; and deciding which objective function to optimize for specific applications.
What Is Learning To Rank?
Learning to rank (LTR) is a class of algorithmic techniques that apply supervised machine learning to solve ranking problems in site search relevancy. In other words, it’s what orders query results. Done well, you have happy employees and customers; done poorly, at best, you have frustrations, and worse, they will never return.
To perform learning to rank, you need access to training data, user behaviors, user profiles, and a powerful search engine such as SOLR.
The training data for a learning-to-rank model consists of a list of results for a query and a relevance rating for each result concerning the query. Data scientists create this training data by examining results and deciding to include or exclude each result from the data set.
This vetted data set becomes a model’s gold standard to make predictions. We call it the ground truth and measure our predictions against it.
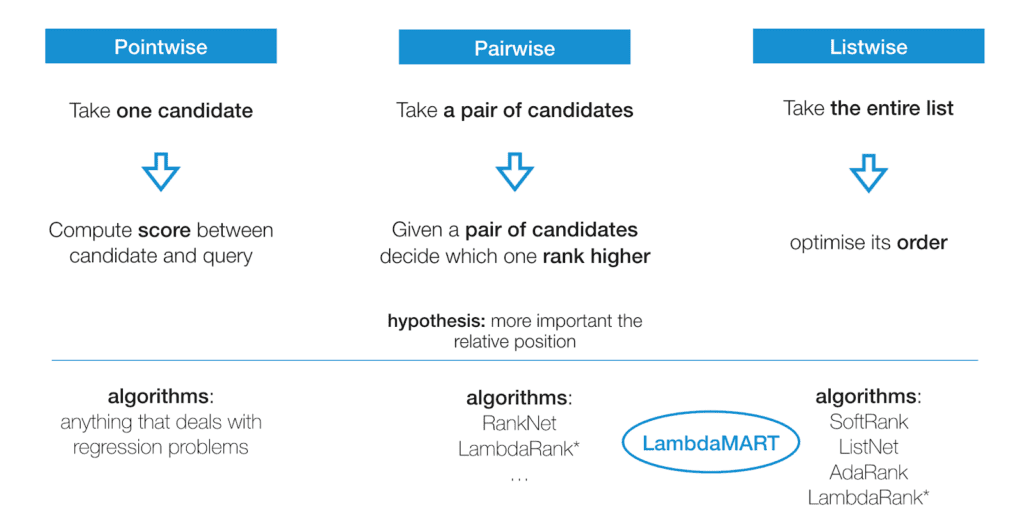
Pointwise, Pairwise, and Listwise LTR Approaches
The three major LTR approaches are pointwise, pairwise, and listwise.
Pointwise
Pointwise approaches look at a single document at a time using classification or regression to discover the best ranking for individual results.
Classification means putting similar documents in the same class–think of sorting fruit into piles by type; strawberries, blackberries, and blueberries belong in the berry pile (or class), while peaches, cherries, and plums belong in the stone fruit pile. (Video: Clustering vs Classification)
Regression means giving similar documents a similar function value to assign them similar preferences during the ranking procedure.
We give each document points for how well it fits during these processes. We add those up and sort the result list. Note here that each document score in the result list for the query is independent of any other document score, i.e. each document is considered a “point” for the ranking, independent of the other “points”
Pairwise
Pairwise approaches look at two documents together. They also use classification or regression — to decide which pair ranks higher.
We compare this higher-lower pair against the ground truth (the gold standard of hand-ranked data we discussed earlier) and adjust the ranking if it doesn’t match. The goal is to minimize the number of cases where the pair of results are in the wrong order relative to the ground truth (also called inversions).
Listwise
Listwise approaches decide on the optimal ordering of an entire list of documents. Ground truth lists are identified, and the machine uses that data to rank its list. Listwise approaches use probability models to minimize the ordering error., They can get quite complex compared to the pointwise or pairwise approaches.
Practical Challenges in Implementing Learning to Rank
You need to decide on the approach you want to take before you begin building your models.
Given the same data, is it better to train a single model across the board or multiple models for different data sets? How do well-known learning-to-rank models perform for the task?
You also need to:
- Decide the features you want to represent and choose reliable relevance judgments before creating your training dataset.
- Choose the model to use and the objective to be optimized.
In particular, the trained models should be able to generalize to:
- Previously unseen queries not in the training set and
- Previously unseen documents are to be ranked for queries in the training set.
- Additionally, increasing available training data improves model quality, but high-quality signals tend to be sparse, leading to a tradeoff between the quantity and quality of training data.
Understanding this tradeoff is crucial to generating training datasets.
Microsoft Develops Learning to Rank Algorithms
The options for learning-to-rank algorithms have expanded in the past few years, giving you more options to make practical decisions about your learning-to-rank project. These are fairly technical descriptions, so please don’t hesitate to reach out with questions.
RankNet, LambdaRank, and LambdaMART are popular learning-to-rank algorithms developed by researchers at Microsoft Research. All make use of pairwise ranking.
RankNet introduces the use of Gradient Descent (GD) to learn the learning function (update the weights or model parameters) for an LTR problem. Since the GD requires a gradient calculation, RankNet requires a model for which the output is a differentiable function — meaning that its derivative always exists at each point in its domain (they use neural networks, but it can be any other model with this property).
Learning to rank (LTR) is a class of algorithmic techniques that apply supervised machine learning to solve ranking problems in site search relevancy. In other words, it’s what orders query results. Done well, you have happy employees and customers; done poorly, at best, you have frustrations, and worse, they will never return.
RankNet is a pairwise approach and uses the GD to update the model parameters to minimize the cost (RankNet was presented with the Cross-Entropy cost function). This is like defining the force and the direction to apply when updating the positions of the two candidates (the one ranked higher up in the list and the other down but with the same force). As an optimization final decision, they speed up the process using the Mini-batch Stochastic Gradient Descent (computing all the weight updates for a given query before actually applying them).
LambdaRank is based on the idea that we can use the same direction (gradient estimated from the candidates pair, defined as lambda) for the swapping, but scaling it by the change of the final metric, such as nDCG, at each step (e.g., swapping the pair and immediately computing the nDCG delta). This is a very tractable approach since it supports any model (with differentiable output) with the ranking metric we want to optimize in our use case.
LambdaRank inspires LambdaMART, but it is based on a family of models called MART (Multiple Additive Regression Trees). These models exploit the Gradient Boosted Trees, a cascade of trees in which the gradients are computed after each new tree, to estimate the direction that minimizes the loss function (the contribution of the next tree will scale that). In other words, each tree contributes to a gradient step in the direction that minimizes the loss function. The ensemble of these trees is the final model (i.e., Gradient Boosting Trees). LambdaMART uses this ensemble but replaces that gradient with the lambda (gradient computed given the candidate pairs) presented in LambdaRank.
This algorithm is often considered pairwise since the lambda considers pairs of candidates. Still, it has to know the entire ranked list (i.e., scaling the gradient by a factor of the nDCG metric that considers the whole list) – with an apparent characteristic of a Listwise approach.
Learning to Rank Applications in the Industry
Wayfair
In a post on their tech blog, Wayfair talks about how they used learning to rank for keyword searches. Wayfair is a public e-commerce company that sells home goods. Search technology is, therefore, crucial to the customer experience. Wayfair addresses this problem by using LTR coupled with machine learning and natural language processing (NLP) techniques to understand a customer’s intent and deliver appropriate results.
The diagram below shows Wayfair’s search system. They extract text information from different datasets, including user reviews, product catalogs, and clickstreams. Next, they use various NLP techniques to extract entities, analyze sentiments, and transform data.
Wayfair then feeds the results into its in-house Query Intent Engine to identify customer intent on a large portion of incoming queries and to send many users directly to the right page with filtered results. When the Intent Engine can’t make a direct match, they use the keyword search model. This is where LTR comes to the rescue.
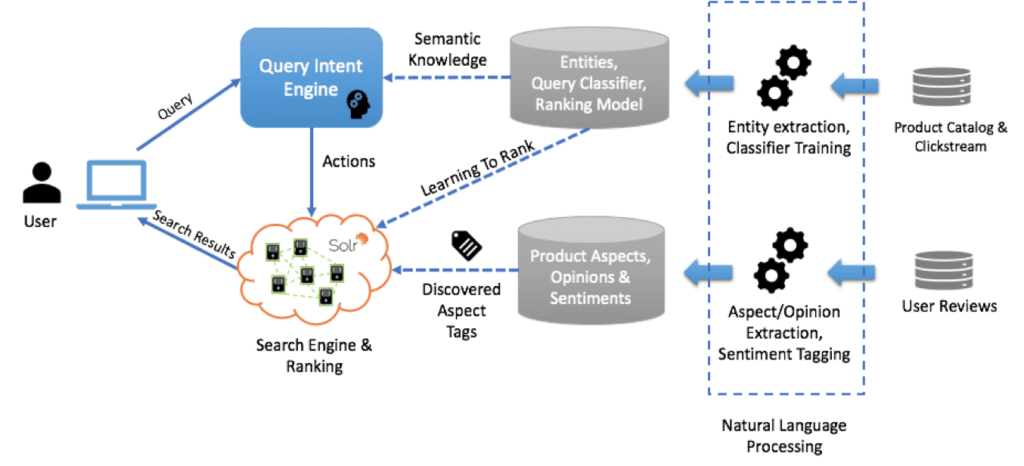
In its keyword search approach, Wayfair issues the incoming search to produce results across its entire product catalog. Under the hood, they have trained a LTR model (used by Solr) to assign a relevance score to the individual products returned for the incoming query. Wayfair then trains its LTR model on clickstream data and search logs to predict the score for each product. These scores ultimately will determine the position of a product in search results. The model improves itself over time as it receives feedback from the new data generated daily.
The results show that this model has improved Wayfair’s conversion rate of customer queries
Slack
The Search, Learning, and Intelligence team at Slack also used LTR to improve the quality of Slack’s search results. More specifically, they built a personalized relevance sort and a section search called top results, which presents personalized and recent results in one view. Note here that a search inside Slack differs from a typical website search because each Slack user has access to a unique set of documents, and what’s relevant at the time frequently changes.
Slack provides two strategies for searching: recent and relevant. Recent search finds the messages that match all terms and then presents them in reverse chronological order. Relevant search relaxes the age constraint and considers how well the document matches the query terms.
Slack employees noticed that relevant search performed slightly worse than recent search according to the website search quality metrics, such as the number of clicks per search and the click-through rate of the website search results in the top several positions.
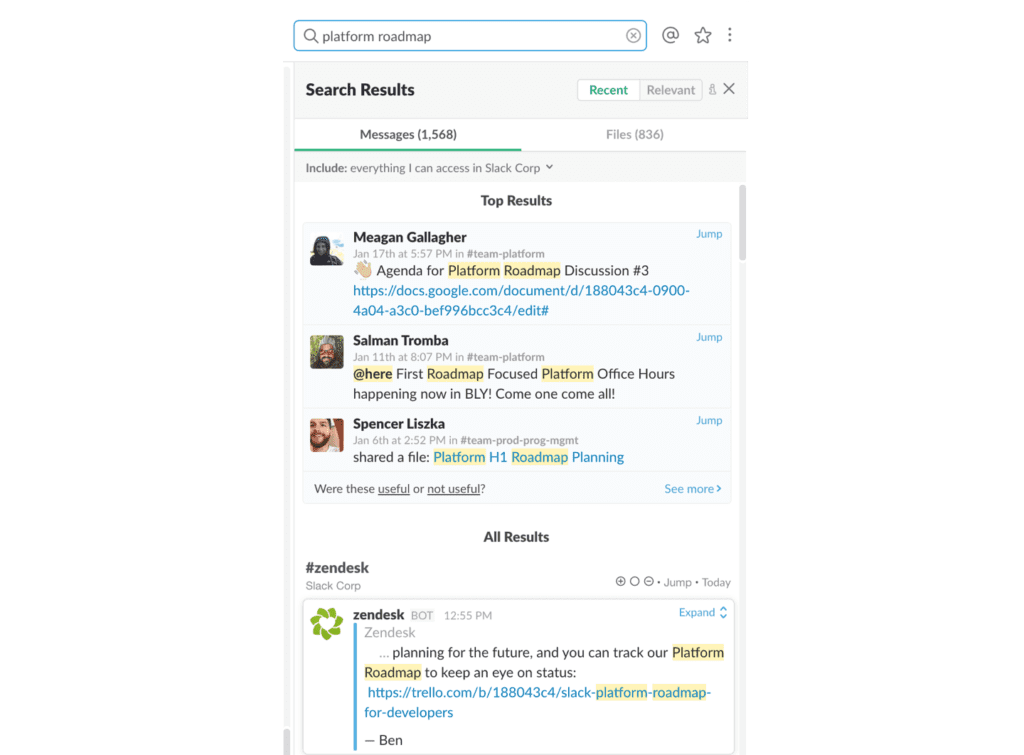
Incorporating additional features would improve the ranking of results for relevant searches. To accomplish this, the Slack team uses a two-stage approach: (1) leveraging Solr’s custom sorting functionality to retrieve a set of messages ranked by only the select few features that were easy for Solr to compute, and (2) re-ranking those messages in the application layer according to the complete set of features, weighted appropriately. In building a model to determine these weights, the first task was to build a labeled training set. The Slack team used the pairwise technique discussed earlier to judge the relative relevance of documents within a single search using clicks.
This approach has been incorporated into Slack’s top results module, which shows a significant increase in website search sessions per user, an increase in clicks per search, and a reduction in searches per session. This indicates that Slack users can find what they are looking for faster.
Skyscanner
Skyscanner, a travel app where users search for flights and book an ideal trip uses LTR for flight itinerary search.
The site search technology involves prices, available times, stopover flights, travel windows, and more. Skyscanner aims to help users find the best flights for their circumstances.
The Skyscanner team translates the problem of ranking items into a binary regression. They label their data about items users think of as relevant to their queries as positive examples and data about items that users think of as not relevant to their queries as negative examples. Then, they use such data to train a machine learning model to predict the probability that a user will find a flight relevant to the website search query. More specifically, relevance is defined as the commitment click-through to the airline and travel agent’s website to purchase it since this requires many action steps from the user.
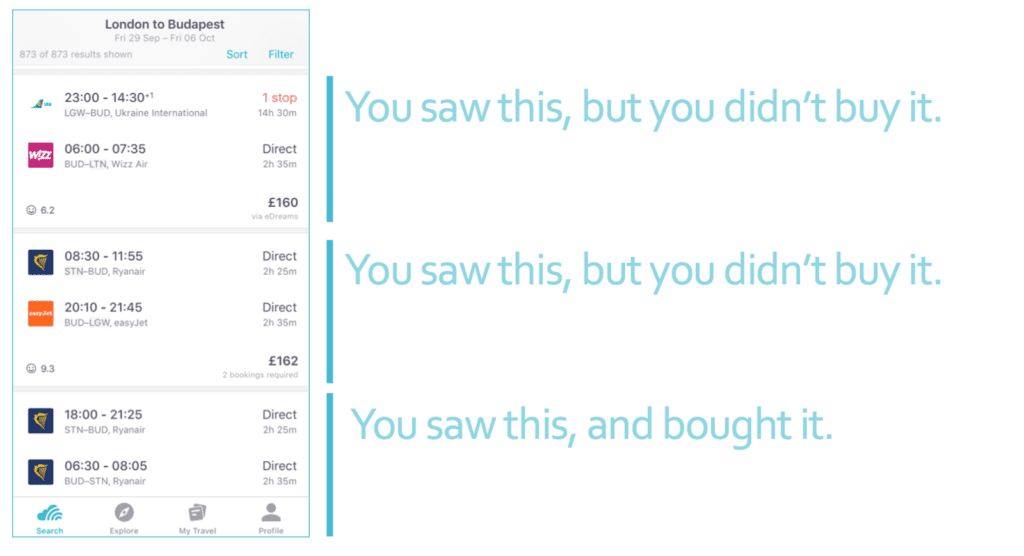
After applying LTR to the data, they do offline and online experiments to test the model performance. In particular, they compare users who were given recommendations using machine learning, those who were given recommendations using a heuristic that took only price and duration into account, and those who were not given any recommendations. The results indicate that the LTR model with machine learning leads to better conversion rates – how often users would purchase a flight recommended by Skyscanner’s model.
These examples show how LTR approaches can improve site search for users.
All three LTR approaches compare unclassified data to a golden truth data set to determine how relevant website search results are. As data sets continue to grow, so will the accuracy of LTR.
Further reading looking at Learning to Rank and machine learning on search and a video explaining how LTR is used for ranking search results.
LEARN MORE
Contact us today to learn how Lucidworks can help your team create powerful search and discovery applications for your customers and employees.